 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLARITY: A Framework and Benchmark for Conversational Language Ambiguity and Unanswerability in Interactive NL2SQL Systems
Apr 24, 2026NL2SQL systems deployed in industry settings often encounter ambiguous or unanswerable queries, particularly in interactive scenarios with incomplete user clarification. Existing benchmarks typically assume a single source of ambiguity and rely on user interaction for resolution, overlooking realistic failure modes. We introduce Clarity, a framework for automatically generating an NL2SQL benchmark with multi-faceted ambiguities and diverse user behaviors across both single- and multi-turn settings. Using a constraint-driven pipeline, Clarity transforms executable SQL into ambiguous queries, augmented with grounded conversational continuations and schema-level metadata. Empirical evaluation on Spider and BIRD shows that leading NL2SQL systems, including those based on strong LLMs, suffer significant performance degradation under multi-faceted ambiguity. While these systems often detect ambiguity, they struggle to accurately localize and resolve the underlying schema-level sources. Our results highlight the need for more robust ambiguity detection and resolution in industry-grade NL2SQL systems.
Learning to Multi-Task Learn for Better Neural Machine Translation
Jan 10, 2020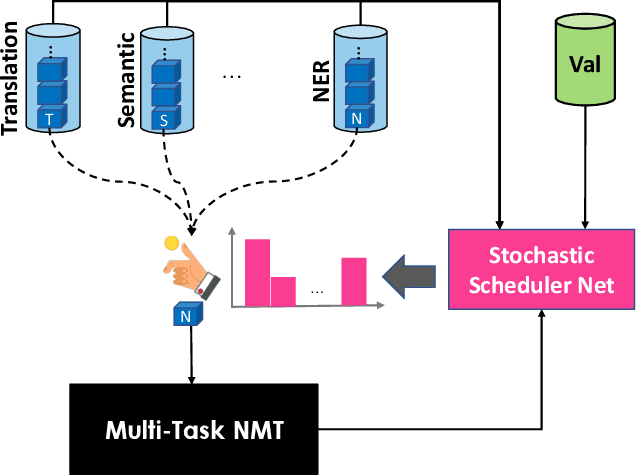
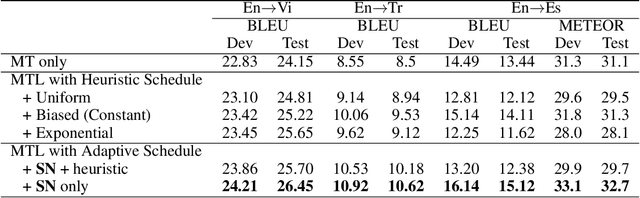
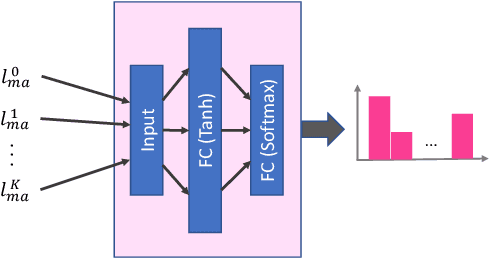
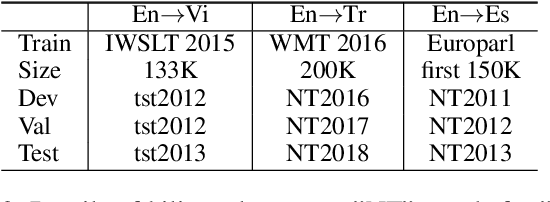
Scarcity of parallel sentence pairs is a major challenge for training high quality neural machine translation (NMT) models in bilingually low-resource scenarios, as NMT is data-hungry. Multi-task learning is an elegant approach to inject linguistic-related inductive biases into NMT, using auxiliary syntactic and semantic tasks, to improve generalisation. The challenge, however, is to devise effective training schedules, prescribing when to make use of the auxiliary tasks during the training process to fill the knowledge gaps of the main translation task, a setting referred to as biased-MTL. Current approaches for the training schedule are based on hand-engineering heuristics, whose effectiveness vary in different MTL settings. We propose a novel framework for learning the training schedule, ie learning to multi-task learn, for the MTL setting of interest. We formulate the training schedule as a Markov decision process which paves the way to employ policy learning methods to learn the scheduling policy. We effectively and efficiently learn the training schedule policy within the imitation learning framework using an oracle policy algorithm that dynamically sets the importance weights of auxiliary tasks based on their contributions to the generalisability of the main NMT task. Experiments on low-resource NMT settings show the resulting automatically learned training schedulers are competitive with the best heuristics, and lead to up to +1.1 BLEU score improvements.
