 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefined $α$-Divergence Variational Inference via Rejection Sampling
Oct 29, 2019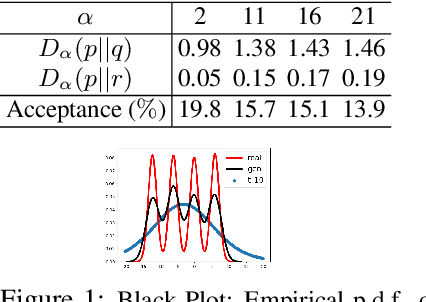
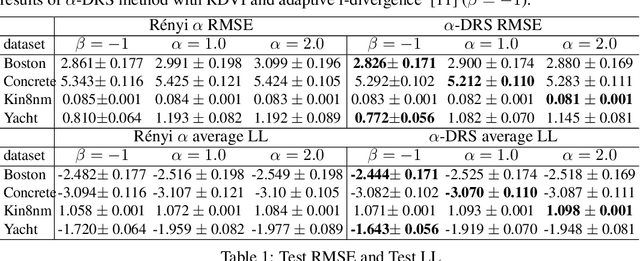
We present an approximate inference method, based on a synergistic combination of R\'enyi $\alpha$-divergence variational inference (RDVI) and rejection sampling (RS). RDVI is based on minimization of R\'enyi $\alpha$-divergence $D_\alpha(p||q)$ between the true distribution $p(x)$ and a variational approximation $q(x)$; RS draws samples from a distribution $p(x) = \tilde{p}(x)/Z_{p}$ using a proposal $q(x)$, s.t. $Mq(x) \geq \tilde{p}(x), \forall x$. Our inference method is based on a crucial observation that $D_\infty(p||q)$ equals $\log M(\theta)$ where $M(\theta)$ is the optimal value of the RS constant for a given proposal $q_\theta(x)$. This enables us to develop a \emph{two-stage} hybrid inference algorithm. Stage-1 performs RDVI to learn $q_\theta$ by minimizing an estimator of $D_\alpha(p||q)$, and uses the learned $q_\theta$ to find an (approximately) optimal $\tilde{M}(\theta)$. Stage-2 performs RS using the constant $\tilde{M}(\theta)$ to improve the approximate distribution $q_\theta$ and obtain a sample-based approximation. We prove that this two-stage method allows us to learn considerably more accurate approximations of the target distribution as compared to RDVI. We demonstrate our method's efficacy via several experiments on synthetic and real datasets.
A Meta-Learning Framework for Generalized Zero-Shot Learning
Sep 10, 2019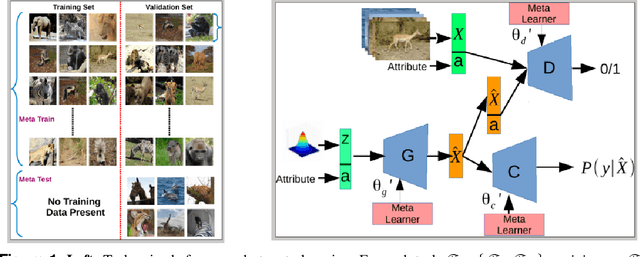
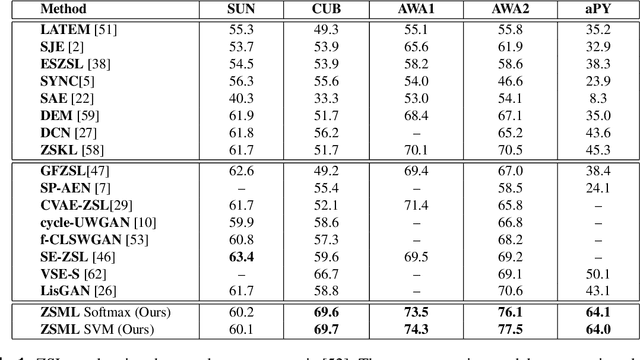
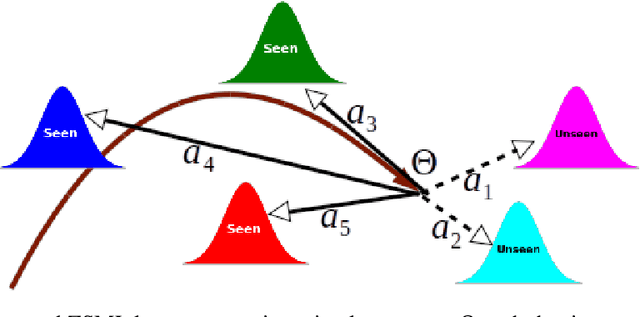
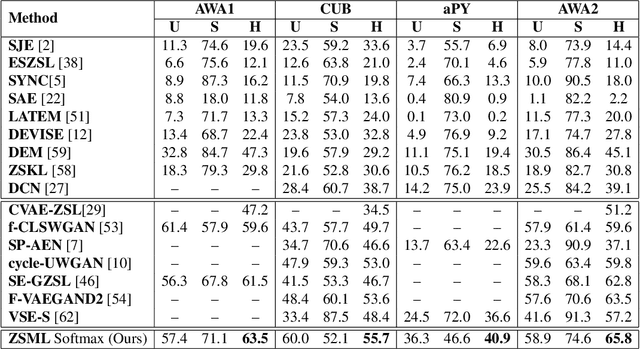
