 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelational Memory Augmented Language Models
Jan 24, 2022We present a memory-augmented approach to condition an autoregressive language model on a knowledge graph. We represent the graph as a collection of relation triples and retrieve relevant relations for a given context to improve text generation. Experiments on WikiText-103, WMT19, and enwik8 English datasets demonstrate that our approach produces a better language model in terms of perplexity and bits per character. We also show that relational memory improves coherence, is complementary to token-based memory, and enables causal interventions. Our model provides a simple yet effective way to combine an autoregressive language model with a knowledge graph for a more coherent and logical generation.
A Systematic Investigation of Commonsense Understanding in Large Language Models
Oct 31, 2021
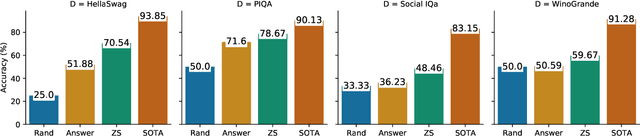

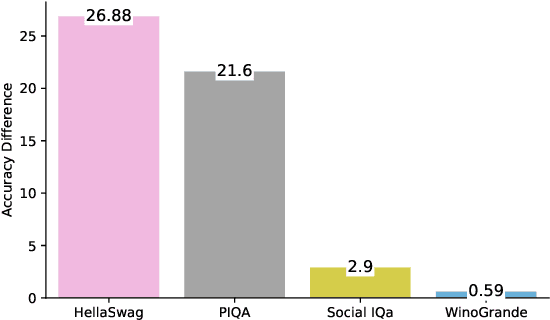
Large language models have shown impressive performance on many natural language processing (NLP) tasks in a zero-shot setting. We ask whether these models exhibit commonsense understanding -- a critical component of NLP applications -- by evaluating models against four commonsense benchmarks. We find that the impressive zero-shot performance of large language models is mostly due to existence of dataset bias in our benchmarks. We also show that the zero-shot performance is sensitive to the choice of hyper-parameters and similarity of the benchmark to the pre-training datasets. Moreover, we did not observe substantial improvements when evaluating models in a few-shot setting. Finally, in contrast to previous work, we find that leveraging explicit commonsense knowledge does not yield substantial improvement.
Pretraining the Noisy Channel Model for Task-Oriented Dialogue
Mar 18, 2021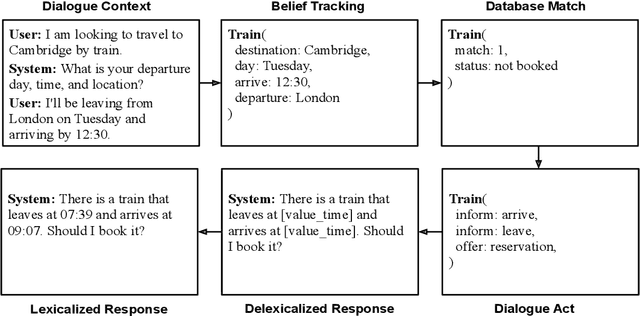

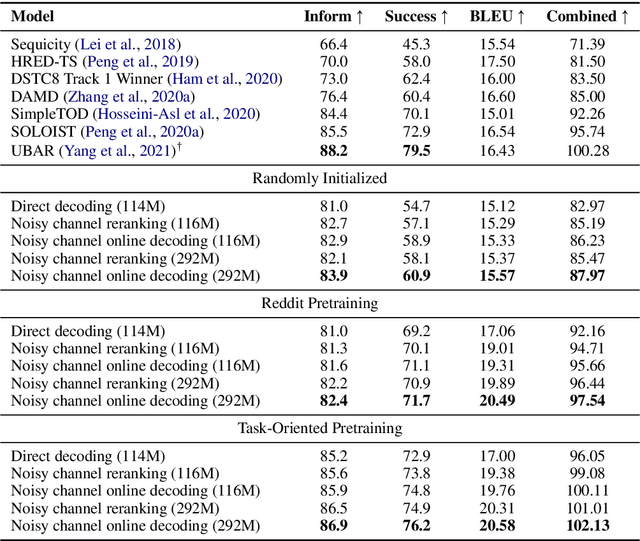
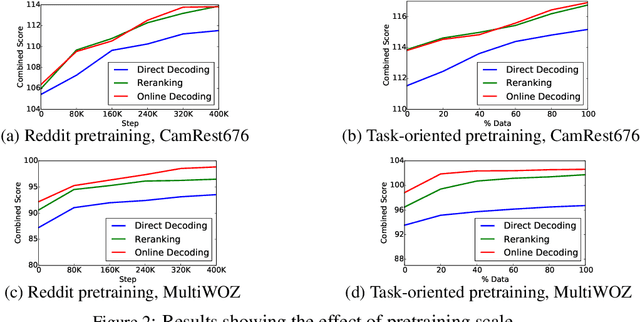