Neural Machine Translation for Bilingually Scarce Scenarios: A Deep Multi-task Learning Approach
May 11, 2018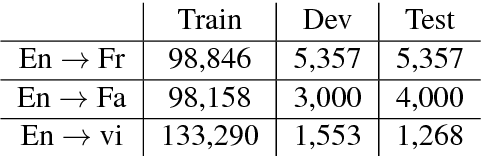
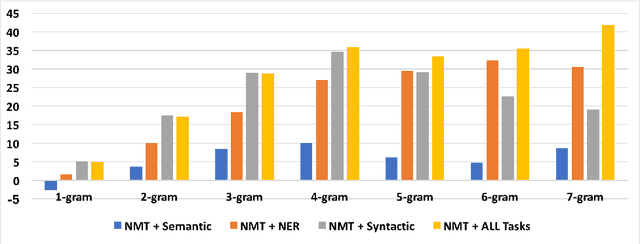
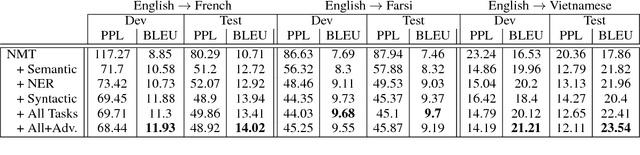
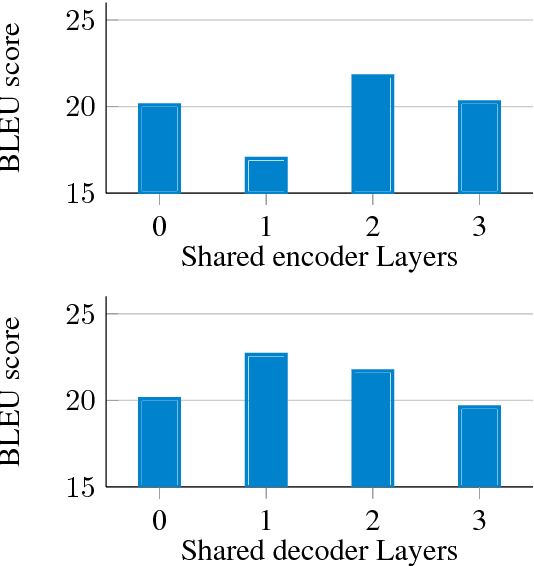
Neural machine translation requires large amounts of parallel training text to learn a reasonable-quality translation model. This is particularly inconvenient for language pairs for which enough parallel text is not available. In this paper, we use monolingual linguistic resources in the source side to address this challenging problem based on a multi-task learning approach. More specifically, we scaffold the machine translation task on auxiliary tasks including semantic parsing, syntactic parsing, and named-entity recognition. This effectively injects semantic and/or syntactic knowledge into the translation model, which would otherwise require a large amount of training bitext. We empirically evaluate and show the effectiveness of our multi-task learning approach on three translation tasks: English-to-French, English-to-Farsi, and English-to-Vietnamese.
Incorporating Syntactic Uncertainty in Neural Machine Translation with Forest-to-Sequence Model
Nov 24, 2017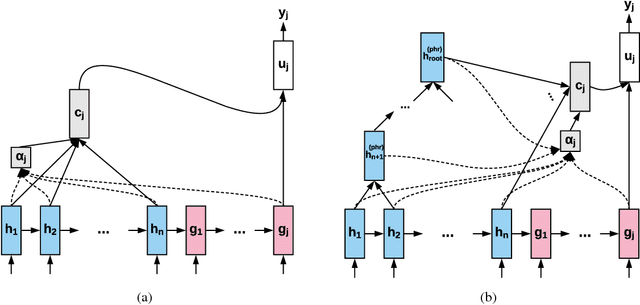
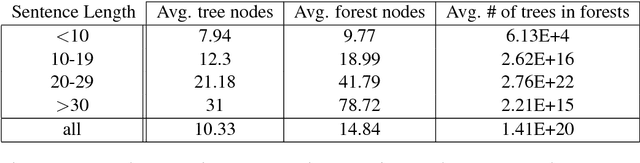
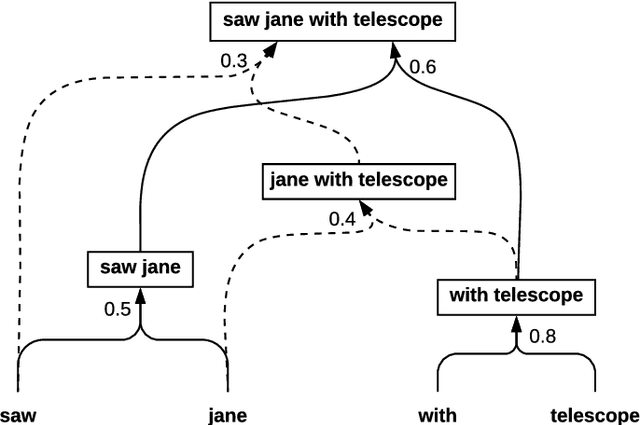
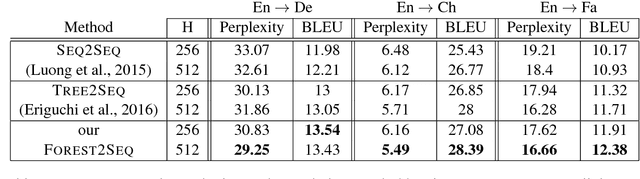
Incorporating syntactic information in Neural Machine Translation models is a method to compensate their requirement for a large amount of parallel training text, especially for low-resource language pairs. Previous works on using syntactic information provided by (inevitably error-prone) parsers has been promising. In this paper, we propose a forest-to-sequence Attentional Neural Machine Translation model to make use of exponentially many parse trees of the source sentence to compensate for the parser errors. Our method represents the collection of parse trees as a packed forest, and learns a neural attentional transduction model from the forest to the target sentence. Experiments on English to German, Chinese and Persian translation show the superiority of our method over the tree-to-sequence and vanilla sequence-to-sequence neural translation models.