Learning to classify unseen class samples at test time is popularly referred to as zero-shot learning (ZSL). If test samples can be from training (seen) as well as unseen classes, it is a more challenging problem due to the existence of strong bias towards seen classes. This problem is generally known as \emph{generalized} zero-shot learning (GZSL). Thanks to the recent advances in generative models such as VAEs and GANs, sample synthesis based approaches have gained considerable attention for solving this problem. These approaches are able to handle the problem of class bias by synthesizing unseen class samples. However, these ZSL/GZSL models suffer due to the following key limitations: $(i)$ Their training stage learns a class-conditioned generator using only \emph{seen} class data and the training stage does not \emph{explicitly} learn to generate the unseen class samples; $(ii)$ They do not learn a generic optimal parameter which can easily generalize for both seen and unseen class generation; and $(iii)$ If we only have access to a very few samples per seen class, these models tend to perform poorly. In this paper, we propose a meta-learning based generative model that naturally handles these limitations. The proposed model is based on integrating model-agnostic meta learning with a Wasserstein GAN (WGAN) to handle $(i)$ and $(iii)$, and uses a novel task distribution to handle $(ii)$. Our proposed model yields significant improvements on standard ZSL as well as more challenging GZSL setting. In ZSL setting, our model yields 4.5\%, 6.0\%, 9.8\%, and 27.9\% relative improvements over the current state-of-the-art on CUB, AWA1, AWA2, and aPY datasets, respectively.
A Generative Framework for Zero-Shot Learning with Adversarial Domain Adaptation
Jun 07, 2019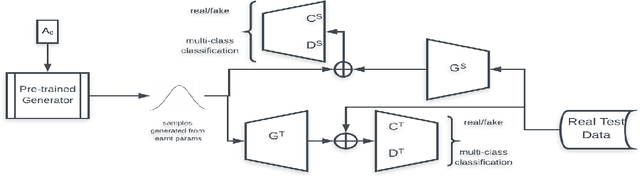
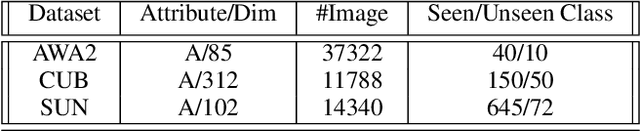
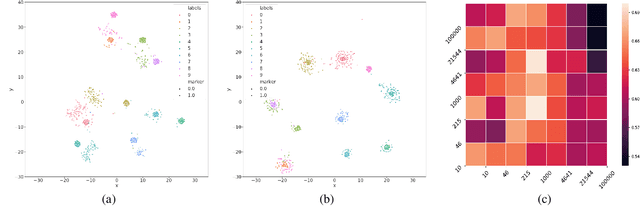
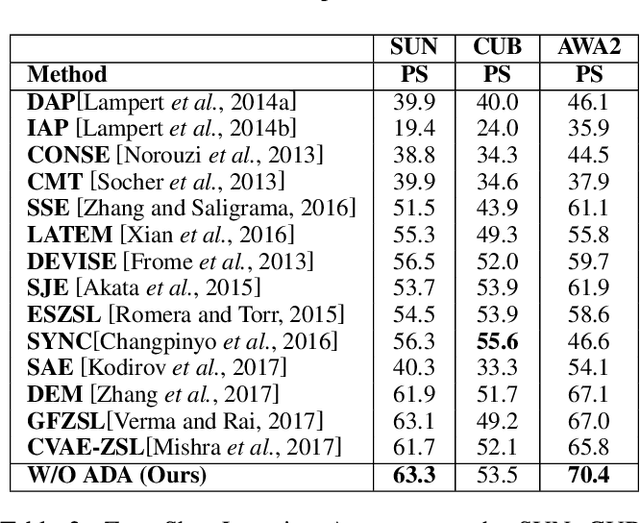
