 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Second DISPLACE Challenge : DIarization of SPeaker and LAnguage in Conversational Environments
Jun 13, 2024



The DIarization of SPeaker and LAnguage in Conversational Environments (DISPLACE) 2024 challenge is the second in the series of DISPLACE challenges, which involves tasks of speaker diarization (SD) and language diarization (LD) on a challenging multilingual conversational speech dataset. In the DISPLACE 2024 challenge, we also introduced the task of automatic speech recognition (ASR) on this dataset. The dataset containing 158 hours of speech, consisting of both supervised and unsupervised mono-channel far-field recordings, was released for LD and SD tracks. Further, 12 hours of close-field mono-channel recordings were provided for the ASR track conducted on 5 Indian languages. The details of the dataset, baseline systems and the leader board results are highlighted in this paper. We have also compared our baseline models and the team's performances on evaluation data of DISPLACE-2023 to emphasize the advancements made in this second version of the challenge.
COVID-19 Patient Detection from Telephone Quality Speech Data
Nov 09, 2020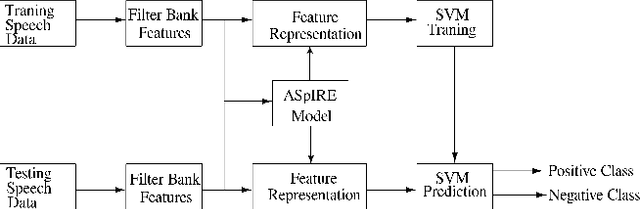
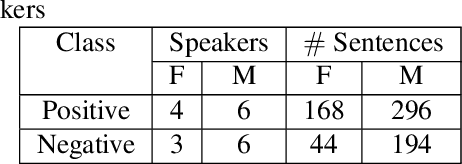
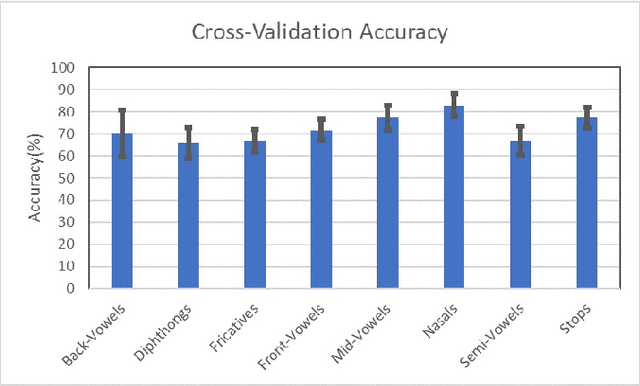
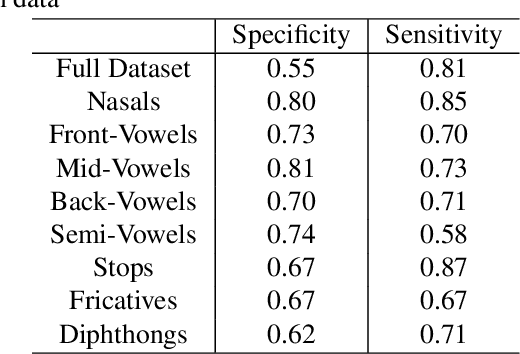
In this paper, we try to investigate the presence of cues about the COVID-19 disease in the speech data. We use an approach that is similar to speaker recognition. Each sentence is represented as super vectors of short term Mel filter bank features for each phoneme. These features are used to learn a two-class classifier to separate the COVID-19 speech from normal. Experiments on a small dataset collected from YouTube videos show that an SVM classifier on this dataset is able to achieve an accuracy of 88.6% and an F1-Score of 92.7%. Further investigation reveals that some phone classes, such as nasals, stops, and mid vowels can distinguish the two classes better than the others.
