 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularization by Denoising via Fixed-Point Projection (RED-PRO)
Aug 01, 2020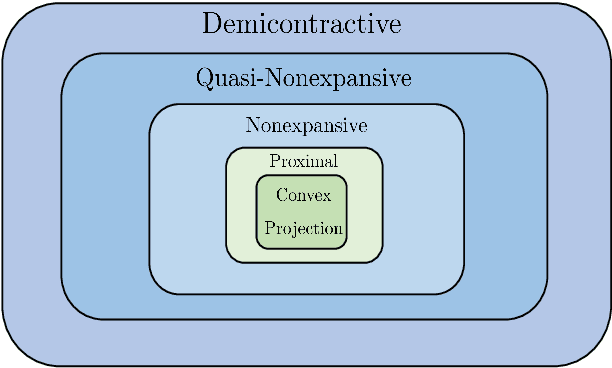
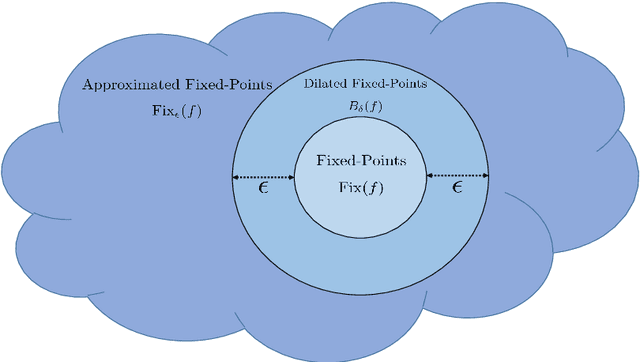
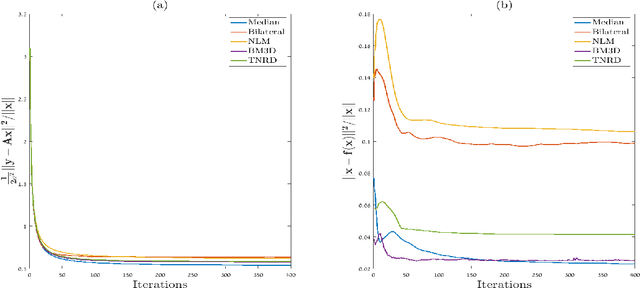
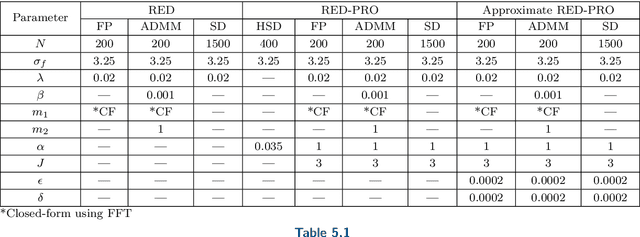
Inverse problems in image processing are typically cast as optimization tasks, consisting of data fidelity and stabilizing regularization terms. A recent regularization strategy of great interest utilizes the power of denoising engines. Two such methods are the Plug-and-Play Prior (PnP) and Regularization by Denoising (RED). While both have shown state-of-the-art results in various recovery tasks, their theoretical justification is incomplete. In this paper, we aim to enrich the understanding of RED and its connection to PnP. Towards that end, we reformulate RED as a convex optimization problem utilizing a projection (RED- PRO) onto the fixed-point set of demicontractive denoisers. We offer a simple iterative solution to this problem, and establish a novel unification of RED-PRO and PnP, while providing guarantees for their convergence to the globally optimal solution. We also present several relaxations of RED-PRO that allow for handling denoisers with limited fixed-point sets. Finally, we demonstrate RED-PRO for the tasks of image deblurring and super-resolution, showing improved results with respect to the original RED framework.