Direct decoding for task-oriented dialogue is known to suffer from the explaining-away effect, manifested in models that prefer short and generic responses. Here we argue for the use of Bayes' theorem to factorize the dialogue task into two models, the distribution of the context given the response, and the prior for the response itself. This approach, an instantiation of the noisy channel model, both mitigates the explaining-away effect and allows the principled incorporation of large pretrained models for the response prior. We present extensive experiments showing that a noisy channel model decodes better responses compared to direct decoding and that a two stage pretraining strategy, employing both open-domain and task-oriented dialogue data, improves over randomly initialized models.
Pitfalls of Static Language Modelling
Feb 03, 2021
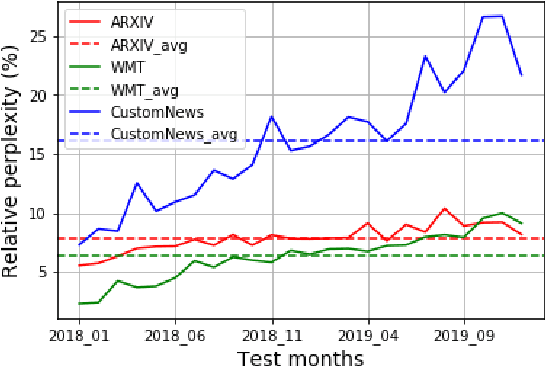
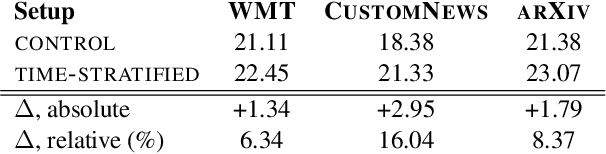
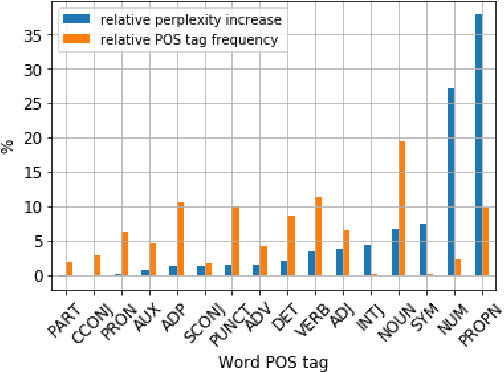
Our world is open-ended, non-stationary and constantly evolving; thus what we talk about and how we talk about it changes over time. This inherent dynamic nature of language comes in stark contrast to the current static language modelling paradigm, which constructs training and evaluation sets from overlapping time periods. Despite recent progress, we demonstrate that state-of-the-art Transformer models perform worse in the realistic setup of predicting future utterances from beyond their training period -- a consistent pattern across three datasets from two domains. We find that, while increasing model size alone -- a key driver behind recent progress -- does not provide a solution for the temporal generalization problem, having models that continually update their knowledge with new information can indeed slow down the degradation over time. Hence, given the compilation of ever-larger language modelling training datasets, combined with the growing list of language-model-based NLP applications that require up-to-date knowledge about the world, we argue that now is the right time to rethink our static language modelling evaluation protocol, and develop adaptive language models that can remain up-to-date with respect to our ever-changing and non-stationary world.
