 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuality assessment of 3D human animation: Subjective and objective evaluation
May 29, 2025Virtual human animations have a wide range of applications in virtual and augmented reality. While automatic generation methods of animated virtual humans have been developed, assessing their quality remains challenging. Recently, approaches introducing task-oriented evaluation metrics have been proposed, leveraging neural network training. However, quality assessment measures for animated virtual humans that are not generated with parametric body models have yet to be developed. In this context, we introduce a first such quality assessment measure leveraging a novel data-driven framework. First, we generate a dataset of virtual human animations together with their corresponding subjective realism evaluation scores collected with a user study. Second, we use the resulting dataset to learn predicting perceptual evaluation scores. Results indicate that training a linear regressor on our dataset results in a correlation of 90%, which outperforms a state of the art deep learning baseline.
Correspondence-free online human motion retargeting
Feb 01, 2023



We present a novel data-driven framework for unsupervised human motion retargeting which animates a target body shape with a source motion. This allows to retarget motions between different characters by animating a target subject with a motion of a source subject. Our method is correspondence-free,~\ie neither spatial correspondences between the source and target shapes nor temporal correspondences between different frames of the source motion are required. Our proposed method directly animates a target shape with arbitrary sequences of humans in motion, possibly captured using 4D acquisition platforms or consumer devices. Our framework takes into account long-term temporal context of $1$ second during retargeting while accounting for