 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Robust and Multilingual Speech Representations
Jan 29, 2020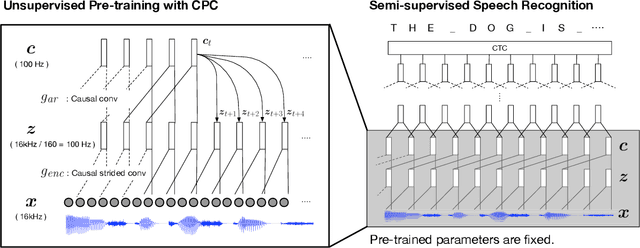
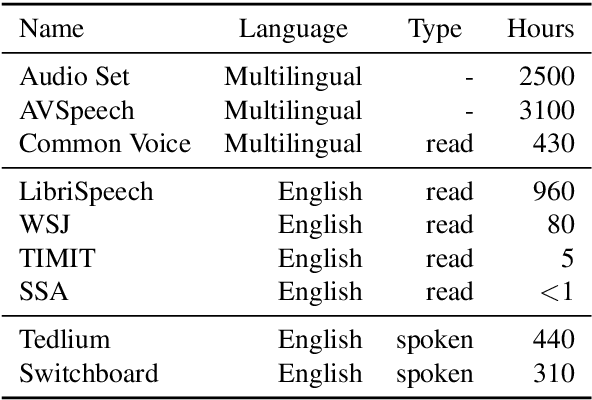
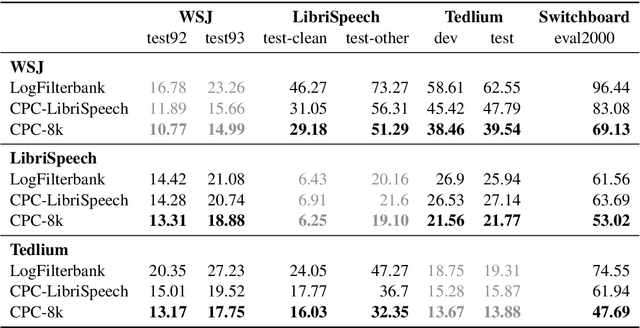
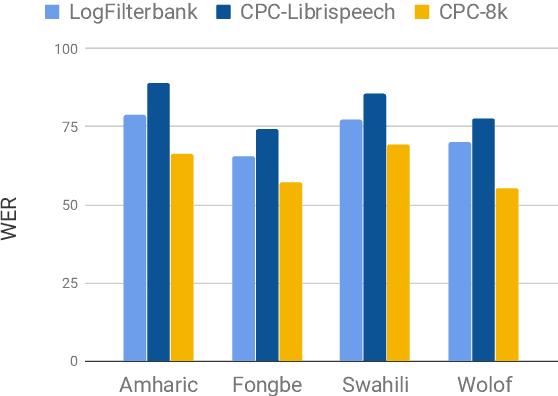
Unsupervised speech representation learning has shown remarkable success at finding representations that correlate with phonetic structures and improve downstream speech recognition performance. However, most research has been focused on evaluating the representations in terms of their ability to improve the performance of speech recognition systems on read English (e.g. Wall Street Journal and LibriSpeech). This evaluation methodology overlooks two important desiderata that speech representations should have: robustness to domain shifts and transferability to other languages. In this paper we learn representations from up to 8000 hours of diverse and noisy speech data and evaluate the representations by looking at their robustness to domain shifts and their ability to improve recognition performance in many languages. We find that our representations confer significant robustness advantages to the resulting recognition systems: we see significant improvements in out-of-domain transfer relative to baseline feature sets and the features likewise provide improvements in 25 phonetically diverse languages including tonal languages and low-resource languages.