Mutual Information Constraints for Monte-Carlo Objectives
Dec 01, 2020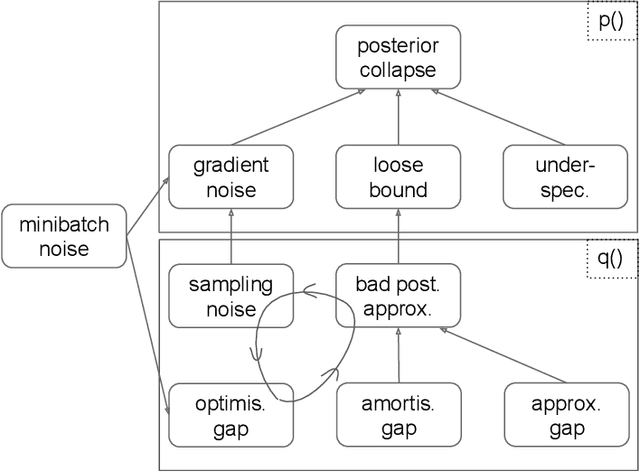
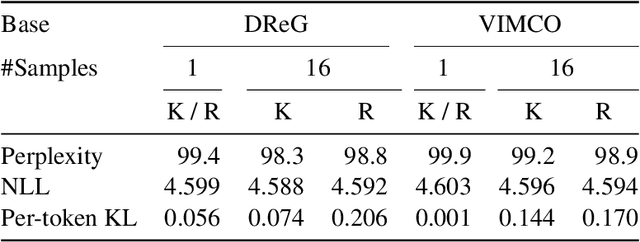
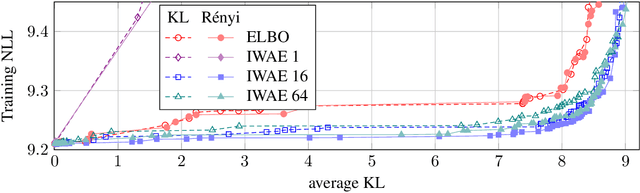
A common failure mode of density models trained as variational autoencoders is to model the data without relying on their latent variables, rendering these variables useless. Two contributing factors, the underspecification of the model and the looseness of the variational lower bound, have been studied separately in the literature. We weave these two strands of research together, specifically the tighter bounds of Monte-Carlo objectives and constraints on the mutual information between the observable and the latent variables. Estimating the mutual information as the average Kullback-Leibler divergence between the easily available variational posterior $q(z|x)$ and the prior does not work with Monte-Carlo objectives because $q(z|x)$ is no longer a direct approximation to the model's true posterior $p(z|x)$. Hence, we construct estimators of the Kullback-Leibler divergence of the true posterior from the prior by recycling samples used in the objective, with which we train models of continuous and discrete latents at much improved rate-distortion and no posterior collapse. While alleviated, the tradeoff between modelling the data and using the latents still remains, and we urge for evaluating inference methods across a range of mutual information values.
The Struggles of Feature-Based Explanations: Shapley Values vs. Minimal Sufficient Subsets
Sep 23, 2020

For neural models to garner widespread public trust and ensure fairness, we must have human-intelligible explanations for their predictions. Recently, an increasing number of works focus on explaining the predictions of neural models in terms of the relevance of the input features. In this work, we show that feature-based explanations pose problems even for explaining trivial models. We show that, in certain cases, there exist at least two ground-truth feature-based explanations, and that, sometimes, neither of them is enough to provide a complete view of the decision-making process of the model. Moreover, we show that two popular classes of explainers, Shapley explainers and minimal sufficient subsets explainers, target fundamentally different types of ground-truth explanations, despite the apparently implicit assumption that explainers should look for one specific feature-based explanation. These findings bring an additional dimension to consider in both developing and choosing explainers.
