 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheory of Machine Learning Debugging via M-estimation
Jun 16, 2020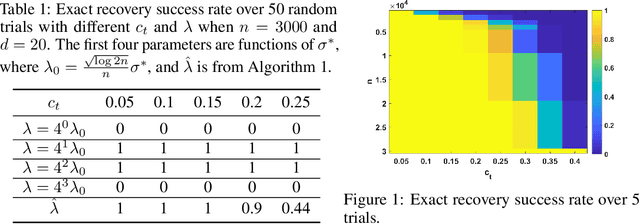
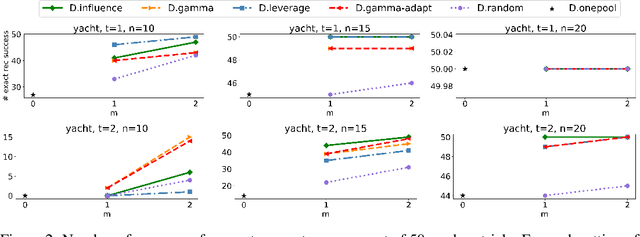

We investigate problems in penalized $M$-estimation, inspired by applications in machine learning debugging. Data are collected from two pools, one containing data with possibly contaminated labels, and the other which is known to contain only cleanly labeled points. We first formulate a general statistical algorithm for identifying buggy points and provide rigorous theoretical guarantees under the assumption that the data follow a linear model. We then present two case studies to illustrate the results of our general theory and the dependence of our estimator on clean versus buggy points. We further propose an algorithm for tuning parameter selection of our Lasso-based algorithm and provide corresponding theoretical guarantees. Finally, we consider a two-person "game" played between a bug generator and a debugger, where the debugger can augment the contaminated data set with cleanly labeled versions of points in the original data pool. We establish a theoretical result showing a sufficient condition under which the bug generator can always fool the debugger. Nonetheless, we provide empirical results showing that such a situation may not occur in practice, making it possible for natural augmentation strategies combined with our Lasso debugging algorithm to succeed.