In this paper, we present a domain adaptation based generative framework for Zero-Shot Learning. We explicitly target the problem of domain shift between the seen and unseen class distribution in Zero-Shot Learning (ZSL) and seek to minimize it by developing a generative model and training it via adversarial domain adaptation. Our approach is based on end-to-end learning of the class distributions of seen classes and unseen classes. To enable the model to learn the class distributions of unseen classes, we parameterize these class distributions in terms of the class attribute information (which is available for both seen and unseen classes). This provides a very simple way to learn the class distribution of any unseen class, given only its class attribute information, and no labeled training data. Training this model with adversarial domain adaptation provides robustness against the distribution mismatch between the data from seen and unseen classes. Through a comprehensive set of experiments, we show that our model yields superior accuracies as compared to various state-of-the-art ZSL models, on a variety of benchmark datasets.
Variational Autoencoders for Sparse and Overdispersed Discrete Data
May 24, 2019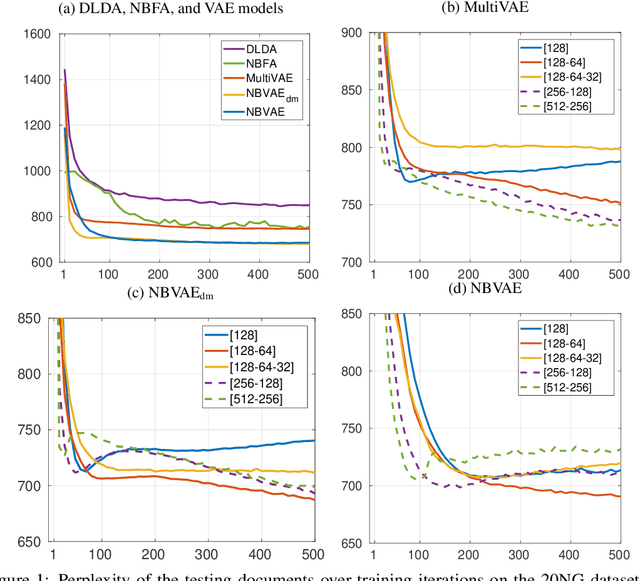
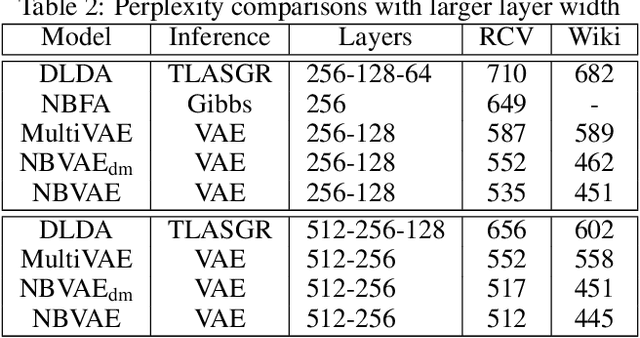
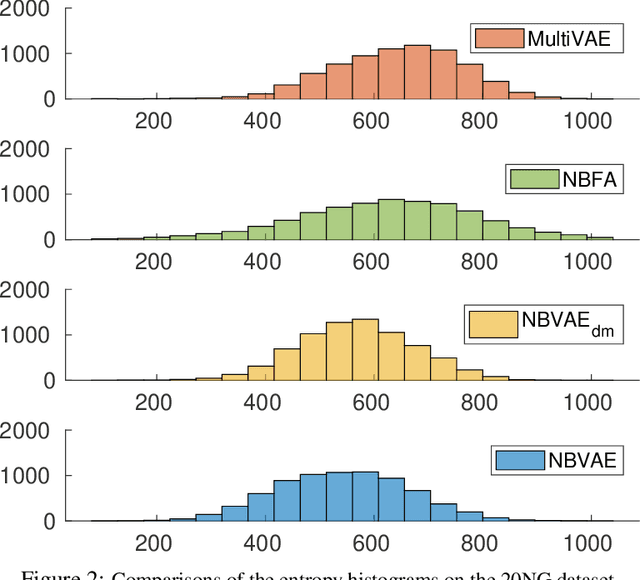
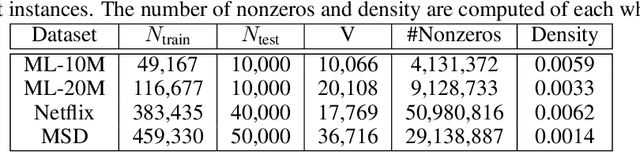
Many applications, such as text modelling, high-throughput sequencing, and recommender systems, require analysing sparse, high-dimensional, and overdispersed discrete (count-valued or binary) data. Although probabilistic matrix factorisation and linear/nonlinear latent factor models have enjoyed great success in modelling such data, many existing models may have inferior modelling performance due to the insufficient capability of modelling overdispersion in count-valued data and model misspecification in general. In this paper, we comprehensively study these issues and propose a variational autoencoder based framework that generates discrete data via negative-binomial distribution. We also examine the model's ability to capture properties, such as self- and