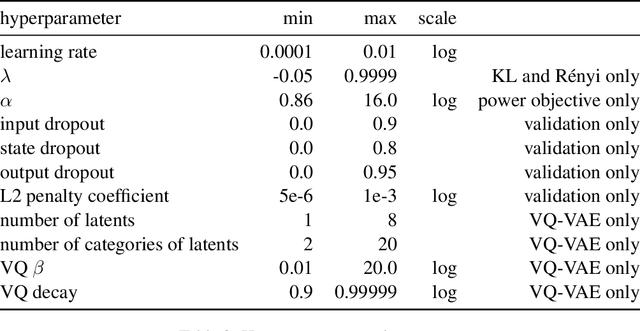
Syntactic Structure Distillation Pretraining For Bidirectional Encoders
May 27, 2020
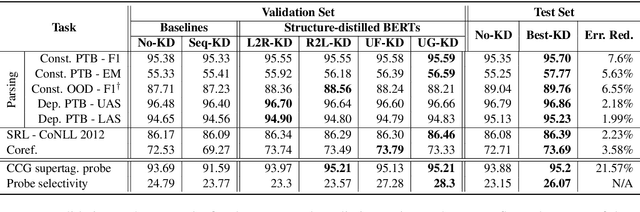
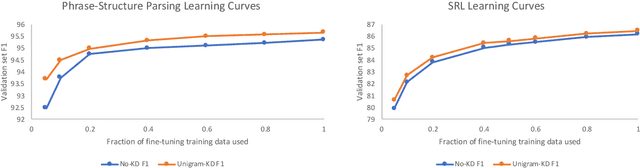
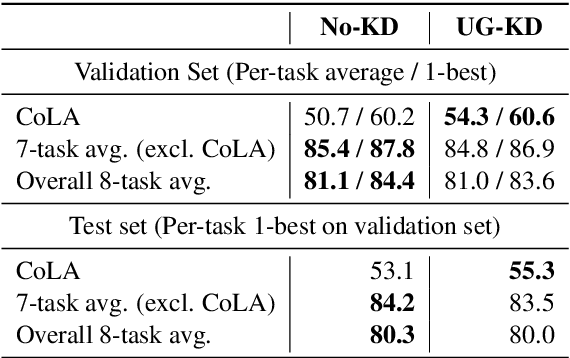
Textual representation learners trained on large amounts of data have achieved notable success on downstream tasks; intriguingly, they have also performed well on challenging tests of syntactic competence. Given this success, it remains an open question whether scalable learners like BERT can become fully proficient in the syntax of natural language by virtue of data scale alone, or whether they still benefit from more explicit syntactic biases. To answer this question, we introduce a knowledge distillation strategy for injecting syntactic biases into BERT pretraining, by distilling the syntactically informative predictions of a hierarchical---albeit harder to scale---syntactic language model. Since BERT models masked words in bidirectional context, we propose to distill the approximate marginal distribution over words in context from the syntactic LM. Our approach reduces relative error by 2-21% on a diverse set of structured prediction tasks, although we obtain mixed results on the GLUE benchmark. Our findings demonstrate the benefits of syntactic biases, even in representation learners that exploit large amounts of data, and contribute to a better understanding of where syntactic biases are most helpful in benchmarks of natural language understanding.
Learning to Segment Actions from Observation and Narration
May 07, 2020

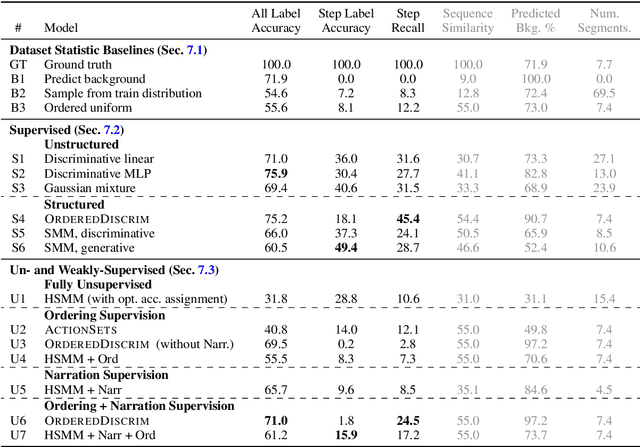
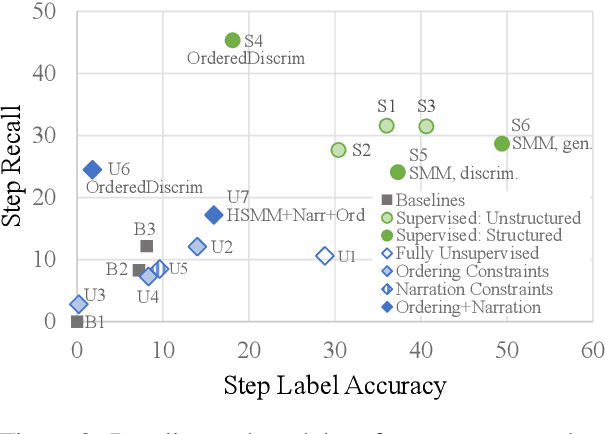
We apply a generative segmental model of task structure, guided by narration, to action segmentation in video. We focus on unsupervised and weakly-supervised settings where no action labels are known during training. Despite its simplicity, our model performs competitively with previous work on a dataset of naturalistic instructional videos. Our model allows us to vary the sources of supervision used in training, and we find that both task structure and narrative language provide large benefits in segmentation quality.
