 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirect Dynamic Retargeting for Humanoid Imitation Learning from Videos
May 22, 2026Imitation Learning from monocular video demonstrations provides a scalable approach for teaching complex skills to humanoid robots. However, translating human motion to humanoids requires overcoming significant morphological mismatches. Standard approaches rely on Geometric Retargeting or Indirect Dynamic Retargeting pipelines. We identify that these intermediate kinematic projections introduce a geometric bias, restricting the search space and yielding suboptimal dynamic behaviors. In this paper, we propose Direct Dynamic Retargeting (DDR), a novel single-stage framework that generates high-fidelity, dynamically feasible trajectories directly from expert videos. By formulating the problem in the task space and leveraging a sampling-based Model Predictive Control solver within a physics simulator, DDR natively optimizes over complex contact sequences while mitigating input drift. Our experiments demonstrate that bypassing the geometric bias allows DDR to outperform state-of-the-art baselines in demonstration tracking accuracy. Furthermore, we establish that providing such physically viable references to RL agents accelerates training convergence and enhances the final execution of agile and balancing behaviors. Source code will be made publicly available.
CaT: Constraints as Terminations for Legged Locomotion Reinforcement Learning
Mar 27, 2024



Deep Reinforcement Learning (RL) has demonstrated impressive results in solving complex robotic tasks such as quadruped locomotion. Yet, current solvers fail to produce efficient policies respecting hard constraints. In this work, we advocate for integrating constraints into robot learning and present Constraints as Terminations (CaT), a novel constrained RL algorithm. Departing from