cross-excitations in discrete data, which is critical for modelling overdispersion. We conduct extensive experiments on three important problems from discrete data analysis: text analysis, collaborative filtering, and multi-label learning. Compared with several state-of-the-art baselines, the proposed models achieve significantly better performance on the above problems.
Stochastic Blockmodels meet Graph Neural Networks
May 14, 2019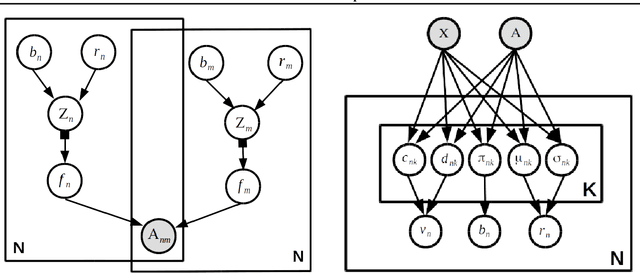
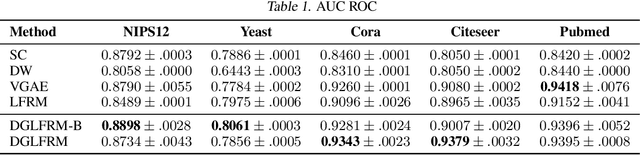
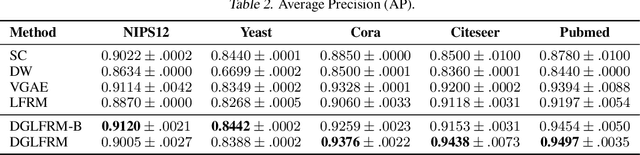
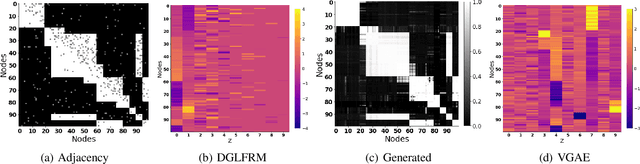
Stochastic blockmodels (SBM) and their variants, $e.g.$, mixed-membership and overlapping stochastic blockmodels, are latent variable based generative models for graphs. They have proven to be successful for various tasks, such as discovering the community structure and link prediction on graph-structured data. Recently, graph neural networks, $e.g.$, graph convolutional networks, have also emerged as a promising approach to learn powerful representations (embeddings) for the nodes in the graph, by exploiting graph properties such as locality and invariance. In this work, we unify these two directions by developing a \emph{sparse} variational autoencoder for graphs, that retains the interpretability of SBMs, while also enjoying the excellent predictive performance of graph neural nets. Moreover, our framework is accompanied by a fast recognition model that enables fast inference of the node embeddings (which are of independent interest for inference in SBM and its variants). Although we develop this framework for a particular type of SBM, namely the \emph{overlapping} stochastic blockmodel, the proposed framework can be adapted readily for other types of SBMs. Experimental results on several benchmarks demonstrate encouraging results on link prediction while learning an interpretable latent structure that can be used for community discovery.
