 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuery Expansion Using Contextual Clue Sampling with Language Models
Oct 13, 2022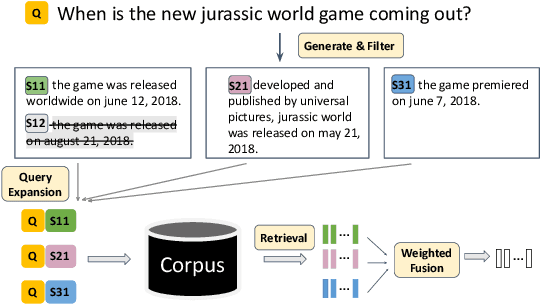
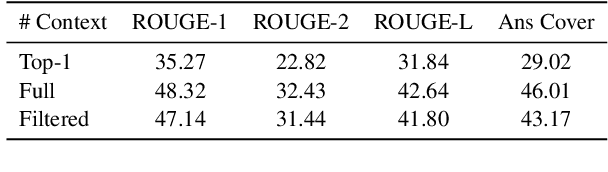
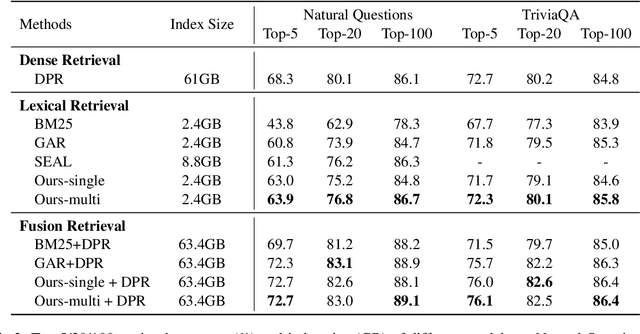
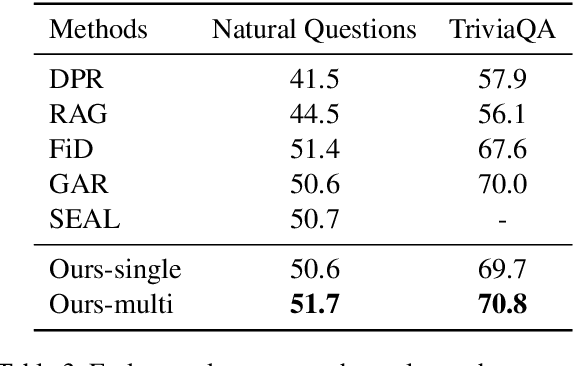
Query expansion is an effective approach for mitigating vocabulary mismatch between queries and documents in information retrieval. One recent line of research uses language models to generate query-related contexts for expansion. Along this line, we argue that expansion terms from these contexts should balance two key aspects: diversity and relevance. The obvious way to increase diversity is to sample multiple contexts from the language model. However, this comes at the cost of relevance, because there is a well-known tendency of models to hallucinate incorrect or irrelevant contexts. To balance these two considerations, we propose a combination of an effective filtering strategy and fusion of the retrieved documents based on the generation probability of each context. Our lexical matching based approach achieves a similar top-5/top-20 retrieval accuracy and higher top-100 accuracy compared with the well-established dense retrieval model DPR, while reducing the index size by more than 96%. For end-to-end QA, the reader model also benefits from our method and achieves the highest Exact-Match score against several competitive baselines.
ReFactorGNNs: Revisiting Factorisation-based Models from a Message-Passing Perspective
Jul 21, 2022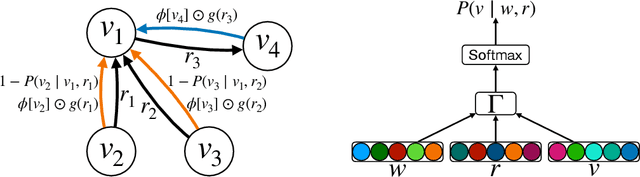

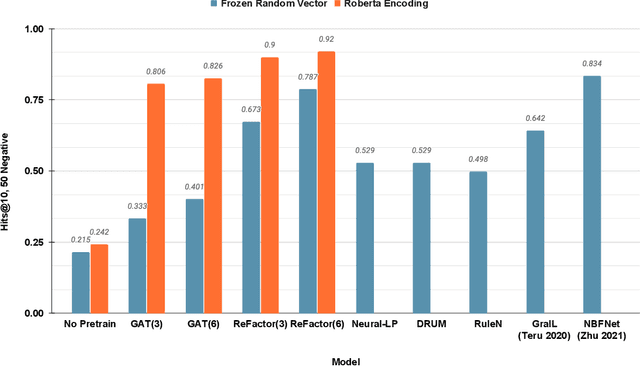

Factorisation-based Models (FMs), such as DistMult, have enjoyed enduring success for Knowledge Graph Completion (KGC) tasks, often outperforming Graph Neural Networks (GNNs). However, unlike GNNs, FMs struggle to incorporate node features and to generalise to unseen nodes in inductive settings. Our work bridges the gap between FMs and GNNs by proposing ReFactorGNNs. This new architecture draws upon both modelling paradigms, which previously were largely thought of as disjoint. Concretely, using a message-passing formalism, we show how FMs can be cast as GNNs by reformulating the gradient descent procedure as message-passing operations, which forms the basis of our ReFactorGNNs. Across a multitude of well-established KGC benchmarks, our ReFactorGNNs achieve comparable transductive performance to FMs, and state-of-the-art inductive performance while using an order of magnitude fewer parameters.