Can I Trust the Explainer? Verifying Post-hoc Explanatory Methods
Oct 09, 2019


For AI systems to garner widespread public acceptance, we must develop methods capable of explaining the decisions of black-box models such as neural networks. In this work, we identify two issues of current explanatory methods. First, we show that two prevalent perspectives on explanations---feature-additivity and feature-selection---lead to fundamentally different instance-wise explanations. In the literature, explainers from different perspectives are currently being directly compared, despite their distinct explanation goals. The second issue is that current post-hoc explainers have only been thoroughly validated on simple models, such as linear regression, and, when applied to real-world neural networks, explainers are commonly evaluated under the assumption that the learned models behave reasonably. However, neural networks often rely on unreasonable correlations, even when producing correct decisions. We introduce a verification framework for explanatory methods under the feature-selection perspective. Our framework is based on a non-trivial neural network architecture trained on a real-world task, and for which we are able to provide guarantees on its inner workings. We validate the efficacy of our evaluation by showing the failure modes of current explainers. We aim for this framework to provide a publicly available, off-the-shelf evaluation when the feature-selection perspective on explanations is needed.
Make Up Your Mind! Adversarial Generation of Inconsistent Natural Language Explanations
Oct 09, 2019
To increase trust in artificial intelligence systems, a growing amount of works are enhancing these systems with the capability of producing natural language explanations that support their predictions. In this work, we show that such appealing frameworks are nonetheless prone to generating inconsistent explanations, such as "A dog is an animal" and "A dog is not an animal", which are likely to decrease users' trust in these systems. To detect such inconsistencies, we introduce a simple but effective adversarial framework for generating a complete target sequence, a scenario that has not been addressed so far. Finally, we apply our framework to a state-of-the-art neural model that provides natural language explanations on SNLI, and we show that this model is capable of generating a significant amount of inconsistencies.
Putting Machine Translation in Context with the Noisy Channel Model
Oct 01, 2019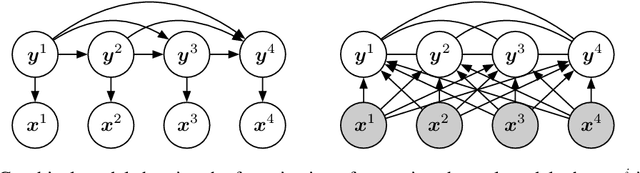
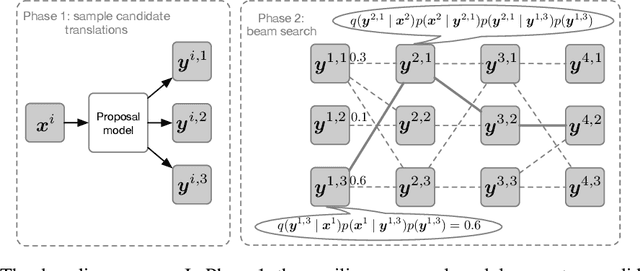

We show that Bayes' rule provides a compelling mechanism for controlling unconditional document language models, using the long-standing challenge of effectively leveraging document context in machine translation. In our formulation, we estimate the probability of a candidate translation as the product of the unconditional probability of the candidate output document and the ``reverse translation probability'' of translating the candidate output back into the input source language document---the so-called ``noisy channel'' decomposition. A particular advantage of our model is that it requires only parallel sentences to train, rather than parallel documents, which are not always available. Using a new beam search reranking approximation to solve the decoding problem, we find that document language models outperform language models that assume independence between sentences, and that using either a document or sentence language model outperforms comparable models that directly estimate the translation probability. We obtain the best-published results on the NIST Chinese--English translation task, a standard task for evaluating document translation. Our model also outperforms the benchmark Transformer model by approximately 2.5 BLEU on the WMT19 Chinese--English translation task.