Play and Prune: Adaptive Filter Pruning for Deep Model Compression
May 11, 2019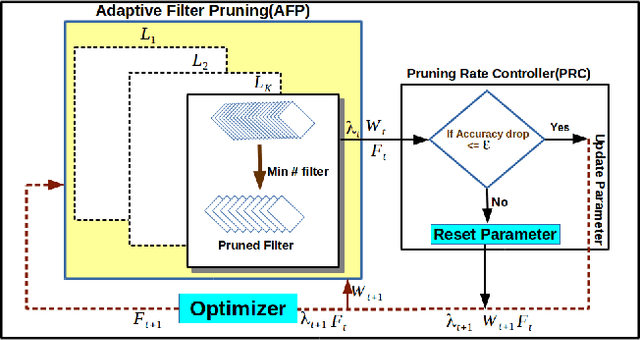
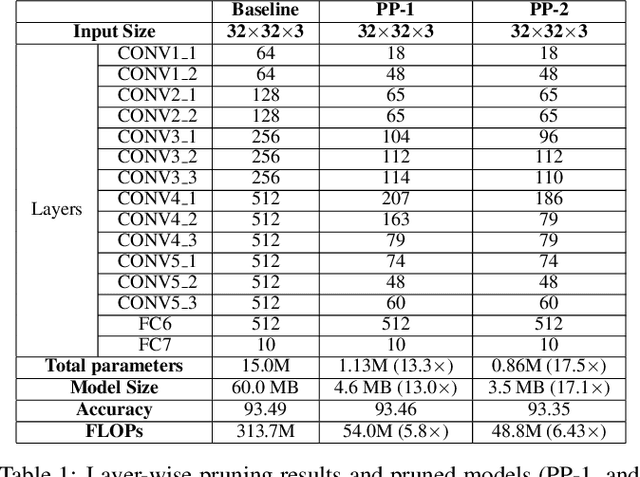
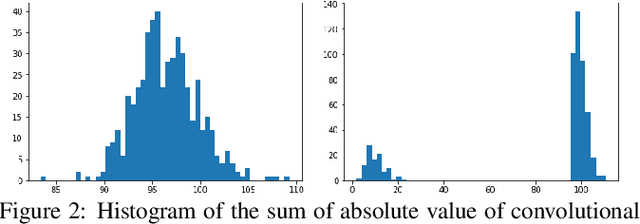
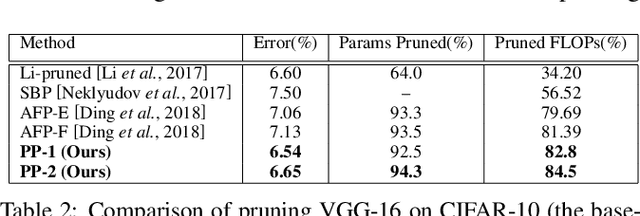
While convolutional neural networks (CNN) have achieved impressive performance on various classification/recognition tasks, they typically consist of a massive number of parameters. This results in significant memory requirement as well as computational overheads. Consequently, there is a growing need for filter-level pruning approaches for compressing CNN based models that not only reduce the total number of parameters but reduce the overall computation as well. We present a new min-max framework for filter-level pruning of CNNs. Our framework, called Play and Prune (PP), jointly prunes and fine-tunes CNN model parameters, with an adaptive pruning rate, while maintaining the model's predictive performance. Our framework consists of two modules: (1) An adaptive filter pruning (AFP) module, which minimizes the number of filters in the model; and (2) A pruning rate controller (PRC) module, which maximizes the accuracy during pruning. Moreover, unlike most previous approaches, our approach allows directly specifying the desired error tolerance instead of pruning level. Our compressed models can be deployed at run-time, without requiring any special libraries or hardware. Our approach reduces the number of parameters of VGG-16 by an impressive factor of 17.5X, and number of FLOPS by 6.43X, with no loss of accuracy, significantly outperforming other state-of-the-art filter pruning methods.