GIFnets: Differentiable GIF Encoding Framework
Jun 24, 2020
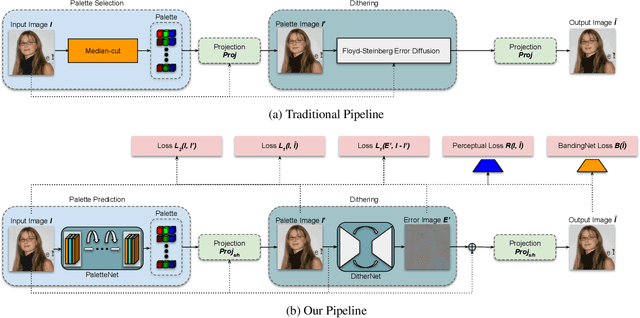
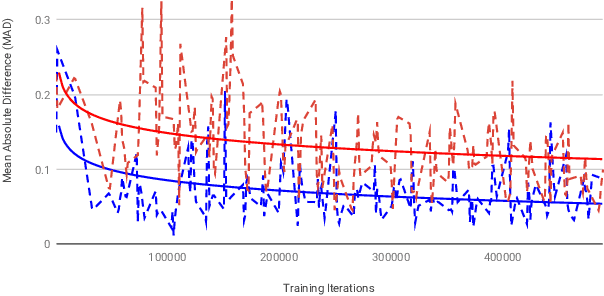
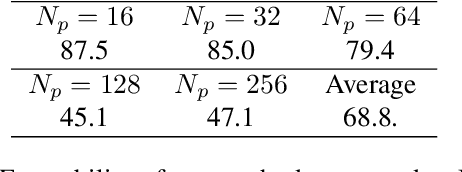
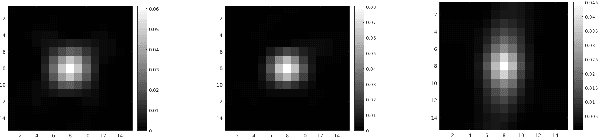
Graphics Interchange Format (GIF) is a widely used image file format. Due to the limited number of palette colors, GIF encoding often introduces color banding artifacts. Traditionally, dithering is applied to reduce color banding, but introducing dotted-pattern artifacts. To reduce artifacts and provide a better and more efficient GIF encoding, we introduce a differentiable GIF encoding pipeline, which includes three novel neural networks: PaletteNet, DitherNet, and BandingNet. Each of these three networks provides an important functionality within the GIF encoding pipeline. PaletteNet predicts a near-optimal color palette given an input image. DitherNet manipulates the input image to reduce color banding artifacts and provides an alternative to traditional dithering. Finally, BandingNet is designed to detect color banding, and provides a new perceptual loss specifically for GIF images. As far as we know, this is the first fully differentiable GIF encoding pipeline based on deep neural networks and compatible with existing GIF decoders. User study shows that our algorithm is better than Floyd-Steinberg based GIF encoding.
Creating High Resolution Images with a Latent Adversarial Generator
Mar 04, 2020



Generating realistic images is difficult, and many formulations for this task have been proposed recently. If we restrict the task to that of generating a particular class of images, however, the task becomes more tractable. That is to say, instead of generating an arbitrary image as a sample from the manifold of natural images, we propose to sample images from a particular "subspace" of natural images, directed by a low-resolution image from the same subspace. The problem we address, while close to the formulation of the single-image super-resolution problem, is in fact rather different. Single image super-resolution is the task of predicting the image closest to the ground truth from a relatively low resolution image. We propose to produce samples of high resolution images given extremely small inputs with a new method called Latent Adversarial Generator (LAG). In our generative sampling framework, we only use the input (possibly of very low-resolution) to direct what class of samples the network should produce. As such, the output of our algorithm is not a unique image that relates to the input, but rather a possible se} of related images sampled from the manifold of natural images. Our method learns exclusively in the latent space of the adversary using perceptual loss -- it does not have a pixel loss.