A Critical Analysis of Biased Parsers in Unsupervised Parsing
Sep 20, 2019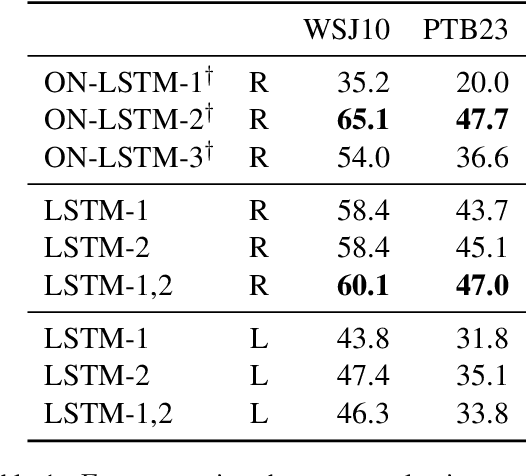
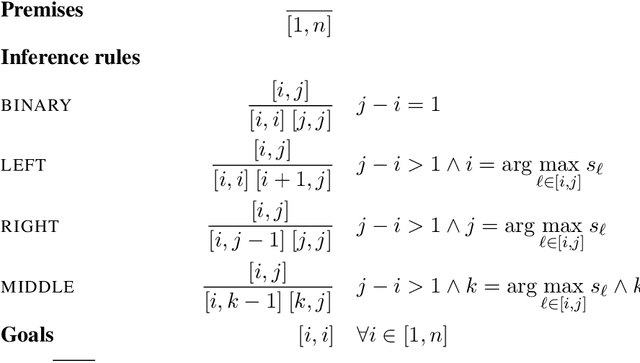
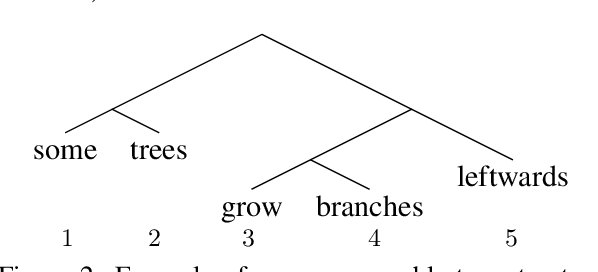

A series of recent papers has used a parsing algorithm due to Shen et al. (2018) to recover phrase-structure trees based on proxies for "syntactic depth." These proxy depths are obtained from the representations learned by recurrent language models augmented with mechanisms that encourage the (unsupervised) discovery of hierarchical structure latent in natural language sentences. Using the same parser, we show that proxies derived from a conventional LSTM language model produce trees comparably well to the specialized architectures used in previous work. However, we also provide a detailed analysis of the parsing algorithm, showing (1) that it is incomplete---that is, it can recover only a fraction of possible trees---and (2) that it has a marked bias for right-branching structures which results in inflated performance in right-branching languages like English. Our analysis shows that evaluating with biased parsing algorithms can inflate the apparent structural competence of language models.
Mogrifier LSTM
Sep 04, 2019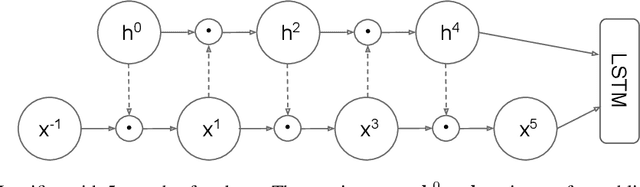
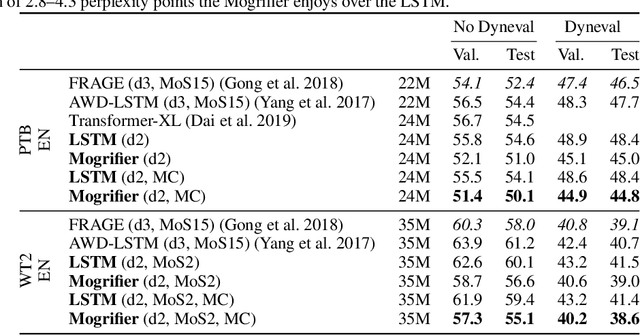
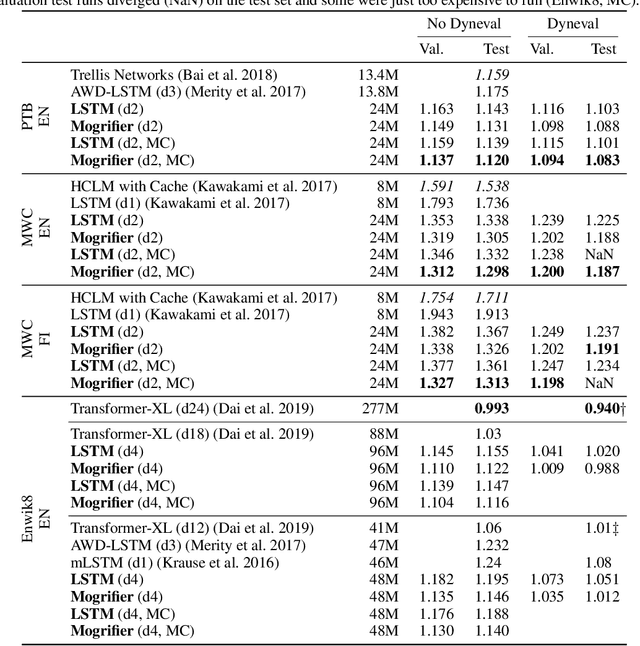
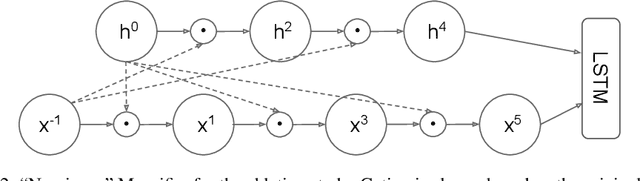