Boosting Algorithms for Estimating Optimal Individualized Treatment Rules
Jan 31, 2020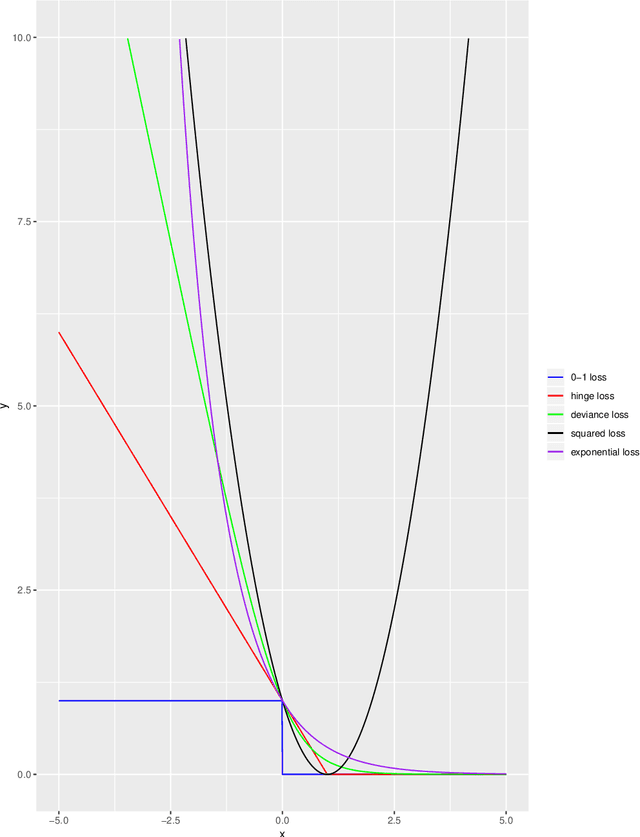
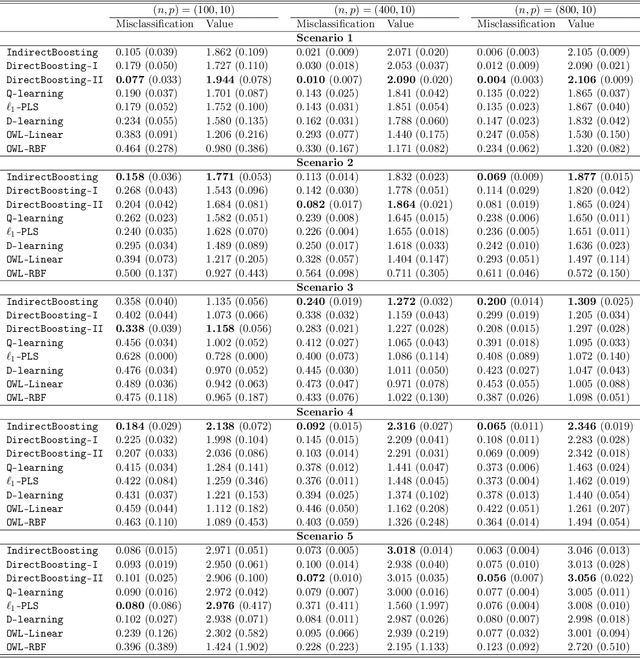
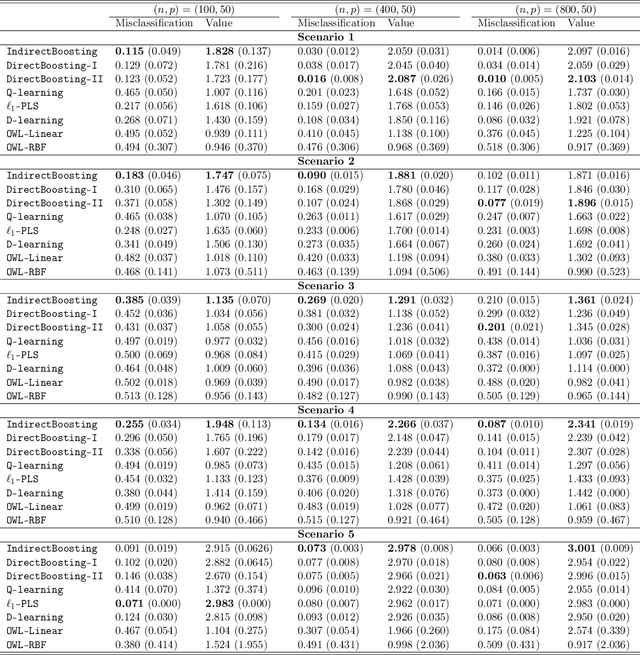
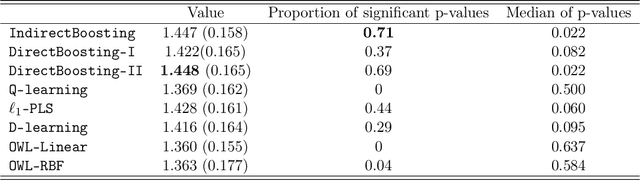
We present nonparametric algorithms for estimating optimal individualized treatment rules. The proposed algorithms are based on the XGBoost algorithm, which is known as one of the most powerful algorithms in the machine learning literature. Our main idea is to model the conditional mean of clinical outcome or the decision rule via additive regression trees, and use the boosting technique to estimate each single tree iteratively. Our approaches overcome the challenge of correct model specification, which is required in current parametric methods. The major contribution of our proposed algorithms is providing efficient and accurate estimation of the highly nonlinear and complex optimal individualized treatment rules that often arise in practice. Finally, we illustrate the superior performance of our algorithms by extensive simulation studies and conclude with an application to the real data from a diabetes Phase III trial.