Super-Resolving Commercial Satellite Imagery Using Realistic Training Data
Feb 26, 2020
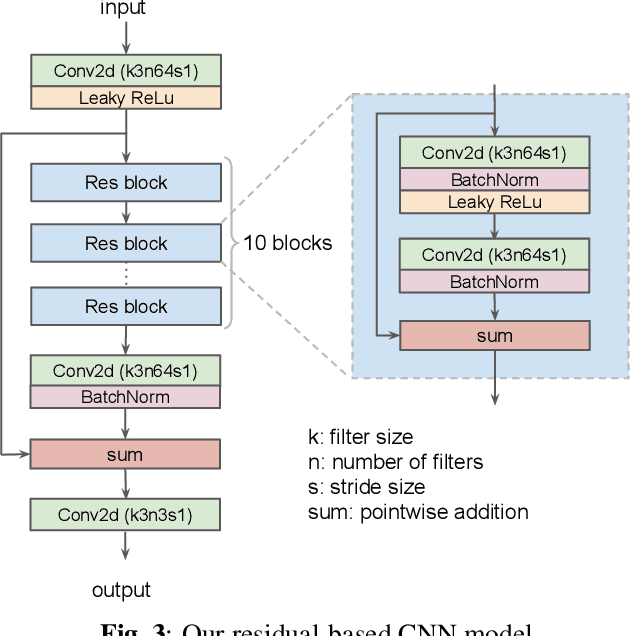

In machine learning based single image super-resolution, the degradation model is embedded in training data generation. However, most existing satellite image super-resolution methods use a simple down-sampling model with a fixed kernel to create training images. These methods work fine on synthetic data, but do not perform well on real satellite images. We propose a realistic training data generation model for commercial satellite imagery products, which includes not only the imaging process on satellites but also the post-process on the ground. We also propose a convolutional neural network optimized for satellite images. Experiments show that the proposed training data generation model is able to improve super-resolution performance on real satellite images.
Image Stylization: From Predefined to Personalized
Feb 22, 2020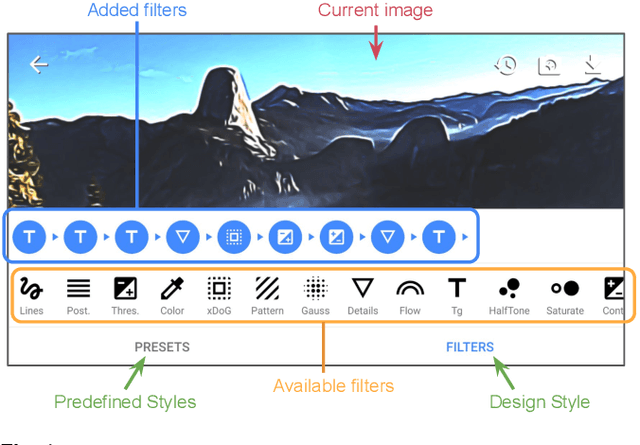
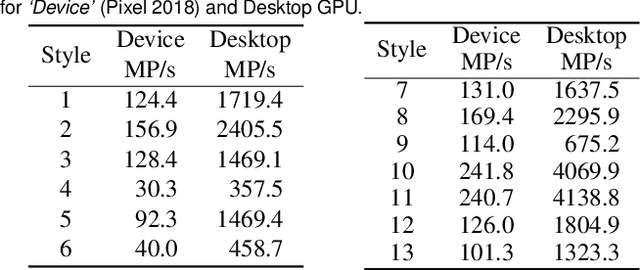
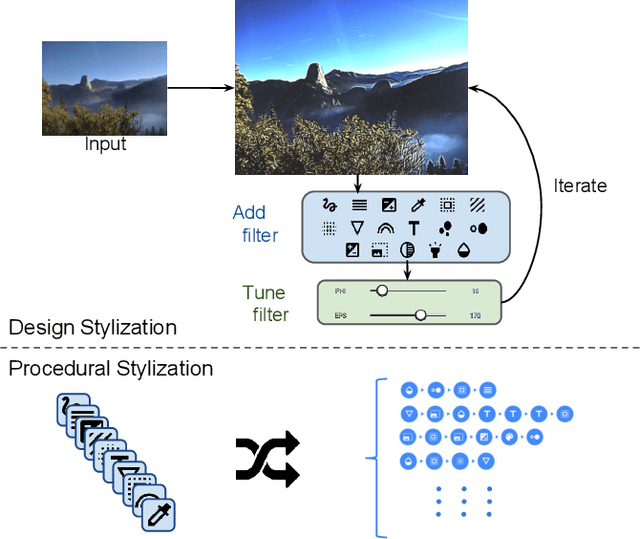
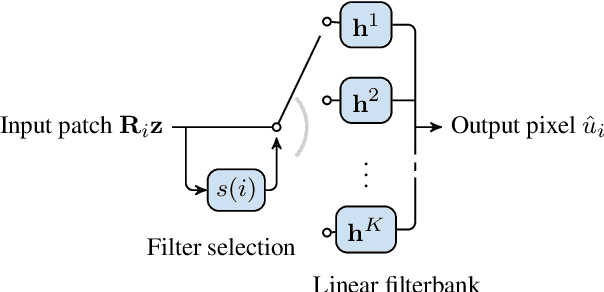
We present a framework for interactive design of new image stylizations using a wide range of predefined filter blocks. Both novel and off-the-shelf image filtering and rendering techniques are extended and combined to allow the user to unleash their creativity to intuitively invent, modify, and tune new styles from a given set of filters. In parallel to this manual design, we propose a novel procedural approach that automatically assembles sequences of