Many advances in Natural Language Processing have been based upon more expressive models for how inputs interact with the context in which they occur. Recurrent networks, which have enjoyed a modicum of success, still lack the generalization and systematicity ultimately required for modelling language. In this work, we propose an extension to the venerable Long Short-Term Memory in the form of mutual gating of the current input and the previous output. This mechanism affords the modelling of a richer space of interactions between inputs and their context. Equivalently, our model can be viewed as making the transition function given by the LSTM context-dependent. Experiments demonstrate markedly improved generalization on language modelling in the range of 3-4 perplexity points on Penn Treebank and Wikitext-2, and 0.01-0.05 bpc on four character-based datasets. We establish a new state of the art on all datasets with the exception of Enwik8, where we close a large gap between the LSTM and Transformer models.
WikiCREM: A Large Unsupervised Corpus for Coreference Resolution
Aug 23, 2019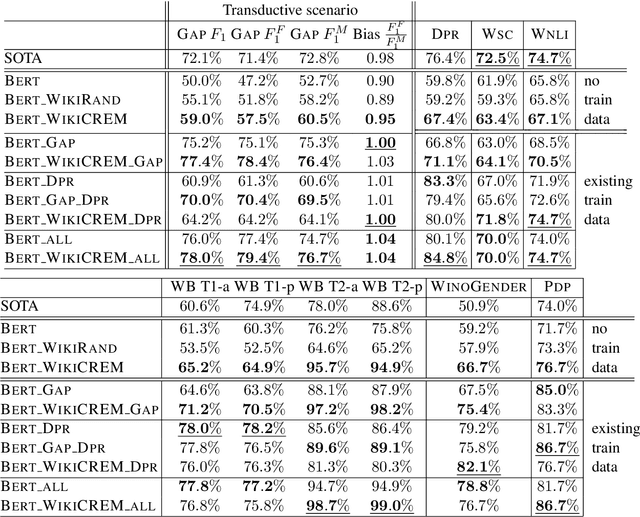
Pronoun resolution is a major area of natural language understanding. However, large-scale training sets are still scarce, since manually labelling data is costly. In this work, we introduce WikiCREM (Wikipedia CoREferences Masked) a large-scale, yet accurate dataset of pronoun disambiguation instances. We use a language-model-based approach for pronoun resolution in combination with our WikiCREM dataset. We compare a series of models on a collection of diverse and challenging coreference resolution problems, where we match or outperform previous state-of-the-art approaches on 6 out of 7 datasets, such as GAP, DPR, WNLI, PDP, WinoBias, and WinoGender. We release our model to be used off-the-shelf for solving pronoun disambiguation.