Extracting robust and accurate features via a robust information bottleneck
Oct 15, 2019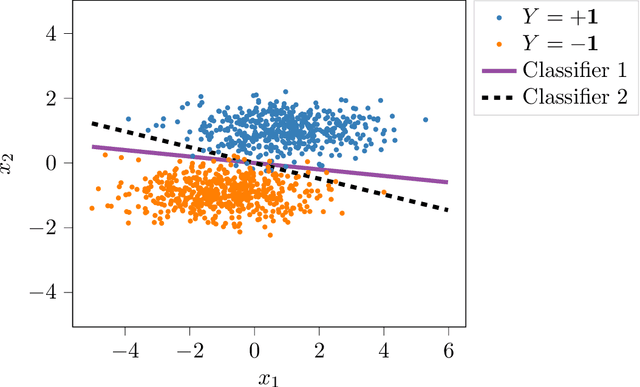
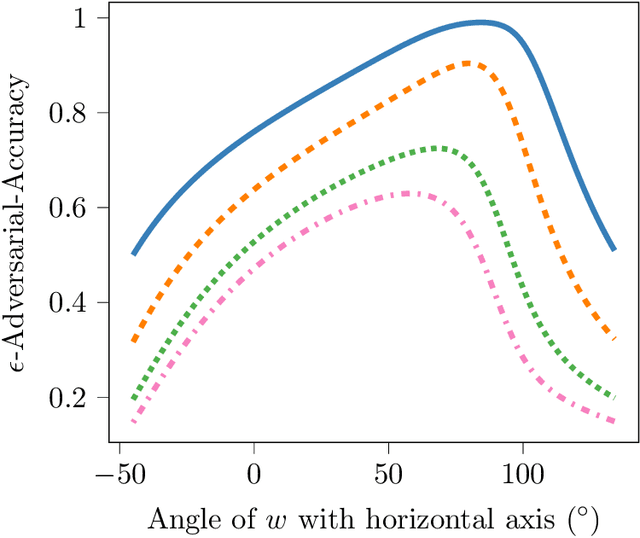
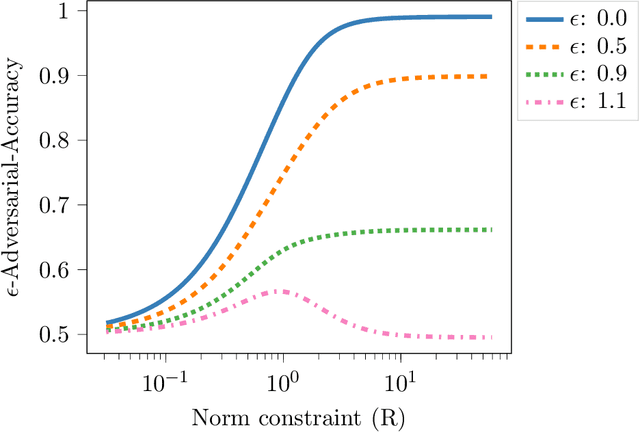
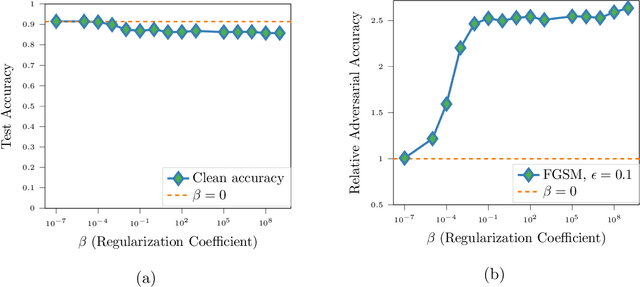
We propose a novel strategy for extracting features in supervised learning that can be used to construct a classifier which is more robust to small perturbations in the input space. Our method builds upon the idea of the information bottleneck by introducing an additional penalty term that encourages the Fisher information of the extracted features to be small, when parametrized by the inputs. By tuning the regularization parameter, we can explicitly trade off the opposing desiderata of robustness and accuracy when constructing a classifier. We derive the optimal solution to the robust information bottleneck when the inputs and outputs are jointly Gaussian, proving that the optimally robust features are also jointly Gaussian in that setting. Furthermore, we propose a method for optimizing a variational bound on the robust information bottleneck objective in general settings using stochastic gradient descent, which may be implemented efficiently in neural networks. Our experimental results for synthetic and real data sets show that the proposed feature extraction method indeed produces classifiers with increased robustness to perturbations.
Robustifying deep networks for image segmentation
Aug 01, 2019Purpose: The purpose of this study is to investigate the robustness of a commonly-used convolutional neural network for image segmentation with respect to visually-subtle adversarial perturbations, and suggest new methods to make these networks more robust to such perturbations. Materials and Methods: In this retrospective study, the accuracy of brain tumor segmentation was studied in subjects with low- and high-grade gliomas. A three-dimensional UNet model was implemented to segment four different MR series (T1-weighted, post-contrast T1-weighted, T2- weighted, and T2-weighted FLAIR) into four pixelwise labels (Gd-enhancing tumor, peritumoral edema, necrotic and non-enhancing tumor, and background). We developed attack strategies based on the Fast Gradient Sign Method (FGSM), iterative FGSM (i-FGSM), and targeted iterative FGSM (ti-FGSM) to produce effective attacks. Additionally, we explored the effectiveness of distillation and adversarial training via data augmentation to counteract adversarial attacks. Robustness was measured by comparing the Dice coefficient for each attack method using Wilcoxon signed-rank tests. Results: Attacks based on FGSM, i-FGSM, and ti-FGSM were effective in significantly reducing the quality of image segmentation with reductions in Dice coefficient by up to 65%. For attack defenses, distillation performed significantly better than adversarial training approaches. However, all defense approaches performed worse compared to unperturbed test images. Conclusion: Segmentation networks can be adversely affected by targeted attacks that introduce visually minor (and potentially undetectable) modifications to existing images. With an increasing interest in applying deep learning techniques to medical imaging data, it is important to quantify the ramifications of adversarial inputs (either intentional or unintentional).