filters, leading to unique and novel styles. An important aim of our framework is to allow for interactive exploration and design, as well as to enable videos and camera streams to be stylized on the fly. In order to achieve this real-time performance, we use the \textit{Best Linear Adaptive Enhancement} (BLADE) framework -- an interpretable shallow machine learning method that simulates complex filter blocks in real time. Our representative results include over a dozen styles designed using our interactive tool, a set of styles created procedurally, and new filters trained with our BLADE approach.
Better Compression with Deep Pre-Editing
Feb 01, 2020
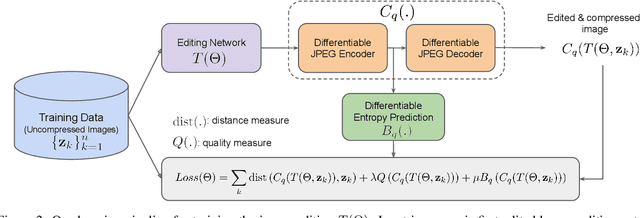
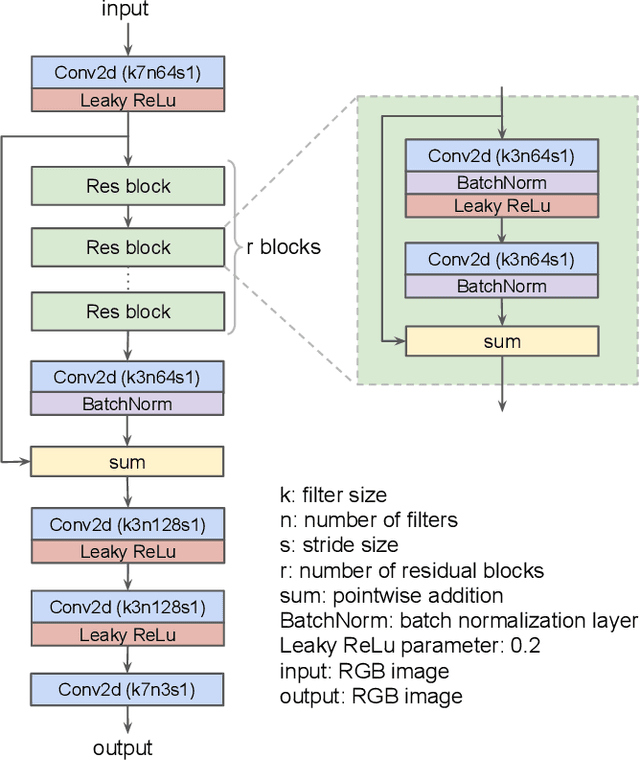
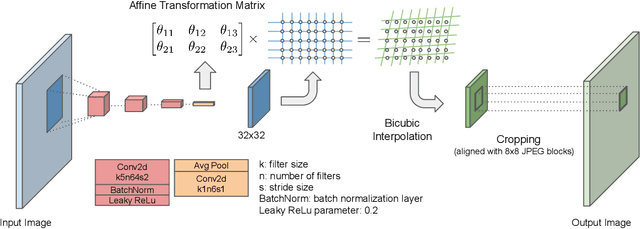
Could we compress images via standard codecs while avoiding artifacts? The answer is obvious -- this is doable as long as the bit budget is generous enough. What if the allocated bit-rate for compression is insufficient? Then unfortunately, artifacts are a fact of life. Many attempts were made over the years to fight this phenomenon, with various degrees of success. In this work we aim to break the unholy connection between bit-rate and image quality, and propose a way to circumvent compression artifacts by pre-editing the incoming image and modifying its content to fit the given bits. We design this editing operation as a learned convolutional neural network, and formulate an optimization problem for its training. Our loss takes into account a proximity between the original image and the