Generative Model for Zero-Shot Sketch-Based Image Retrieval
Apr 18, 2019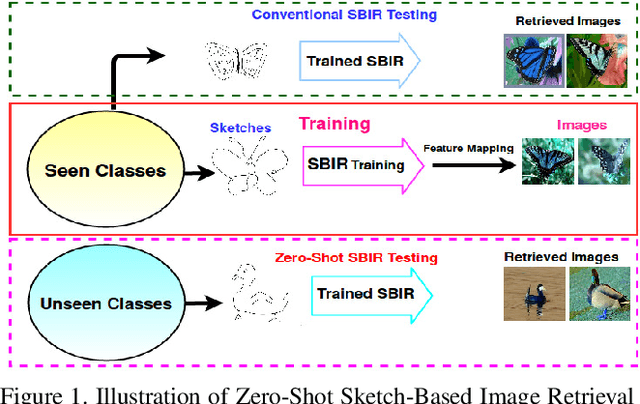
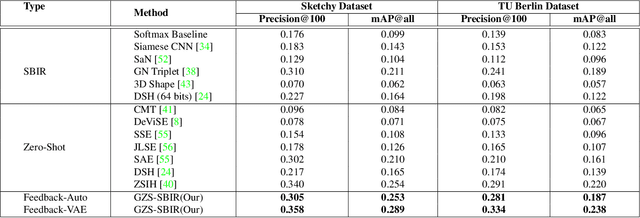
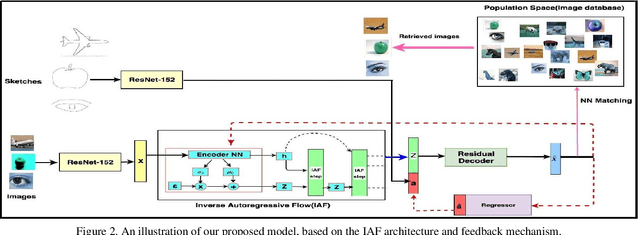
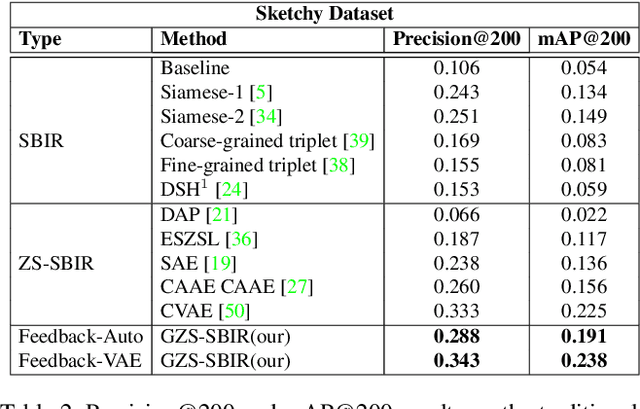
We present a probabilistic model for Sketch-Based Image Retrieval (SBIR) where, at retrieval time, we are given sketches from novel classes, that were not present at training time. Existing SBIR methods, most of which rely on learning class-wise correspondences between sketches and images, typically work well only for previously seen sketch classes, and result in poor retrieval performance on novel classes. To address this, we propose a generative model that learns to generate images, conditioned on a given novel class sketch. This enables us to reduce the SBIR problem to a standard image-to-image search problem. Our model is based on an inverse auto-regressive flow based variational autoencoder, with a feedback mechanism to ensure robust image generation. We evaluate our model on two very challenging datasets, Sketchy, and TU Berlin, with novel train-test split. The proposed approach significantly outperforms various baselines on both the datasets.