Estimating location parameters in entangled single-sample distributions
Jul 06, 2019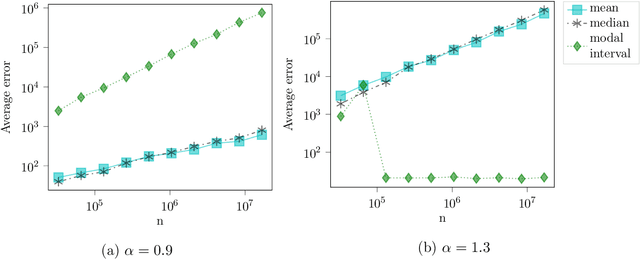
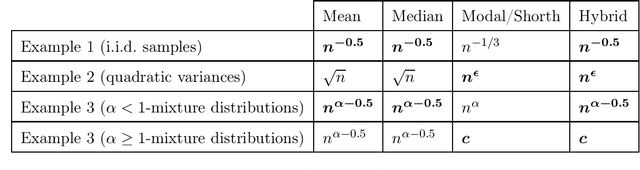

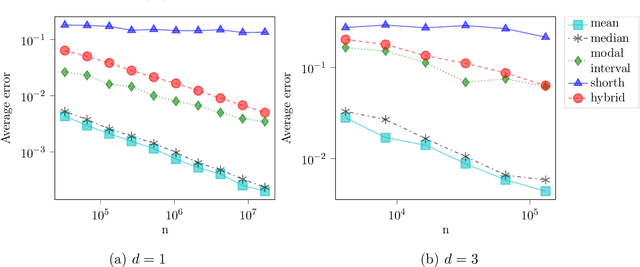
We consider the problem of estimating the common mean of independently sampled data, where samples are drawn in a possibly non-identical manner from symmetric, unimodal distributions with a common mean. This generalizes the setting of Gaussian mixture modeling, since the number of distinct mixture components may diverge with the number of observations. We propose an estimator that adapts to the level of heterogeneity in the data, achieving near-optimality in both the i.i.d. setting and some heterogeneous settings, where the fraction of ``low-noise'' points is as small as $\frac{\log n}{n}$. Our estimator is a hybrid of the modal interval, shorth, and median estimators from classical statistics; however, the key technical contributions rely on novel empirical process theory results that we derive for independent but non-i.i.d. data. In the multivariate setting, we generalize our theory to mean estimation for mixtures of radially symmetric distributions, and derive minimax lower bounds on the expected error of any estimator that is agnostic to the scales of individual data points. Finally, we describe an extension of our estimators applicable to linear regression. In the multivariate mean estimation and regression settings, we present computationally feasible versions of our estimators that run in time polynomial in the number of data points.
Does Data Augmentation Lead to Positive Margin?
May 08, 2019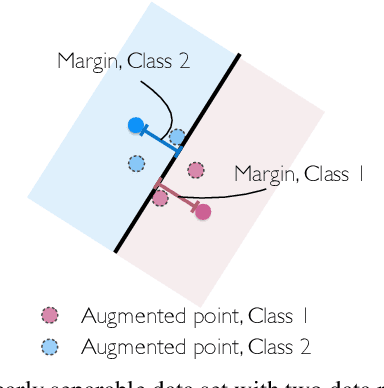
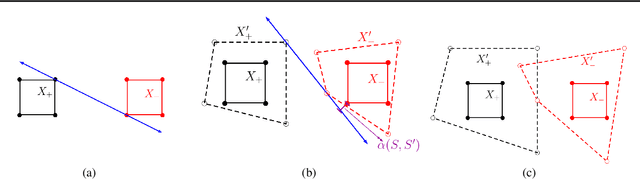
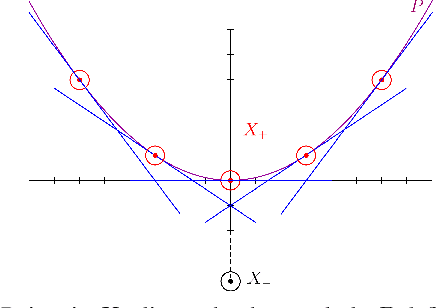
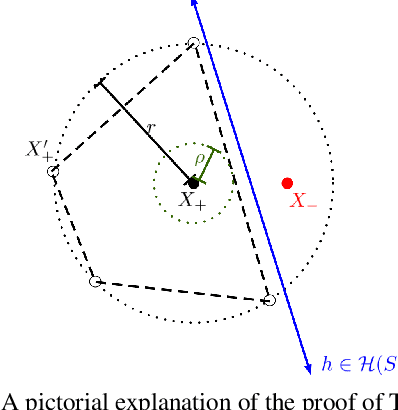
Data augmentation (DA) is commonly used during model training, as it significantly improves test error and model robustness. DA artificially expands the training set by applying random noise, rotations, crops, or even adversarial perturbations to the input data. Although DA is widely used, its capacity to provably improve robustness is not fully understood. In this work, we analyze the robustness that DA begets by quantifying the margin that DA enforces on empirical risk minimizers. We first focus on linear separators, and then a class of nonlinear models whose labeling is constant within small convex hulls of data points. We present lower bounds on the number of augmented data points required for non-zero margin, and show that commonly used DA techniques may only introduce significant margin after adding exponentially many points to the data set.