edited one, a bit-budget penalty over the proposed image, and a no-reference image quality measure for forcing the outcome to be visually pleasing. The proposed approach is demonstrated on the popular JPEG compression, showing savings in bits and/or improvements in visual quality, obtained with intricate editing effects.
Distortion Agnostic Deep Watermarking
Jan 14, 2020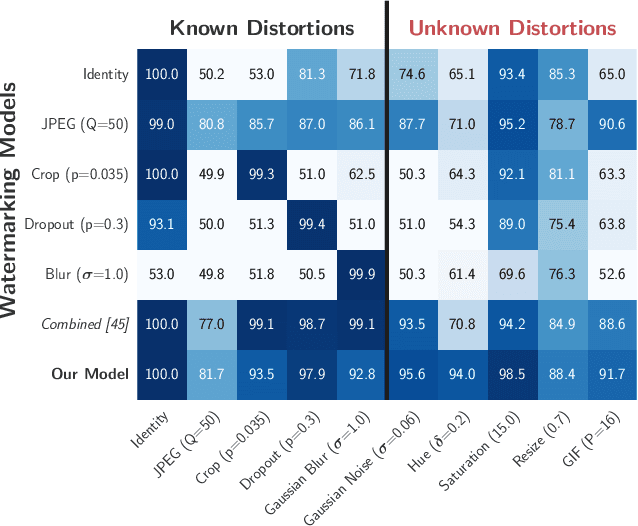
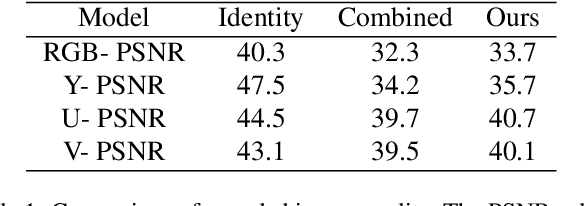

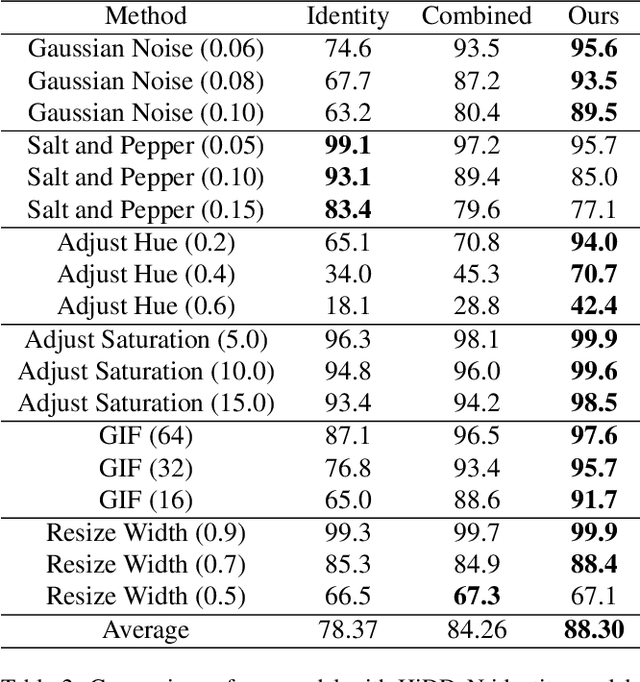
Watermarking is the process of embedding information into an image that can survive under distortions, while requiring the encoded image to have little or no perceptual difference from the original image. Recently, deep learning-based methods achieved impressive results in both visual quality and message payload under a wide variety of image distortions. However, these methods all require differentiable models for the image distortions at training time, and may generalize poorly to unknown distortions. This is undesirable since the types of distortions applied to watermarked images are usually unknown and non-differentiable. In this paper, we propose a new framework for distortion-agnostic watermarking, where the image distortion is not explicitly modeled during training. Instead, the robustness of our system comes from two sources: adversarial training and channel coding. Compared to training on a fixed set of distortions and noise levels, our method achieves comparable or better results on distortions available during training, and better performance on unknown distortions.