MedDistant19: A Challenging Benchmark for Distantly Supervised Biomedical Relation Extraction
Apr 10, 2022

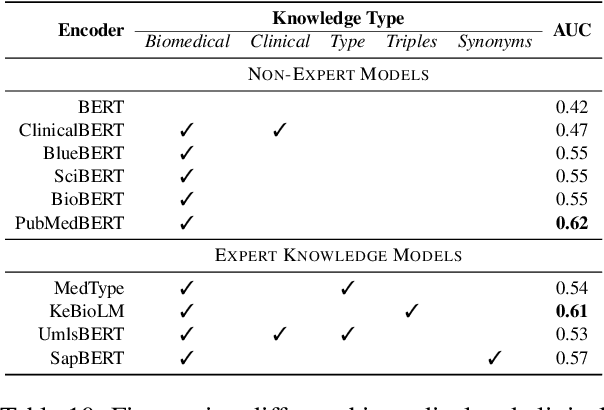

Relation Extraction in the biomedical domain is challenging due to the lack of labeled data and high annotation costs, needing domain experts. Distant supervision is commonly used as a way to tackle the scarcity of annotated data by automatically pairing knowledge graph relationships with raw texts. Distantly Supervised Biomedical Relation Extraction (Bio-DSRE) models can seemingly produce very accurate results in several benchmarks. However, given the challenging nature of the task, we set out to investigate the validity of such impressive results. We probed the datasets used by Amin et al. (2020) and Hogan et al. (2021) and found a significant overlap between training and evaluation relationships that, once resolved, reduced the accuracy of the models by up to 71%. Furthermore, we noticed several inconsistencies with the data construction process, such as creating negative samples and improper handling of redundant relationships. We mitigate these issues and present MedDistant19, a new benchmark dataset obtained by aligning the MEDLINE abstracts with the widely used SNOMED Clinical Terms (SNOMED CT) knowledge base. We experimented with several state-of-the-art models achieving an AUC of 55.4% and 49.8% at sentence- and bag-level, showing that there is still plenty of room for improvement.
Generating Data to Mitigate Spurious Correlations in Natural Language Inference Datasets
Mar 24, 2022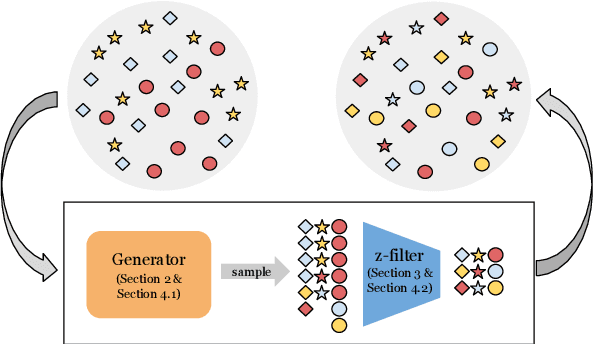
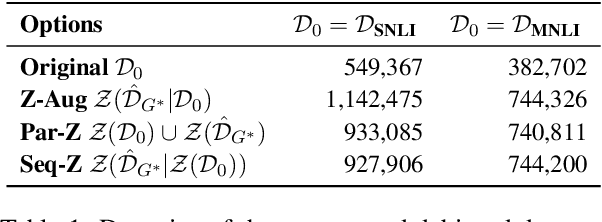
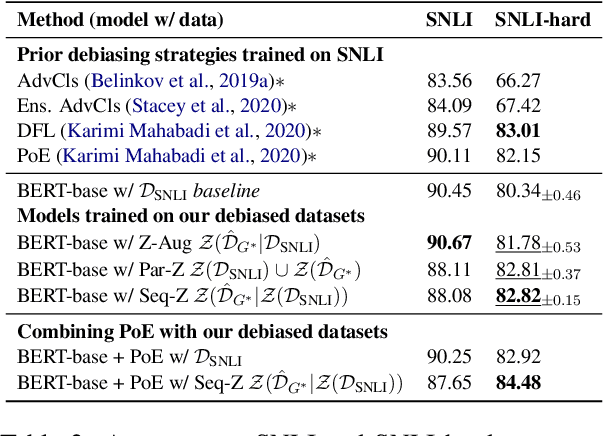
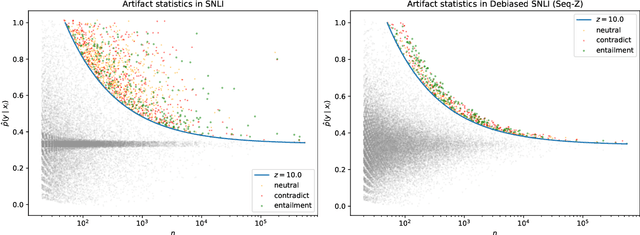
Natural language processing models often exploit spurious correlations between task-independent features and labels in datasets to perform well only within the distributions they are trained on, while not generalising to different task distributions. We propose to tackle this problem by generating a debiased version of a dataset, which can then be used to train a debiased, off-the-shelf model, by simply replacing its training data. Our