 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaguna M.1/XS.2 Technical Report
May 26, 2026We present Laguna M.1 and Laguna XS.2, two Mixture-of-Experts foundation models built for long-horizon, agentic coding: M.1 has $225.8$B total parameters ($23.4$B activated per token) and XS.2 has $33.4$B total ($3$B activated). Both models were trained from scratch end-to-end inside the same internal system that we refer to as our Model Factory: a tightly-integrated stack of versioned data, training, evaluation, and inference components that turn model development into an industrial process. We describe the principles and design choices of the Model Factory and also detail the end-to-end training process of our models, throughout pre-training data and architecture, post-training stages, evaluation, and quantization. On agentic software engineering and terminal benchmarks (SWE-bench Verified, SWE-bench Multilingual, SWE-Bench Pro, and Terminal-Bench 2.0) M.1 and XS.2 are competitive with state-of-the-art open models in their respective weight classes. Laguna XS.2 weights are released under Apache~2.0 at https://huggingface.co/collections/poolside/laguna-xs2.
Bandit problems with fidelity rewards
Nov 25, 2021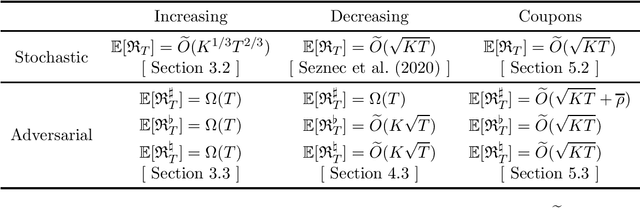



The fidelity bandits problem is a variant of the $K$-armed bandit problem in which the reward of each arm is augmented by a fidelity reward that provides the player with an additional payoff depending on how 'loyal' the player has been to that arm in the past. We propose two models for fidelity. In the loyalty-points model the amount of extra reward depends on the number of times the arm has previously been played. In the subscription model the additional reward depends on the current number of consecutive draws of the arm. We consider both stochastic and adversarial problems. Since single-arm strategies are not always optimal in stochastic problems, the notion of regret in the adversarial setting needs careful adjustment. We introduce three possible notions of regret and investigate which can be bounded sublinearly. We study in detail the special cases of increasing, decreasing and coupon (where the player gets an additional reward after every $m$ plays of an arm) fidelity rewards. For the models which do not necessarily enjoy sublinear regret, we provide a worst case lower bound. For those models which exhibit sublinear regret, we provide algorithms and bound their regret.
Untangling Local and Global Deformations in Deep Convolutional Networks for Image Classification and Sliding Window Detection
Nov 30, 2014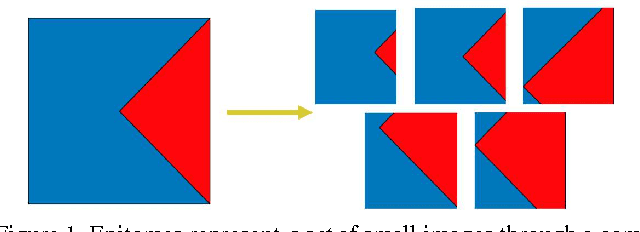
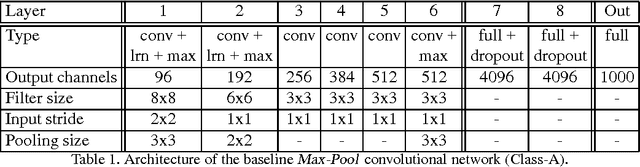
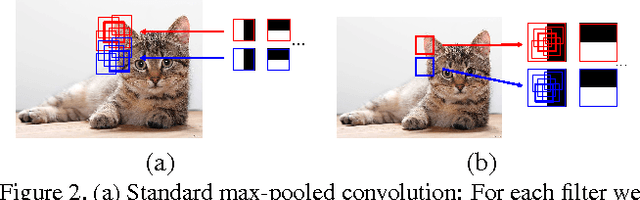
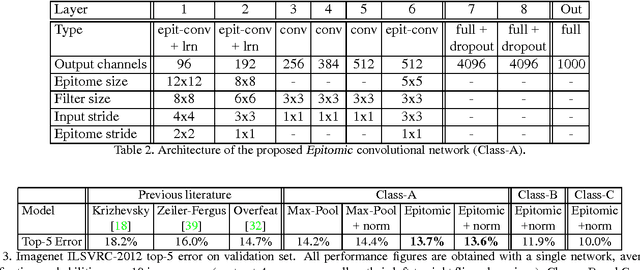
Deep Convolutional Neural Networks (DCNNs) commonly use generic `max-pooling' (MP) layers to extract deformation-invariant features, but we argue in favor of a more refined treatment. First, we introduce epitomic convolution as a building block alternative to the common convolution-MP cascade of DCNNs; while having identical complexity to MP, Epitomic Convolution allows for parameter sharing across different filters, resulting in faster convergence and better generalization. Second, we introduce a Multiple Instance Learning approach to explicitly accommodate global translation and scaling when training a DCNN exclusively with class labels. For this we rely on a `patchwork' data structure that efficiently lays out all image scales and positions as candidates to a DCNN. Factoring global and local deformations allows a DCNN to `focus its resources' on the treatment of non-rigid deformations and yields a substantial classification accuracy improvement. Third, further pursuing this idea, we develop an efficient DCNN sliding window object detector that employs explicit search over position, scale, and aspect ratio. We provide competitive image classification and localization results on the ImageNet dataset and object detection results on the Pascal VOC 2007 benchmark.