Low-Weight and Learnable Image Denoising
Nov 17, 2019

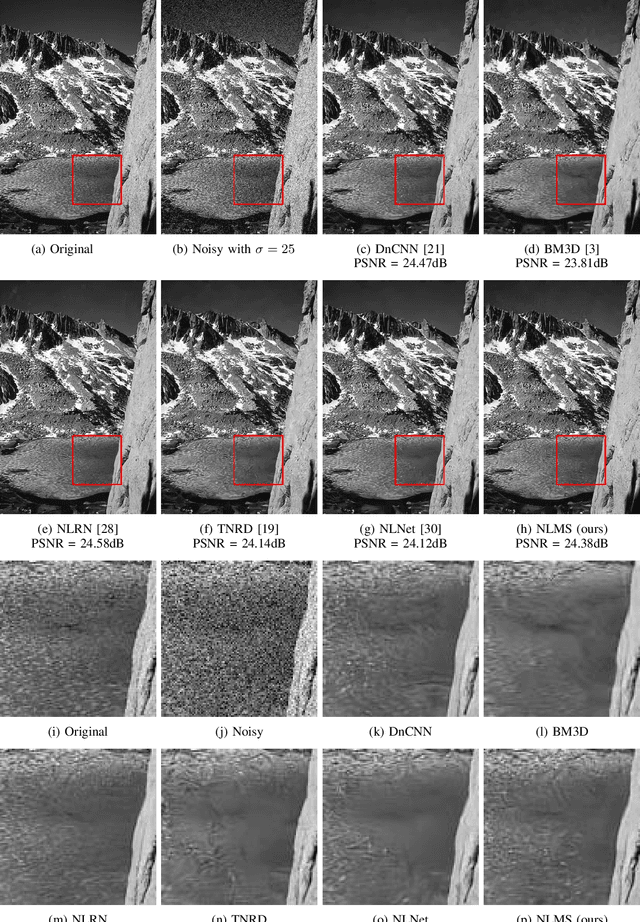

Image denoising is a well studied problem with an extensive activity that has spread over several decades. Despite the many available denoising algorithms, the quest for simple, powerful and fast denoisers is still an active and vibrant topic of research. Leading classical denoising methods are typically designed to exploit the inner structure in images by modeling local overlapping patches. In contrast, recent newcomers to this arena are supervised neural-network-based methods that bypass this modeling altogether, targeting the inference goal directly and globally, while tending to be very deep and parameter heavy. This work proposes a novel low-weight learnable architecture that embeds in it several of the main concepts from the classical methods, while being trained for best denoising performance. More specifically, our proposed network relies on patch processing, leveraging non-local self-similarity, representation sparsity and a multiscale treatment. The proposed architecture achieves near state-of-the-art denoising results, while using a small fraction of the typical number of parameters. Furthermore, we demonstrate the ability of the proposed network to adapt itself to an incoming image by leveraging similar clean ones.