HetConv: Heterogeneous Kernel-Based Convolutions for Deep CNNs
Mar 25, 2019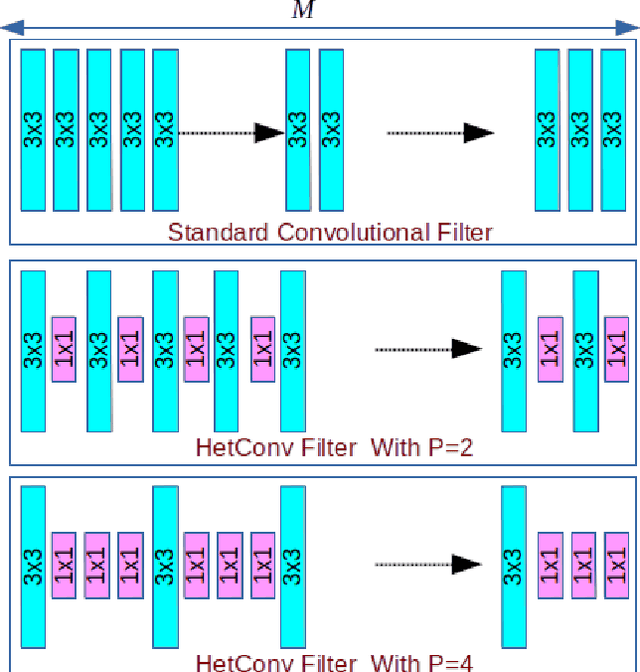
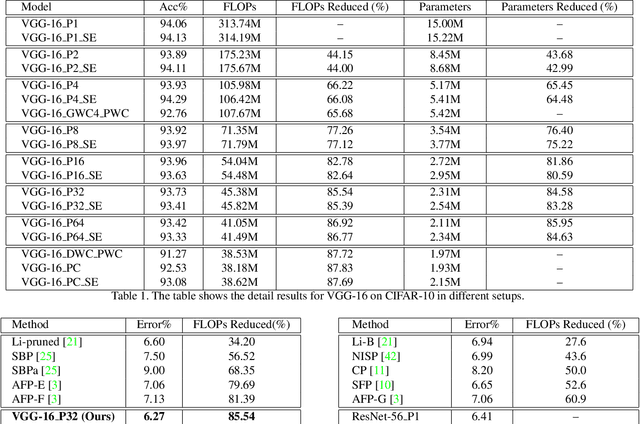
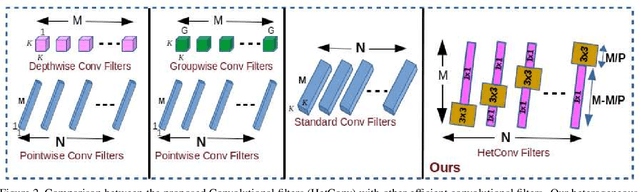
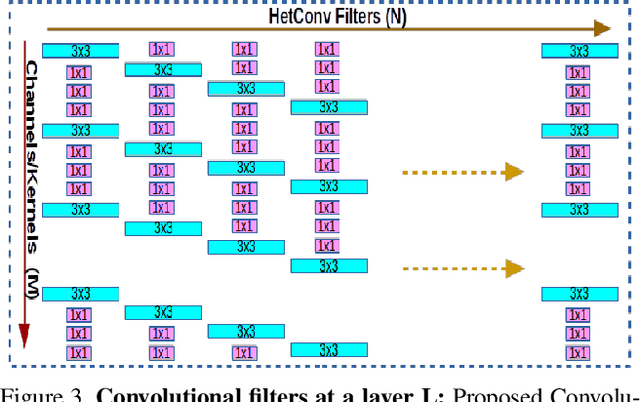
We present a novel deep learning architecture in which the convolution operation leverages heterogeneous kernels. The proposed HetConv (Heterogeneous Kernel-Based Convolution) reduces the computation (FLOPs) and the number of parameters as compared to standard convolution operation while still maintaining representational efficiency. To show the effectiveness of our proposed convolution, we present extensive experimental results on the standard convolutional neural network (CNN) architectures such as VGG \cite{vgg2014very} and ResNet \cite{resnet}. We find that after replacing the standard convolutional filters in these architectures with our proposed HetConv filters, we achieve 3X to 8X FLOPs based improvement in speed while still maintaining (and sometimes improving) the accuracy. We also compare our proposed convolutions with group/depth wise convolutions and show that it achieves more FLOPs reduction with significantly higher accuracy.