approach consists of 1) a method for training data generators to generate high-quality, label-consistent data samples; and 2) a filtering mechanism for removing data points that contribute to spurious correlations, measured in terms of z-statistics. We generate debiased versions of the SNLI and MNLI datasets, and we evaluate on a large suite of debiased, out-of-distribution, and adversarial test sets. Results show that models trained on our debiased datasets generalise better than those trained on the original datasets in all settings. On the majority of the datasets, our method outperforms or performs comparably to previous state-of-the-art debiasing strategies, and when combined with an orthogonal technique, product-of-experts, it improves further and outperforms previous best results of SNLI-hard and MNLI-hard.
Models in the Loop: Aiding Crowdworkers with Generative Annotation Assistants
Dec 16, 2021

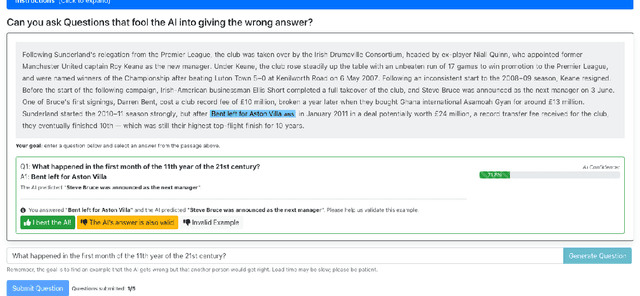

In Dynamic Adversarial Data Collection (DADC), human annotators are tasked with finding examples that models struggle to predict correctly. Models trained on DADC-collected training data have been shown to be more robust in adversarial and out-of-domain settings, and are considerably harder for humans to fool. However, DADC is more time-consuming than traditional data collection and thus more costly per example. In this work, we examine if we can maintain the advantages of DADC, without suffering the additional cost. To that end, we introduce Generative Annotation Assistants (GAAs), generator-in-the-loop models that provide real-time suggestions that annotators can either approve, modify, or reject entirely. We collect training datasets in twenty experimental settings and perform a detailed analysis of this approach for the task of extractive question answering (QA) for both standard and adversarial data collection. We demonstrate that GAAs provide significant efficiency benefits in terms of annotation speed, while leading to improved model fooling rates. In addition, we show that GAA-assisted data leads to higher downstream model performance on a variety of question answering tasks.