Deep K-SVD Denoising
Sep 28, 2019
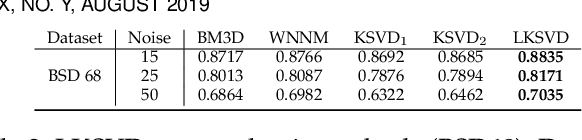

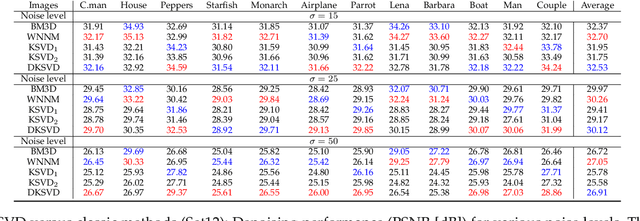
This work considers noise removal from images, focusing on the well known K-SVD denoising algorithm. This sparsity-based method was proposed in 2006, and for a short while it was considered as state-of-the-art. However, over the years it has been surpassed by other methods, including the recent deep-learning-based newcomers. The question we address in this paper is whether K-SVD was brought to its peak in its original conception, or whether it can be made competitive again. The approach we take in answering this question is to redesign the algorithm to operate in a supervised manner. More specifically, we propose an end-to-end deep architecture with the exact K-SVD computational path, and train it for optimized denoising. Our work shows how to overcome difficulties arising in turning the K-SVD scheme into a differentiable, and thus learnable, machine. With a small number of parameters to learn and while preserving the original K-SVD essence, the proposed architecture is shown to outperform the classical K-SVD algorithm substantially, and getting closer to recent state-of-the-art learning-based denoising methods. Adopting a broader context, this work touches on themes around the design of deep-learning solutions for image processing tasks, while paving a bridge between classic methods and novel deep-learning-based ones.
Handheld Multi-Frame Super-Resolution
May 08, 2019
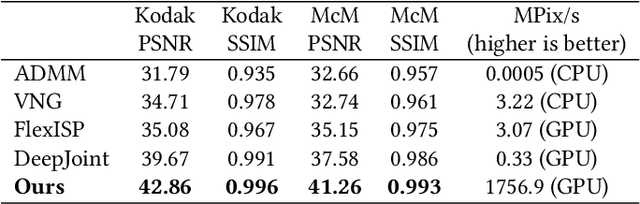
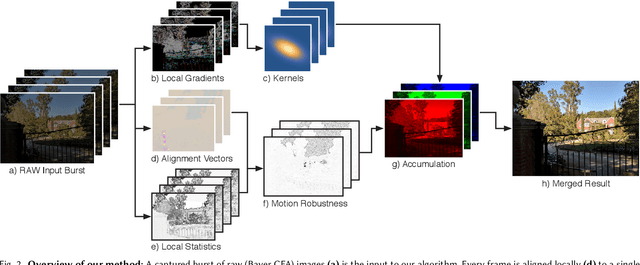
Compared to DSLR cameras, smartphone cameras have smaller sensors, which limits their spatial resolution; smaller apertures, which limits their light gathering ability; and smaller pixels, which reduces their signal-to noise ratio. The use of color filter arrays (CFAs) requires demosaicing, which further degrades resolution. In this paper, we supplant the use of traditional demosaicing in single-frame and burst photography pipelines with a multiframe super-resolution algorithm that creates a complete RGB image directly from a burst of CFA raw images. We harness natural hand tremor, typical in handheld photography, to acquire a burst of raw frames with small offsets. These frames are then aligned and merged to form a single image with red, green, and blue values at every pixel site. This approach, which includes no explicit demosaicing step, serves to both increase image resolution and boost signal to noise ratio. Our algorithm is robust to challenging scene conditions: local motion, occlusion, or scene changes. It runs at 100 milliseconds per 12-megapixel RAW input burst frame on mass-produced mobile phones. Specifically, the algorithm is the basis of the Super-Res Zoom feature, as well as the default merge method in Night Sight mode (whether zooming or not) on Google's flagship phone.