classical constrained RL formulations, we reformulate constraints through stochastic terminations during policy learning: any violation of a constraint triggers a probability of terminating potential future rewards the RL agent could attain. We propose an algorithmic approach to this formulation, by minimally modifying widely used off-the-shelf RL algorithms in robot learning (such as Proximal Policy Optimization). Our approach leads to excellent constraint adherence without introducing undue complexity and computational overhead, thus mitigating barriers to broader adoption. Through empirical evaluation on the real quadruped robot Solo crossing challenging obstacles, we demonstrate that CaT provides a compelling solution for incorporating constraints into RL frameworks. Videos and code are available at https://constraints-as-terminations.github.io.
How do walkers avoid a mobile robot crossing their way?
Sep 26, 2016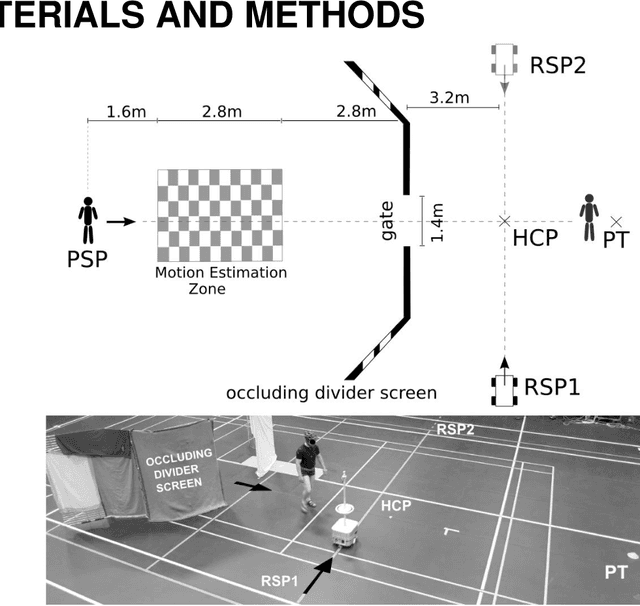
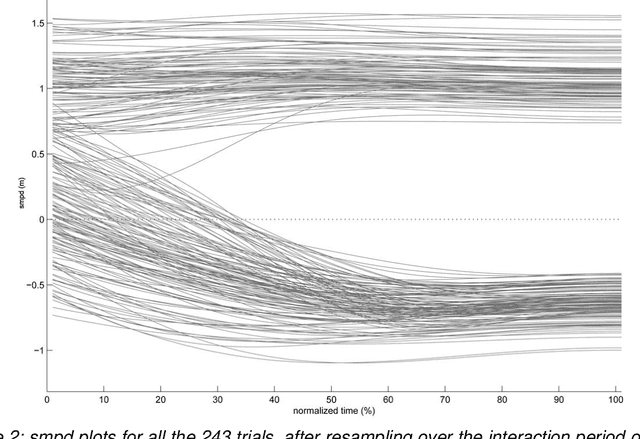
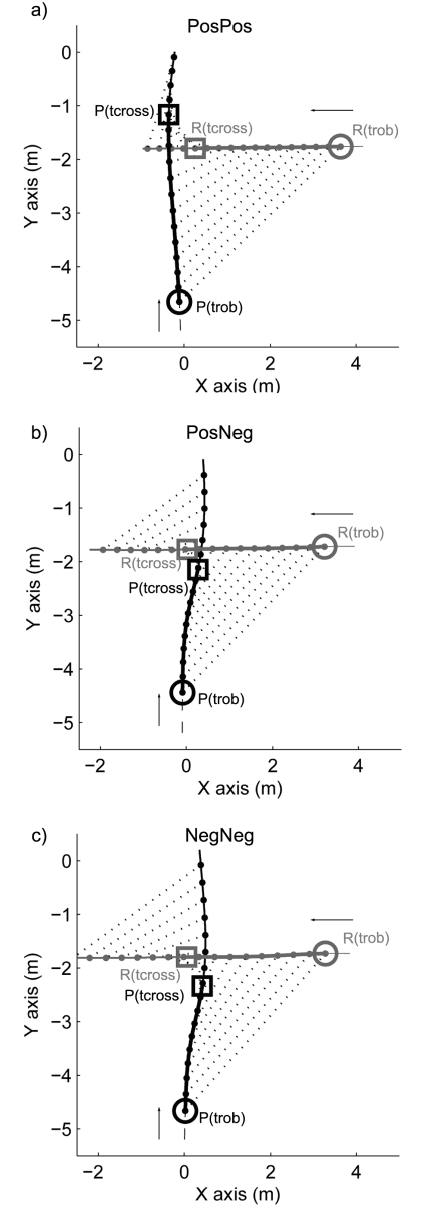
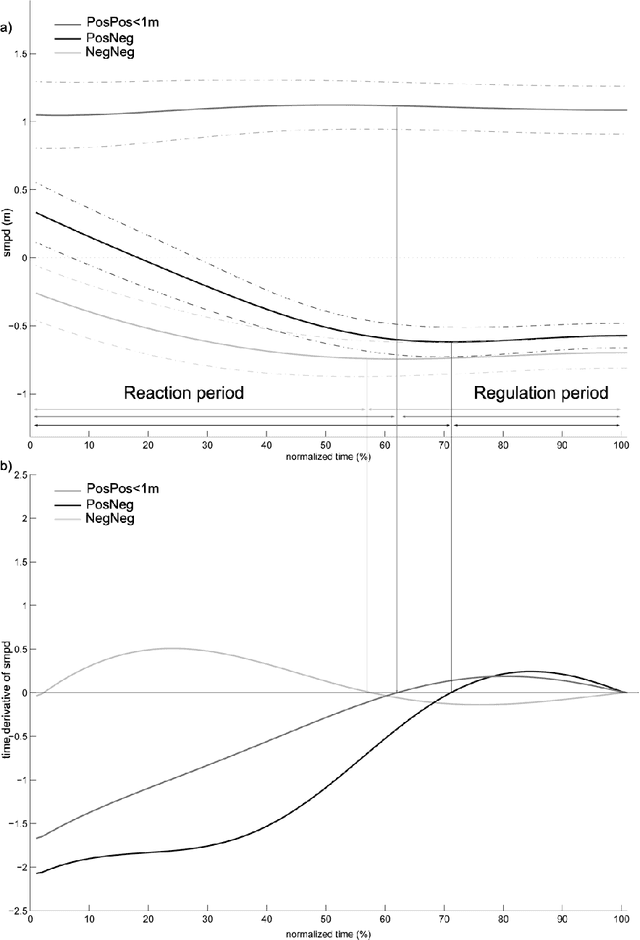
Robots and Humans have to share the same environment more and more often. In the aim of steering robots in a safe and convenient manner among humans it is required to understand how humans interact with them. This work focuses on collision avoidance between a human and a robot during locomotion. Having in mind previous results on human obstacle avoidance, as well as the description of the main principles which guide collision avoidance strategies, we observe how humans adapt a goal-directed locomotion task when they have to interfere with a mobile robot. Our results show differences in the strategy set by humans to avoid a robot in comparison with avoiding another human. Humans prefer to give the way to the robot even when they are likely to pass first at the beginning of the interaction.