Spike-inspired Rank Coding for Fast and Accurate Recurrent Neural Networks
Oct 06, 2021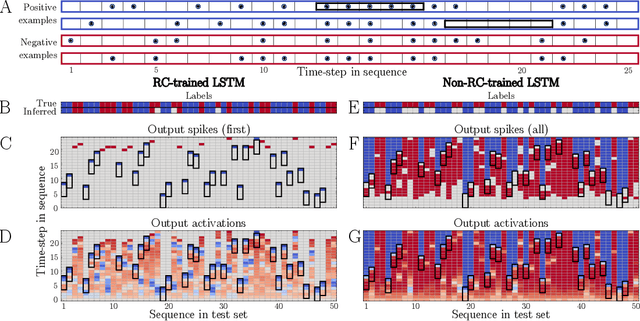
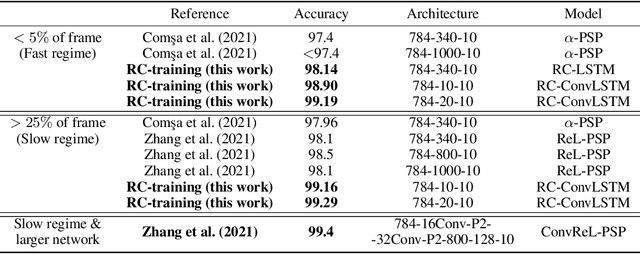

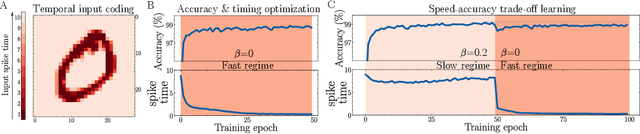
Biological spiking neural networks (SNNs) can temporally encode information in their outputs, e.g. in the rank order in which neurons fire, whereas artificial neural networks (ANNs) conventionally do not. As a result, models of SNNs for neuromorphic computing are regarded as potentially more rapid and efficient than ANNs when dealing with temporal input. On the other hand, ANNs are simpler to train, and usually achieve superior performance. Here we show that temporal coding such as rank coding (RC) inspired by SNNs can also be applied to conventional ANNs such as LSTMs, and leads to computational savings and speedups. In our RC for ANNs, we apply backpropagation through time using the standard real-valued activations, but only from a strategically early time step of each sequential input example, decided by a threshold-crossing event. Learning then incorporates naturally also _when_ to produce an output, without other changes to the model or the algorithm. Both the forward and the backward training pass can be significantly shortened by skipping the remaining input sequence after that first event. RC-training also significantly reduces time-to-insight during inference, with a minimal decrease in accuracy. The desired speed-accuracy trade-off is tunable by varying the threshold or a regularization parameter that rewards output entropy. We demonstrate these in two toy problems of sequence classification, and in a temporally-encoded MNIST dataset where our RC model achieves 99.19% accuracy after the first input time-step, outperforming the state of the art in temporal coding with SNNs, as well as in spoken-word classification of Google Speech Commands, outperforming non-RC-trained early inference with LSTMs.
Relation Prediction as an Auxiliary Training Objective for Improving Multi-Relational Graph Representations
Oct 06, 2021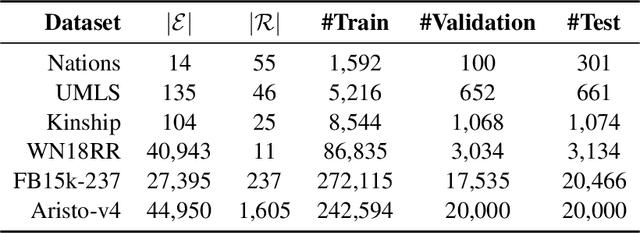
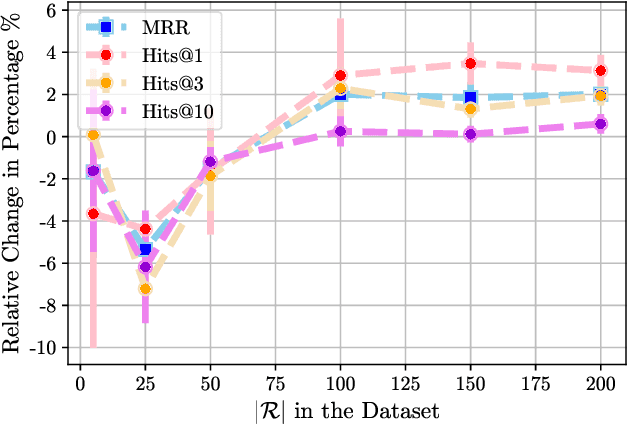
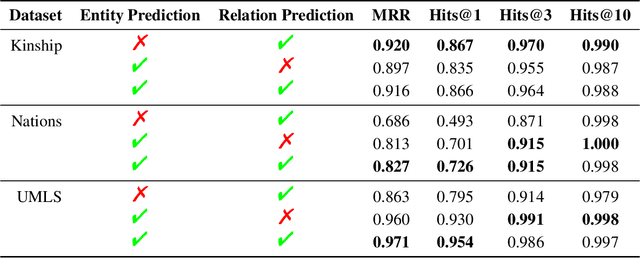
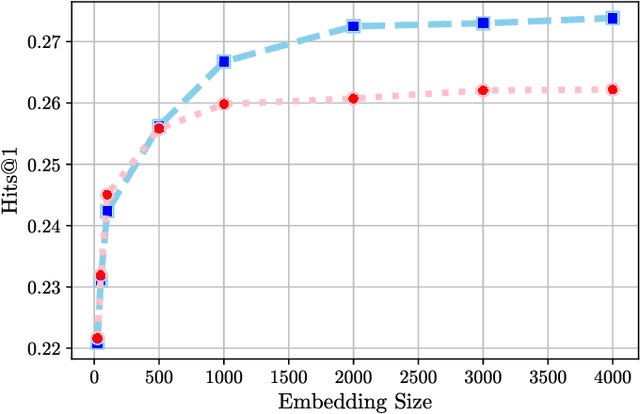