Scalable Syntax-Aware Language Models Using Knowledge Distillation
Jun 14, 2019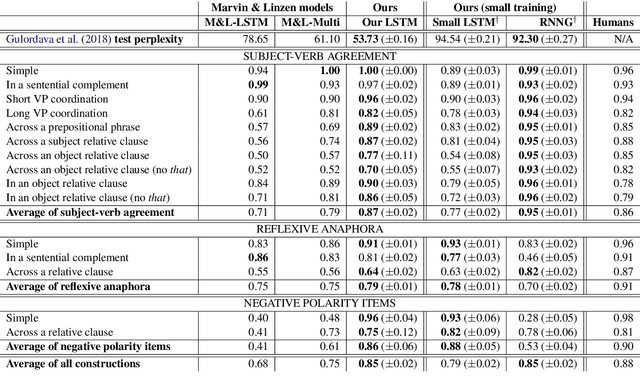
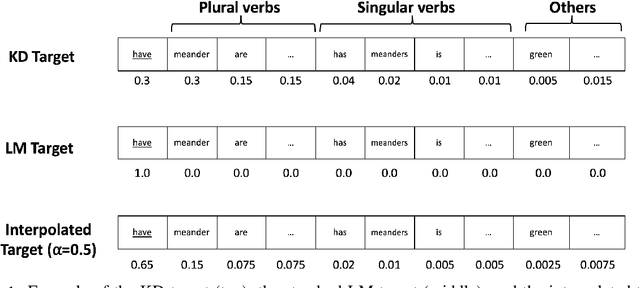
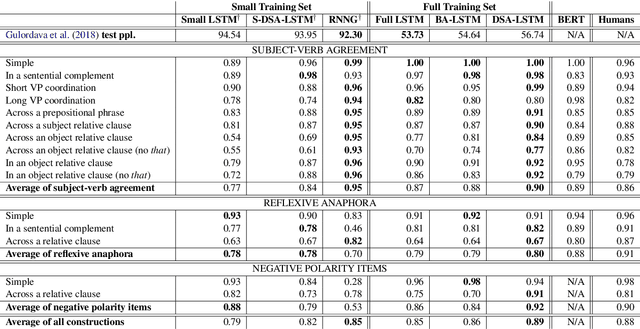
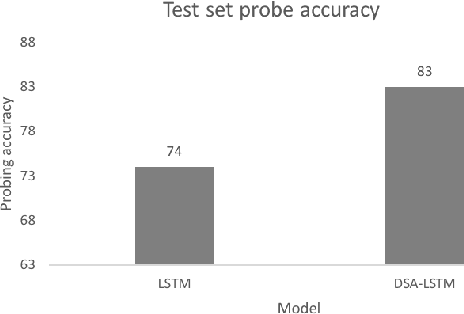
Prior work has shown that, on small amounts of training data, syntactic neural language models learn structurally sensitive generalisations more successfully than sequential language models. However, their computational complexity renders scaling difficult, and it remains an open question whether structural biases are still necessary when sequential models have access to ever larger amounts of training data. To answer this question, we introduce an efficient knowledge distillation (KD) technique that transfers knowledge from a syntactic language model trained on a small corpus to an LSTM language model, hence enabling the LSTM to develop a more structurally sensitive representation of the larger training data it learns from. On targeted syntactic evaluations, we find that, while sequential LSTMs perform much better than previously reported, our proposed technique substantially improves on this baseline, yielding a new state of the art. Our findings and analysis affirm the importance of structural biases, even in models that learn from large amounts of data.