Scale calibration for high-dimensional robust regression
Nov 06, 2018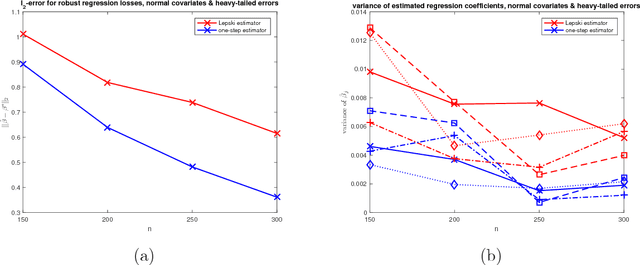
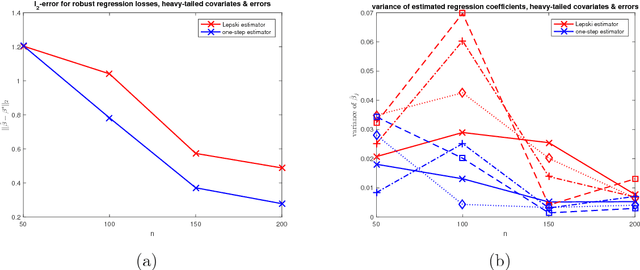
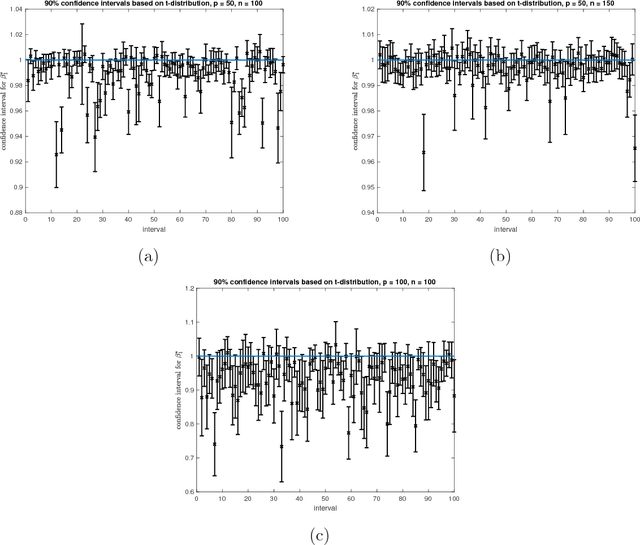
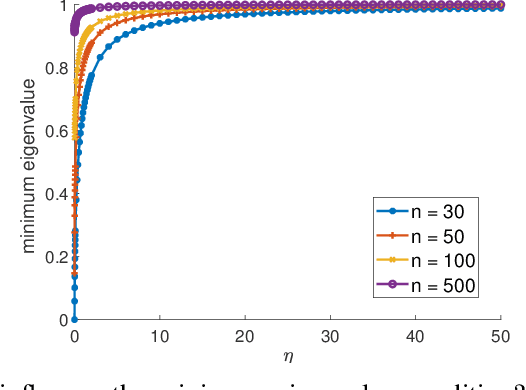
We present a new method for high-dimensional linear regression when a scale parameter of the additive errors is unknown. The proposed estimator is based on a penalized Huber $M$-estimator, for which theoretical results on estimation error have recently been proposed in high-dimensional statistics literature. However, the variance of the error term in the linear model is intricately connected to the optimal parameter used to define the shape of the Huber loss. Our main idea is to use an adaptive technique, based on Lepski's method, to overcome the difficulties in solving a joint nonconvex optimization problem with respect to the location and scale parameters.