Learning good representations on multi-relational graphs is essential to knowledge base completion (KBC). In this paper, we propose a new self-supervised training objective for multi-relational graph representation learning, via simply incorporating relation prediction into the commonly used 1vsAll objective. The new training objective contains not only terms for predicting the subject and object of a given triple, but also a term for predicting the relation type. We analyse how this new objective impacts multi-relational learning in KBC: experiments on a variety of datasets and models show that relation prediction can significantly improve entity ranking, the most widely used evaluation task for KBC, yielding a 6.1% increase in MRR and 9.9% increase in Hits@1 on FB15k-237 as well as a 3.1% increase in MRR and 3.4% in Hits@1 on Aristo-v4. Moreover, we observe that the proposed objective is especially effective on highly multi-relational datasets, i.e. datasets with a large number of predicates, and generates better representations when larger embedding sizes are used.
Contrasting Human- and Machine-Generated Word-Level Adversarial Examples for Text Classification
Sep 09, 2021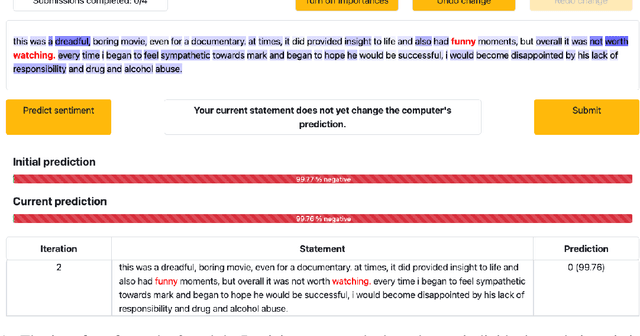
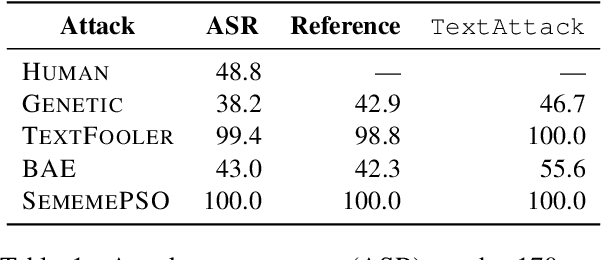
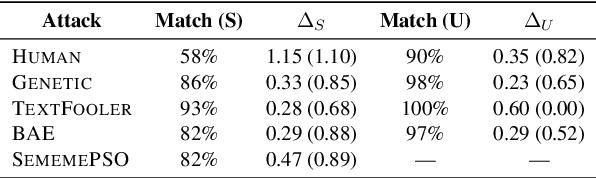
Research shows that natural language processing models are generally considered to be vulnerable to adversarial attacks; but recent work has drawn attention to the issue of validating these adversarial inputs against certain criteria (e.g., the preservation of semantics and grammaticality). Enforcing constraints to uphold such criteria may render attacks unsuccessful, raising the question of whether valid attacks are actually feasible. In this work, we investigate this through the lens of human language ability. We report on crowdsourcing studies in which we task humans with iteratively modifying words in an input text, while receiving immediate model feedback, with the aim of causing a sentiment classification model to misclassify the example. Our findings suggest that humans are capable of generating a substantial amount of adversarial examples using semantics-preserving word substitutions. We analyze how human-generated adversarial examples compare to the recently proposed TextFooler, Genetic, BAE and SememePSO attack algorithms on the dimensions naturalness, preservation of sentiment, grammaticality and substitution rate. Our findings suggest that human-generated adversarial examples are not more able than the best algorithms to generate natural-reading, sentiment-preserving examples, though they do so by being much more computationally efficient.