NISP: A Multi-lingual Multi-accent Dataset for Speaker Profiling
Jul 12, 2020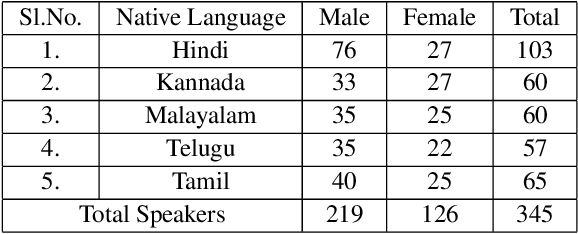
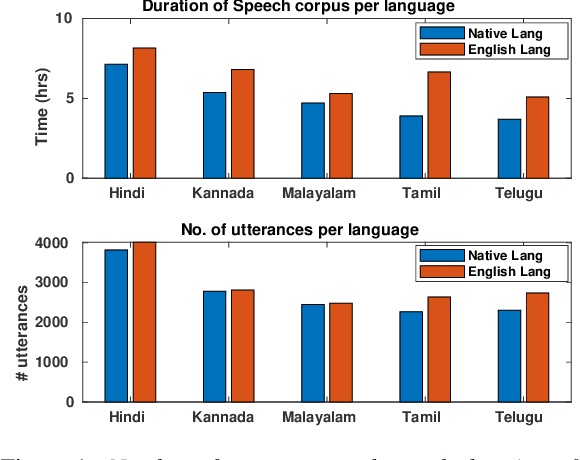
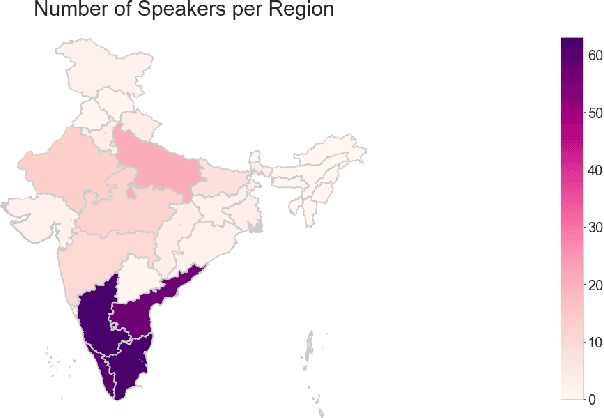
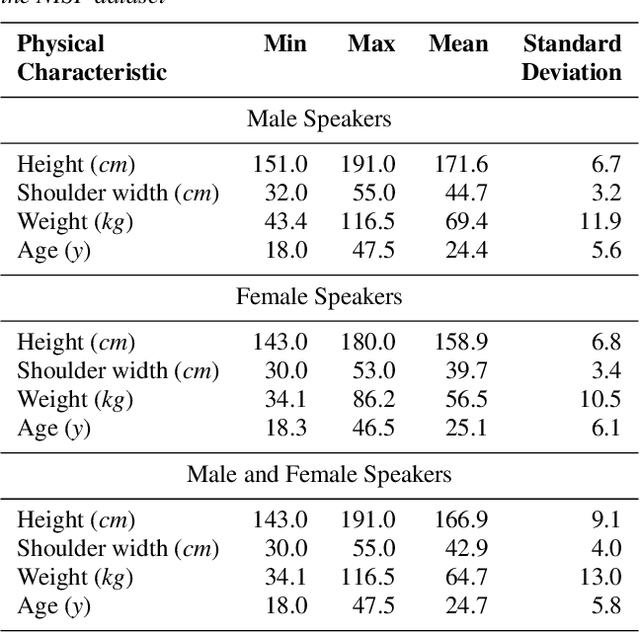
Many commercial and forensic applications of speech demand the extraction of information about the speaker characteristics, which falls into the broad category of speaker profiling. The speaker characteristics needed for profiling include physical traits of the speaker like height, age, and gender of the speaker along with the native language of the speaker. Many of the datasets available have only partial information for speaker profiling. In this paper, we attempt to overcome this limitation by developing a new dataset which has speech data from five different Indian languages along with English. The metadata information for speaker profiling applications like linguistic information, regional information, and physical characteristics of a speaker are also collected. We call this dataset as NITK-IISc Multilingual Multi-accent Speaker Profiling (NISP) dataset. The description of the dataset, potential applications, and baseline results for speaker profiling on this dataset are provided in this paper.