 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndependent Sign Language Recognition with 3D Body, Hands, and Face Reconstruction
Nov 24, 2020

Independent Sign Language Recognition is a complex visual recognition problem that combines several challenging tasks of Computer Vision due to the necessity to exploit and fuse information from hand gestures, body features and facial expressions. While many state-of-the-art works have managed to deeply elaborate on these features independently, to the best of our knowledge, no work has adequately combined all three information channels to efficiently recognize Sign Language. In this work, we employ SMPL-X, a contemporary parametric model that enables joint extraction of 3D body shape, face and hands information from a single image. We use this holistic 3D reconstruction for SLR, demonstrating that it leads to higher accuracy than recognition from raw RGB images and their optical flow fed into the state-of-the-art I3D-type network for 3D action recognition and from 2D Openpose skeletons fed into a Recurrent Neural Network. Finally, a set of experiments on the body, face and hand features showed that neglecting any of these, significantly reduces the classification accuracy, proving the importance of jointly modeling body shape, facial expression and hand pose for Sign Language Recognition.
Advances in the training, pruning and enforcement of shape constraints of Morphological Neural Networks using Tropical Algebra
Nov 15, 2020


In this paper we study an emerging class of neural networks based on the morphological operators of dilation and erosion. We explore these networks mathematically from a tropical geometry perspective as well as mathematical morphology. Our contributions are threefold. First, we examine the training of morphological networks via Difference-of-Convex programming methods and extend a binary morphological classifier to multiclass tasks. Second, we focus on the sparsity of dense morphological networks trained via gradient descent algorithms and compare their performance to their linear counterparts under heavy pruning, showing that the morphological networks cope far better and are characterized with superior compression capabilities. Our approach incorporates the effect of the training optimizer used and offers quantitative and qualitative explanations. Finally, we study how the architectural structure of a morphological network can affect shape constraints, focusing on monotonicity. Via Maslov Dequantization, we obtain a softened version of a known architecture and show how this approach can improve training convergence and performance.