Adversarial Risk Bounds for Binary Classification via Function Transformation
Oct 22, 2018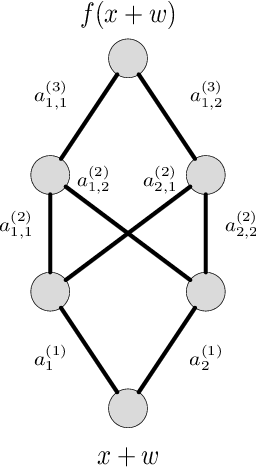
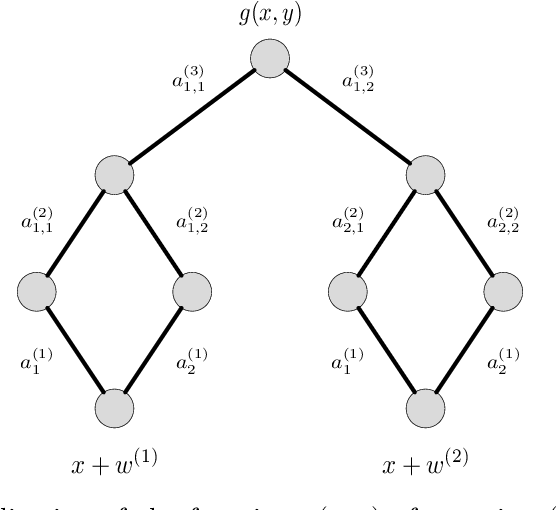
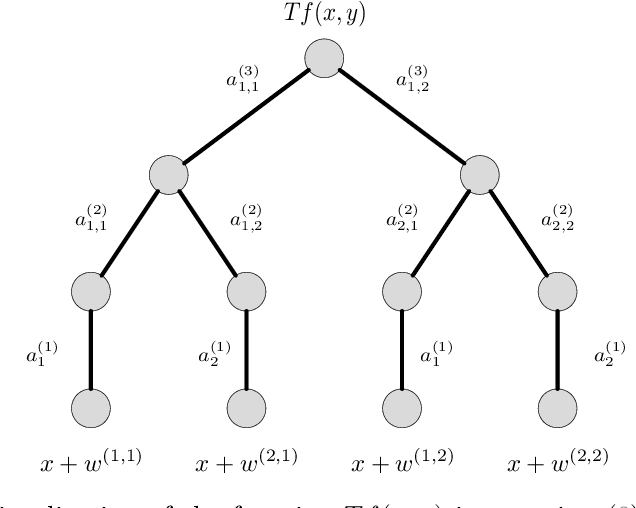
We derive new bounds for a notion of adversarial risk, characterizing the robustness of binary classifiers. Specifically, we study the cases of linear classifiers and neural network classifiers, and introduce transformations with the property that the risk of the transformed functions upper-bounds the adversarial risk of the original functions. This reduces the problem of deriving adversarial risk bounds to the problem of deriving risk bounds using standard learning-theoretic techniques. We then derive bounds on the Rademacher complexities of the transformed function classes, obtaining error rates on the same order as the generalization error of the original function classes. Finally, we provide two algorithms for optimizing the adversarial risk bounds in the linear case, and discuss connections to regularization and distributional robustness.