A Survey on Contextual Embeddings
Apr 13, 2020

Contextual embeddings, such as ELMo and BERT, move beyond global word representations like Word2Vec and achieve ground-breaking performance on a wide range of natural language processing tasks. Contextual embeddings assign each word a representation based on its context, thereby capturing uses of words across varied contexts and encoding knowledge that transfers across languages. In this survey, we review existing contextual embedding models, cross-lingual polyglot pre-training, the application of contextual embeddings in downstream tasks, model compression, and model analyses.
Visual Grounding in Video for Unsupervised Word Translation
Mar 26, 2020
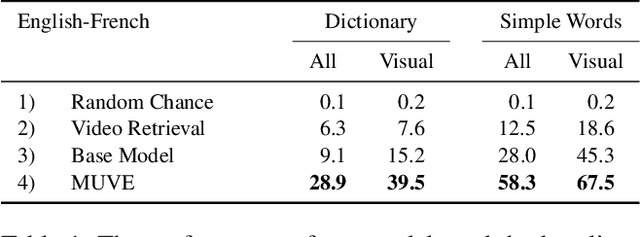
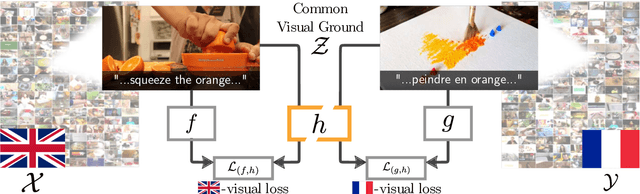
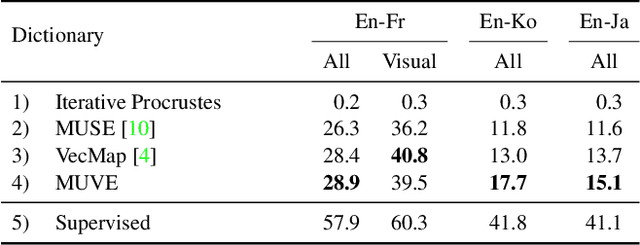
There are thousands of actively spoken languages on Earth, but a single visual world. Grounding in this visual world has the potential to bridge the gap between all these languages. Our goal is to use visual grounding to improve unsupervised word mapping between languages. The key idea is to establish a common visual representation between two languages by learning embeddings from unpaired instructional videos narrated in the native language. Given this shared embedding we demonstrate that (i) we can map words between the languages, particularly the 'visual' words; (ii) that the shared embedding provides a good initialization for existing unsupervised text-based word translation techniques, forming the basis for our proposed hybrid visual-text mapping algorithm, MUVE; and (iii) our approach achieves superior performance by addressing the shortcomings of text-based methods -- it is more robust, handles datasets with less commonality, and is applicable to low-resource languages. We apply these methods to translate words from English to French, Korean, and Japanese -- all without any parallel corpora and simply by watching many videos of people speaking while doing things.
* CVPR 2020