Sparse Approximate Solutions to Max-Plus Equations with Application to Multivariate Convex Regression
Nov 06, 2020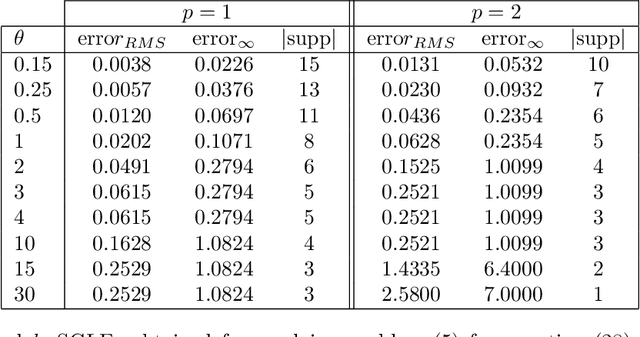
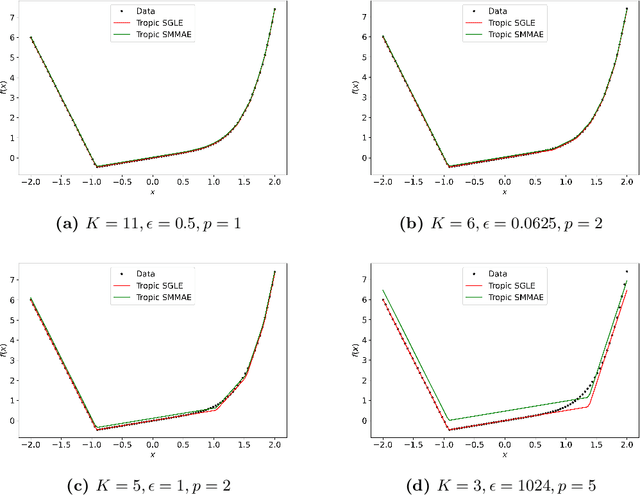
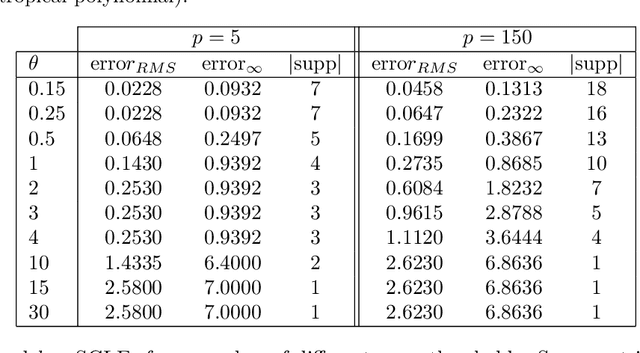
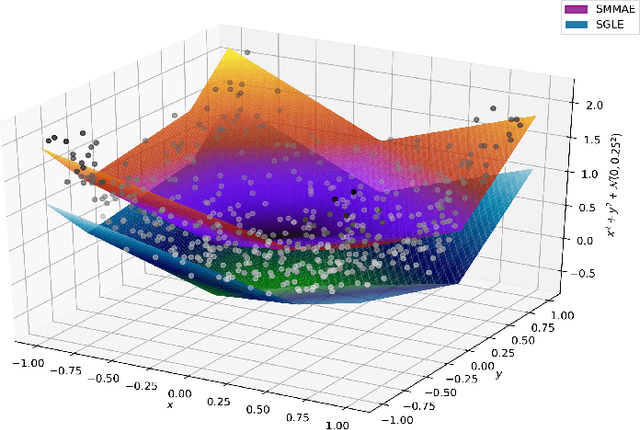
In this work, we study the problem of finding approximate, with minimum support set, solutions to matrix max-plus equations, which we call sparse approximate solutions. We show how one can obtain such solutions efficiently and in polynomial time for any $\ell_p$ approximation error. Based on these results, we propose a novel method for piecewise-linear fitting of convex multivariate functions, with optimality guarantees for the model parameters and an approximately minimum number of affine regions.
Emotion Understanding in Videos Through Body, Context, and Visual-Semantic Embedding Loss
Oct 30, 2020We present our winning submission to the First International Workshop on Bodily Expressed Emotion Understanding (BEEU) challenge. Based on recent literature on the effect of context/environment on emotion, as well as visual representations with semantic meaning using word embeddings, we extend the framework of Temporal Segment Network to accommodate these. Our method is verified on the validation set of the Body Language Dataset (BoLD) and achieves 0.26235 Emotion Recognition Score on the test set, surpassing the previous best result of 0.2530.
Multiscale Fractal Analysis of Stimulated EEG Signals with Application to Emotion Classification
Oct 30, 2020



Emotion Recognition from EEG signals has long been researched as it can assist numerous medical and rehabilitative applications. However, their complex and noisy structure has proven to be a serious barrier for traditional modeling methods. In this paper we employ multifractal analysis to examine the behavior of EEG signals in terms of presence of fluctuations and the degree of fragmentation along their major frequency bands, for the task of emotion recognition. In order to extract emotion-related features we utilize two novel algorithms for EEG analysis, based on Multiscale Fractal Dimension and Multifractal Detrended Fluctuation Analysis. The proposed feature extraction methods perform efficiently, surpassing some widely used baseline features on the competitive DEAP dataset, indicating that multifractal analysis could serve as basis for the development of robust models for affective state recognition.