Online learning with graph-structured feedback against adaptive adversaries
Apr 01, 2018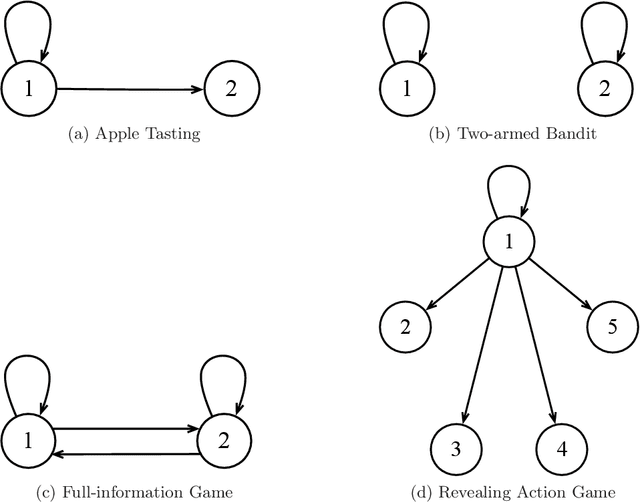
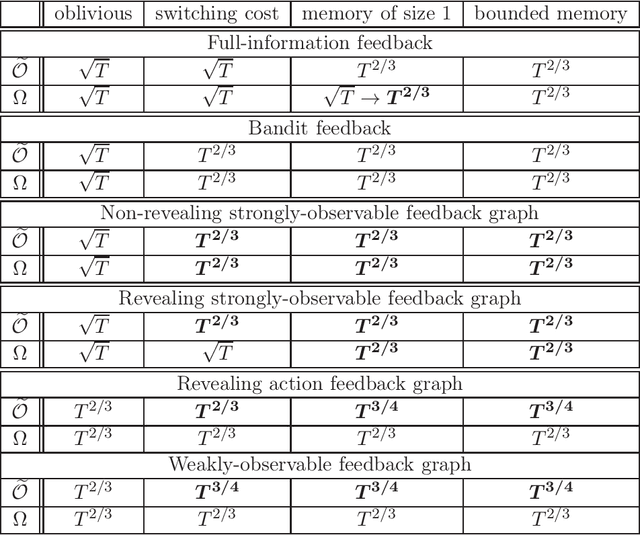
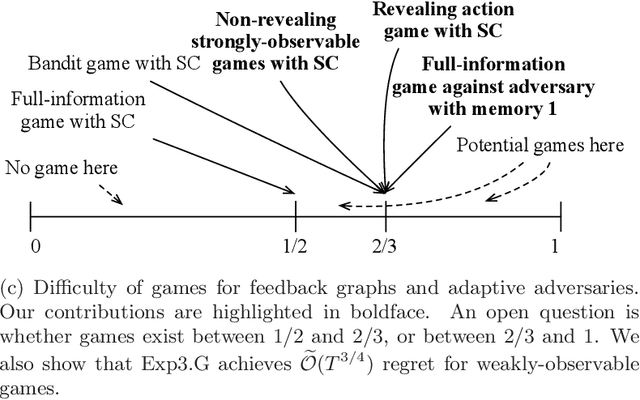
We derive upper and lower bounds for the policy regret of $T$-round online learning problems with graph-structured feedback, where the adversary is nonoblivious but assumed to have a bounded memory. We obtain upper bounds of $\widetilde O(T^{2/3})$ and $\widetilde O(T^{3/4})$ for strongly-observable and weakly-observable graphs, respectively, based on analyzing a variant of the Exp3 algorithm. When the adversary is allowed a bounded memory of size 1, we show that a matching lower bound of $\widetilde\Omega(T^{2/3})$ is achieved in the case of full-information feedback. We also study the particular loss structure of an oblivious adversary with switching costs, and show that in such a setting, non-revealing strongly-observable feedback graphs achieve a lower bound of $\widetilde\Omega(T^{2/3})$, as well.
Graph-Based Ascent Algorithms for Function Maximization
Feb 13, 2018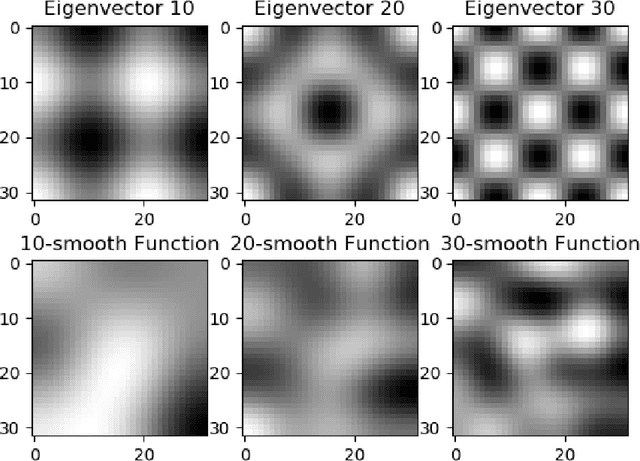
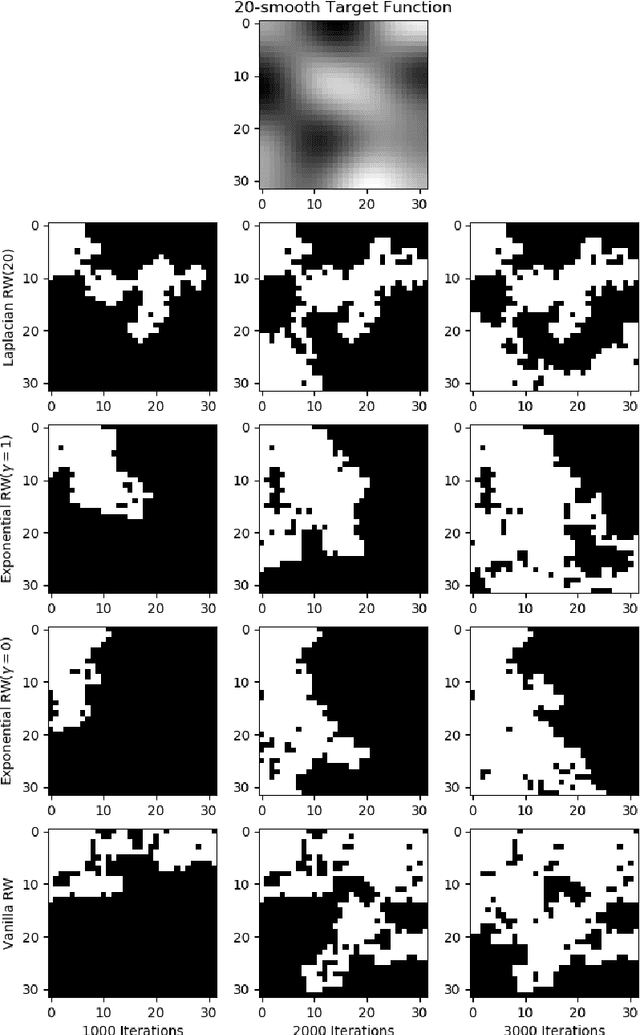
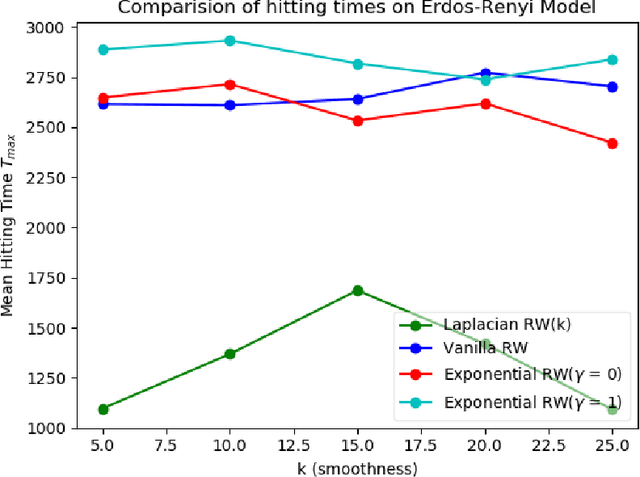