Learning and Evaluating General Linguistic Intelligence
Jan 31, 2019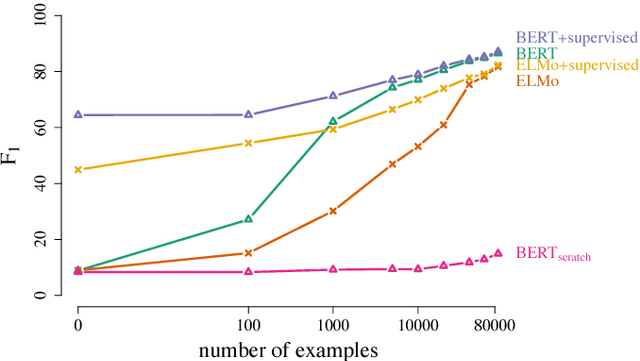
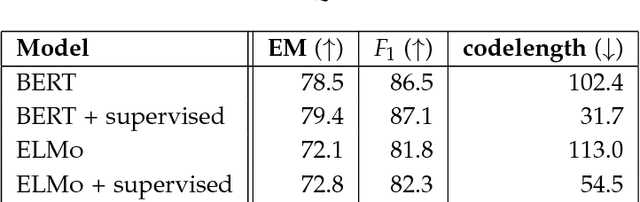
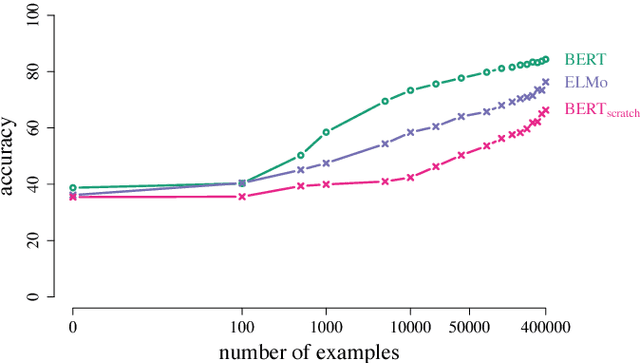

We define general linguistic intelligence as the ability to reuse previously acquired knowledge about a language's lexicon, syntax, semantics, and pragmatic conventions to adapt to new tasks quickly. Using this definition, we analyze state-of-the-art natural language understanding models and conduct an extensive empirical investigation to evaluate them against these criteria through a series of experiments that assess the task-independence of the knowledge being acquired by the learning process. In addition to task performance, we propose a new evaluation metric based on an online encoding of the test data that quantifies how quickly an existing agent (model) learns a new task. Our results show that while the field has made impressive progress in terms of model architectures that generalize to many tasks, these models still require a lot of in-domain training examples (e.g., for fine tuning, training task-specific modules), and are prone to catastrophic forgetting. Moreover, we find that far from solving general tasks (e.g., document question answering), our models are overfitting to the quirks of particular datasets (e.g., SQuAD). We discuss missing components and conjecture on how to make progress toward general linguistic intelligence.
e-SNLI: Natural Language Inference with Natural Language Explanations
Dec 06, 2018
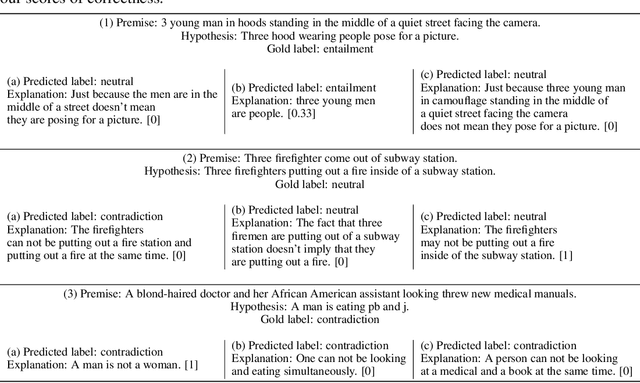
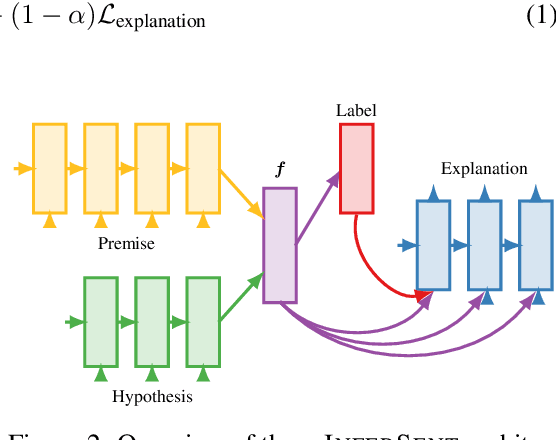

In order for machine learning to garner widespread public adoption, models must be able to provide interpretable and robust explanations for their decisions, as well as learn from human-provided explanations at train time. In this work, we extend the Stanford Natural Language Inference dataset with an additional layer of human-annotated natural language explanations of the entailment relations. We further implement models that incorporate these explanations into their training process and output them at test time. We show how our corpus of explanations, which we call e-SNLI, can be used for various goals, such as obtaining full sentence justifications of a model's decisions, improving universal sentence representations and transferring to out-of-domain NLI datasets. Our dataset thus opens up a range of research directions for using natural language explanations, both for improving models and for asserting their trust.