ChildBot: Multi-Robot Perception and Interaction with Children
Aug 28, 2020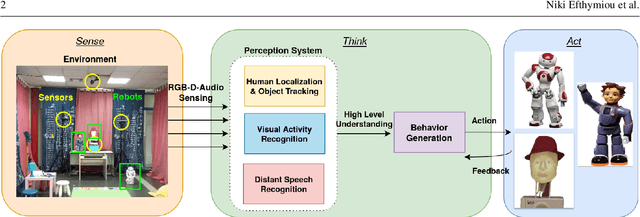

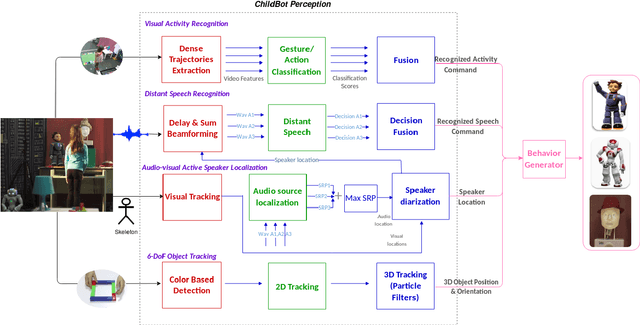
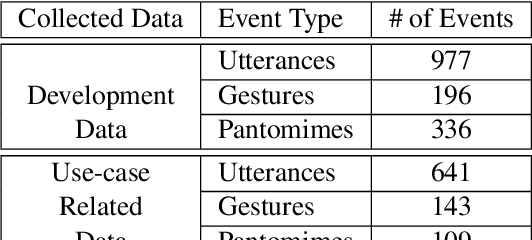
In this paper we present an integrated robotic system capable of participating in and performing a wide range of educational and entertainment tasks, in collaboration with one or more children. The system, called ChildBot, features multimodal perception modules and multiple robotic agents that monitor the interaction environment, and can robustly coordinate complex Child-Robot Interaction use-cases. In order to validate the effectiveness of the system and its integrated modules, we have conducted multiple experiments with a total of 52 children. Our results show improved perception capabilities in comparison to our earlier works that ChildBot was based on. In addition, we have conducted a preliminary user experience study, employing some educational/entertainment tasks, that yields encouraging results regarding the technical validity of our system and initial insights on the user experience with it.
WSRNet: Joint Spotting and Recognition of Handwritten Words
Aug 17, 2020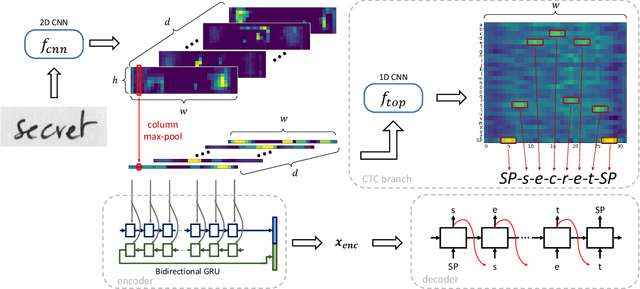
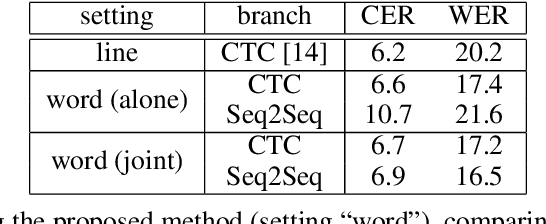
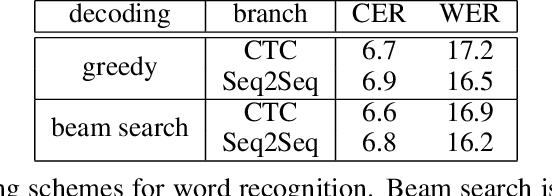

In this work, we present a unified model that can handle both Keyword Spotting and Word Recognition with the same network architecture. The proposed network is comprised of a non-recurrent CTC branch and a Seq2Seq branch that is further augmented with an Autoencoding module. The related joint loss leads to a boost in recognition performance, while the Seq2Seq branch is used to create efficient word representations. We show how to further process these representations with binarization and a retraining scheme to provide compact and highly efficient descriptors, suitable for keyword spotting. Numerical results validate the usefulness of the proposed architecture, as our method outperforms the previous state-of-the-art in keyword spotting, and provides results in the ballpark of the leading methods for word recognition.