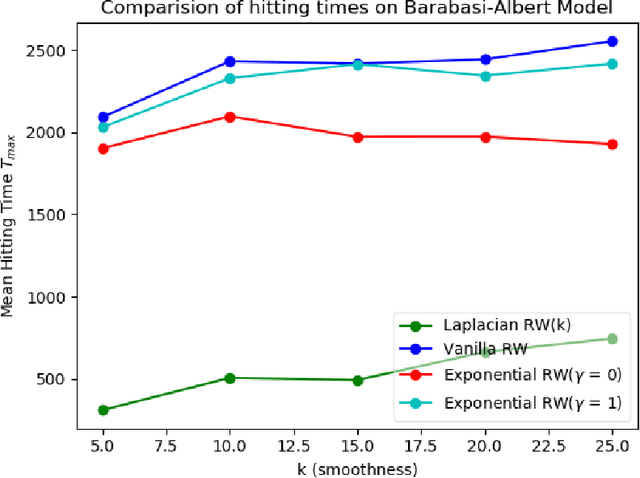
We study the problem of finding the maximum of a function defined on the nodes of a connected graph. The goal is to identify a node where the function obtains its maximum. We focus on local iterative algorithms, which traverse the nodes of the graph along a path, and the next iterate is chosen from the neighbors of the current iterate with probability distribution determined by the function values at the current iterate and its neighbors. We study two algorithms corresponding to a Metropolis-Hastings random walk with different transition kernels: (i) The first algorithm is an exponentially weighted random walk governed by a parameter $\gamma$. (ii) The second algorithm is defined with respect to the graph Laplacian and a smoothness parameter $k$. We derive convergence rates for the two algorithms in terms of total variation distance and hitting times. We also provide simulations showing the relative convergence rates of our algorithms in comparison to an unbiased random walk, as a function of the smoothness of the graph function. Our algorithms may be categorized as a new class of "descent-based" methods for function maximization on the nodes of a graph.