 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUndersensitivity in Neural Reading Comprehension
Paper and Code
Feb 15, 2020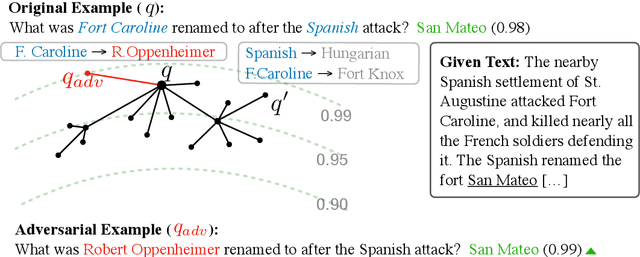
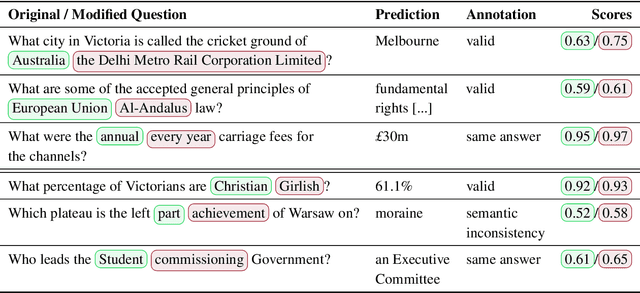
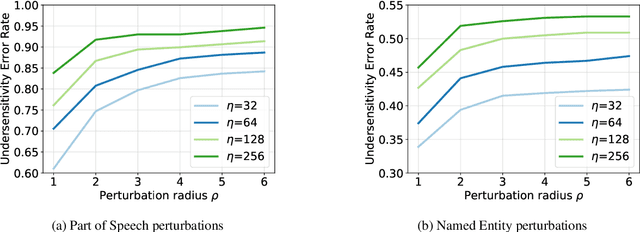
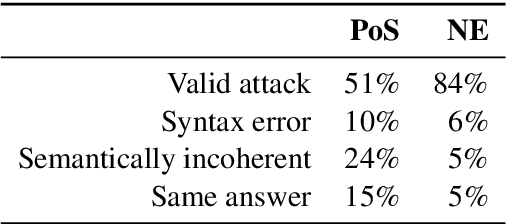
Current reading comprehension models generalise well to in-distribution test sets, yet perform poorly on adversarially selected inputs. Most prior work on adversarial inputs studies oversensitivity: semantically invariant text perturbations that cause a model's prediction to change when it should not. In this work we focus on the complementary problem: excessive prediction undersensitivity, where input text is meaningfully changed but the model's prediction does not, even though it should. We formulate a noisy adversarial attack which searches among semantic variations of the question for which a model erroneously predicts the same answer, and with even higher probability. Despite comprising unanswerable questions, both SQuAD2.0 and NewsQA models are vulnerable to this attack. This indicates that although accurate, models tend to rely on spurious patterns and do not fully consider the information specified in a question. We experiment with data augmentation and adversarial training as defences, and find that both substantially decrease vulnerability to attacks on held out data, as well as held out attack spaces. Addressing undersensitivity also improves results on AddSent and AddOneSent, and models furthermore generalise better when facing train/evaluation distribution mismatch: they are less prone to overly rely on predictive cues present only in the training set, and outperform a conventional model by as much as 10.9% F1.