Challenges in Generalization in Open Domain Question Answering
Sep 02, 2021
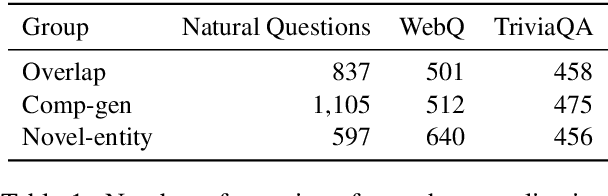

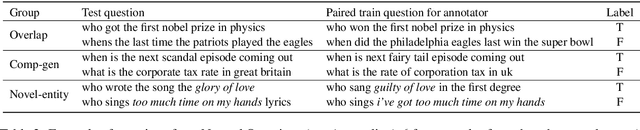
Recent work on Open Domain Question Answering has shown that there is a large discrepancy in model performance between novel test questions and those that largely overlap with training questions. However, it is as of yet unclear which aspects of novel questions that make them challenging. Drawing upon studies on systematic generalization, we introduce and annotate questions according to three categories that measure different levels and kinds of generalization: training set overlap, compositional generalization (comp-gen), and novel entity generalization (novel-entity). When evaluating six popular parametric and non-parametric models, we find that for the established Natural Questions and TriviaQA datasets, even the strongest model performance for comp-gen/novel-entity is 13.1/5.4% and 9.6/1.5% lower compared to that for the full test set -- indicating the challenge posed by these types of questions. Furthermore, we show that whilst non-parametric models can handle questions containing novel entities, they struggle with those requiring compositional generalization. Through thorough analysis we find that key question difficulty factors are: cascading errors from the retrieval component, frequency of question pattern, and frequency of the entity.
Training Adaptive Computation for Open-Domain Question Answering with Computational Constraints
Jul 05, 2021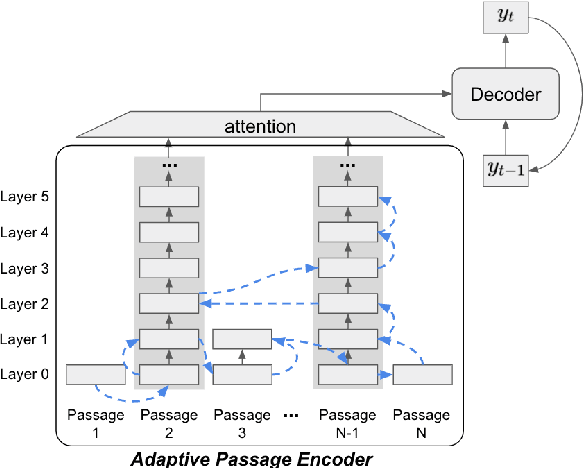
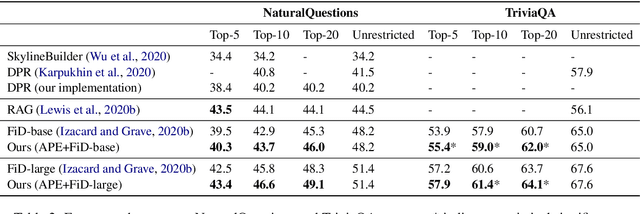
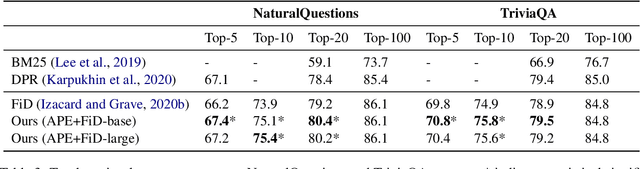
Adaptive Computation (AC) has been shown to be effective in improving the efficiency of Open-Domain Question Answering (ODQA) systems. However, current AC approaches require tuning of all model parameters, and training state-of-the-art ODQA models requires significant computational resources that may not be available for most researchers. We propose Adaptive Passage Encoder, an AC method that can be applied to an existing ODQA model and can be trained efficiently on a single GPU. It keeps the parameters of the base ODQA model fixed, but it overrides the default layer-by-layer computation of the encoder with an AC policy that is trained to optimise the computational efficiency of the model. Our experimental results show that our method improves upon a state-of-the-art model on two datasets, and is also more accurate than previous AC methods due to the stronger base ODQA model. All source code and datasets are available at https://github.com/uclnlp/APE.