surface details. To achieve this, we take inspiration from two lines of existing work: skeletal motion retargeting, which leverages long-term temporal context at the cost of surface detail, and surface-based retargeting, which preserves surface details without considering long-term temporal context. We unify the advantages of these works by combining a learnt skinning field with a skeletal retargeting approach. During inference, our method runs online,~\ie the input can be processed in a serial way, and retargeting is performed in a single forward pass per frame. Experiments show that including long-term temporal context during training improves the method's accuracy both in terms of the retargeted skeletal motion and the detail preservation. Furthermore, our method generalizes well on unobserved motions and body shapes. We demonstrate that the proposed framework achieves state-of-the-art results on two test datasets.
How do walkers avoid a mobile robot crossing their way?
Sep 26, 2016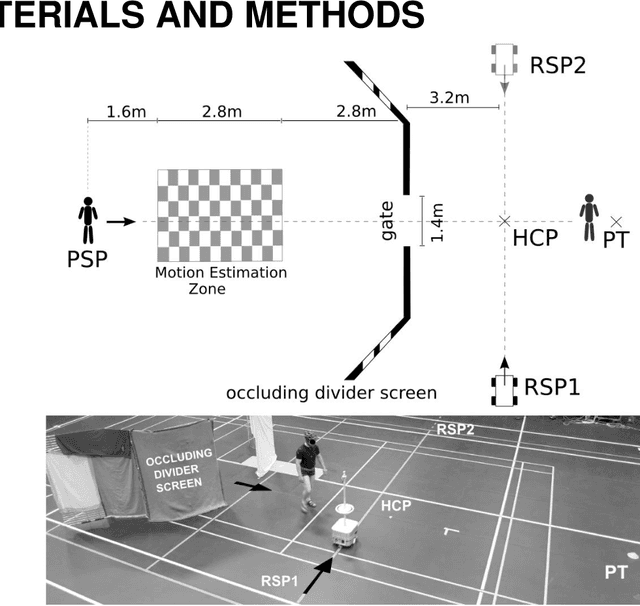
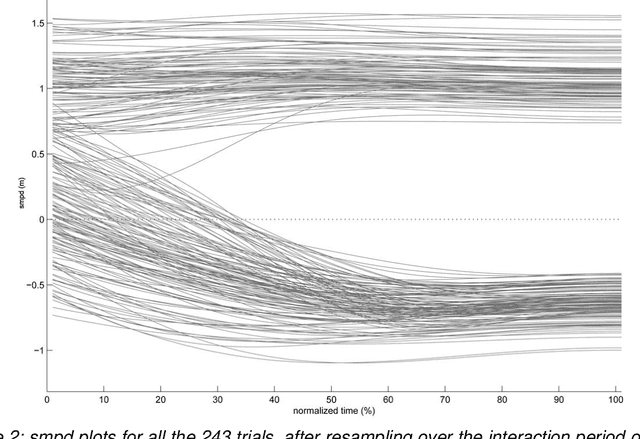
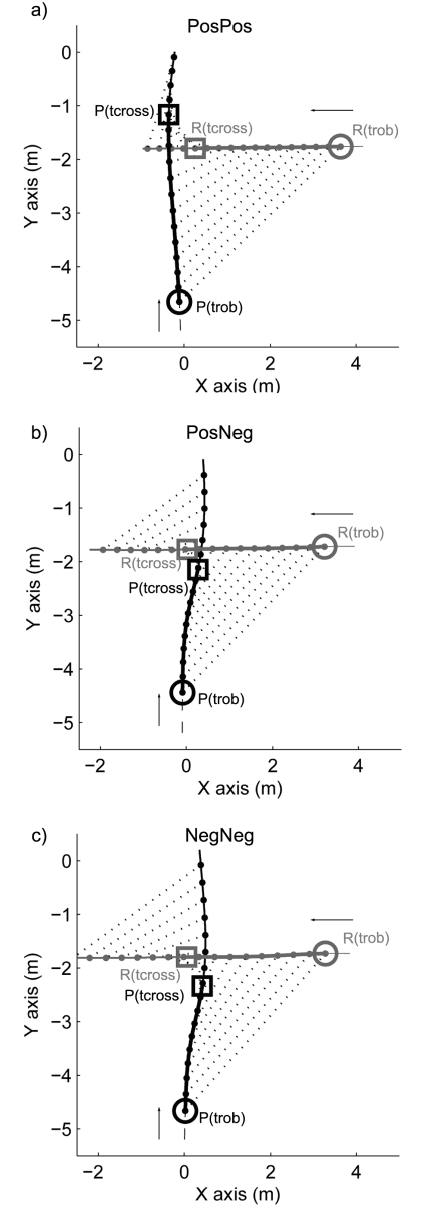
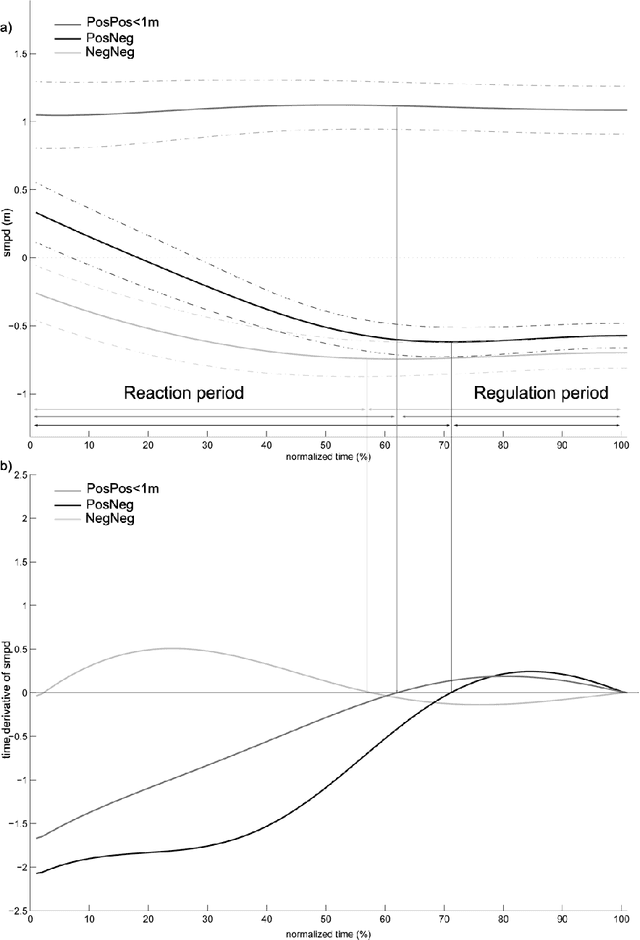
Robots and Humans have to share the same environment more and more often. In the aim of steering robots in a safe and convenient manner among humans it is required to understand how humans interact with them. This work focuses on collision avoidance between a human and a robot during locomotion. Having in mind previous results on human obstacle avoidance, as well as the description of the main principles which guide collision avoidance strategies, we observe how humans adapt a goal-directed locomotion task when they have to interfere with a mobile robot. Our results show differences in the strategy set by humans to avoid a robot in comparison with avoiding another human. Humans prefer to give the way to the robot even when they are likely to pass first at the beginning of the interaction.