Leveraging Filter Correlations for Deep Model Compression
Nov 26, 2018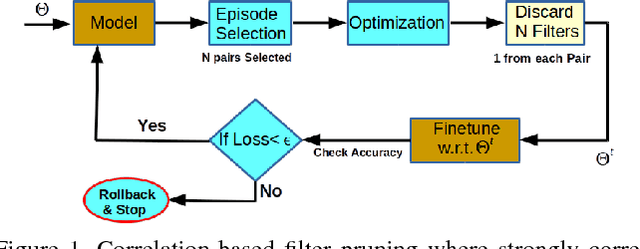
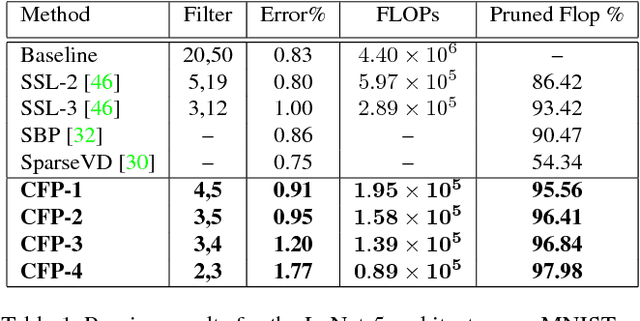
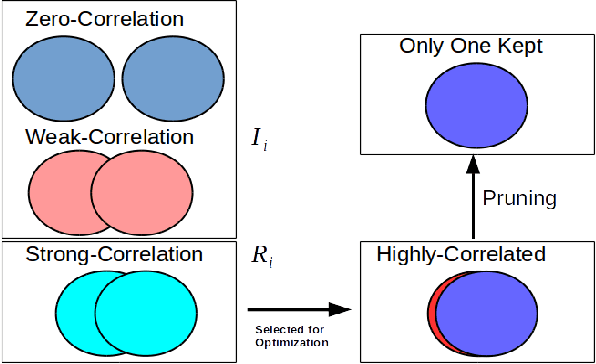
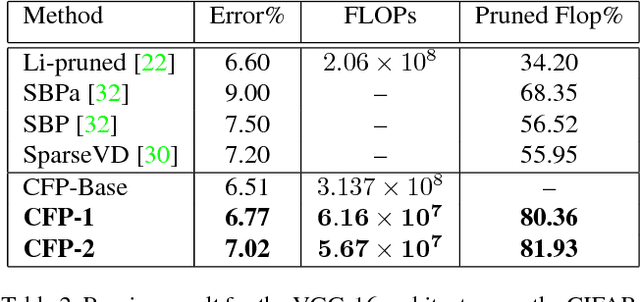
We present a filter correlation based model compression approach for deep convolutional neural networks. Our approach iteratively identifies pairs of filters with largest pairwise correlations and discards one of the filters from each such pair. However, instead of discarding one of the filter from such pairs na\"{i}vely, we further optimize the model so that the two filters from each such pair are as highly correlated as possible so that discarding one of the filters from the pairs results in as little information loss as possible. After discarding the filters in each round, we further finetune the model to recover from the potential small loss incurred by the compression. We evaluate our proposed approach using a comprehensive set of experiments and ablation studies. Our compression method yields state-of-the-art FLOPs compression rates on various benchmarks, such as LeNet-5, VGG-16, and ResNet-50,56, which are still achieving excellent predictive performance for tasks such as object detection on benchmark datasets.
Graph Convolutional Networks based Word Embeddings
Sep 12, 2018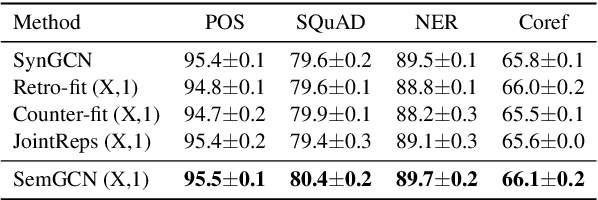
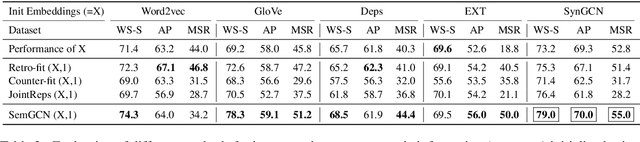
Recently, word embeddings have been widely adopted across several NLP applications. However, most word embedding methods solely rely on linear context and do not provide a framework for incorporating word relationships like hypernym, nmod in a principled manner. In this paper, we propose WordGCN, a Graph Convolution based word representation learning approach which provides a framework for exploiting multiple types of word relationships. WordGCN operates at sentence as well as corpus level and allows to incorporate dependency parse based context in an efficient manner without increasing the vocabulary size. To the best of our knowledge, this is the first approach which effectively incorporates word relationships via Graph Convolutional Networks for learning word representations. Through extensive experiments on various intrinsic and extrinsic tasks, we demonstrate WordGCN's effectiveness over existing word embedding approaches. We make WordGCN's source code available to encourage reproducible research.