Orientation Attentive Robot Grasp Synthesis
Jun 09, 2020
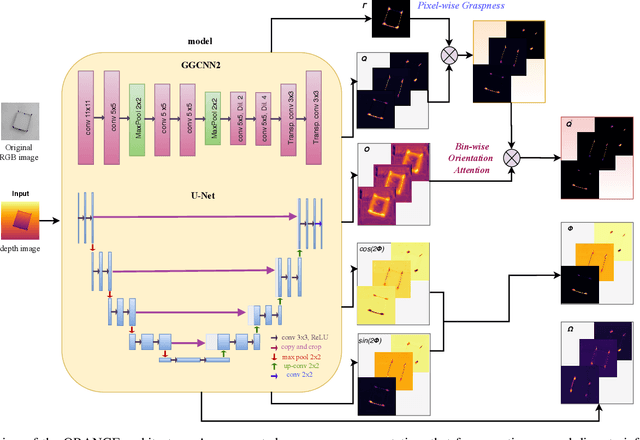
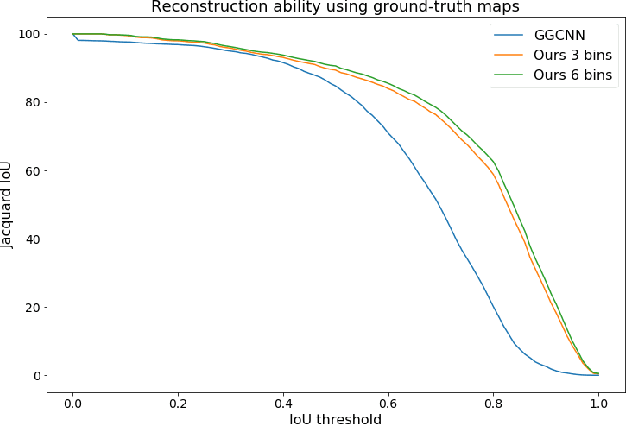
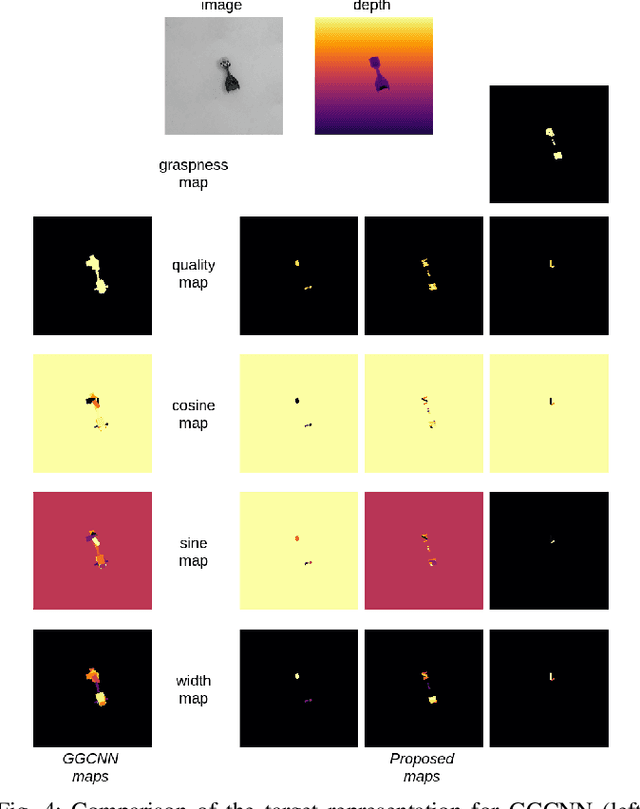
Physical neighborhoods of grasping points in common objects may offer a wide variety of plausible grasping configurations. For a fixed center of a simple spherical object, for example, there is an infinite number of valid grasping orientations. Such structures create ambiguous and discontinuous grasp maps that confuse neural regressors. We perform a thorough investigation of the challenging Jacquard dataset to show that the existing pixel-wise learning approaches are prone to box overlaps of drastically different orientations. We then introduce a novel augmented map representation that partitions the angle space into bins to allow for the co-occurrence of such orientations and observe larger accuracy margins on the ground truth grasp map reconstructions. On top of that, we build the ORientation AtteNtive Grasp synthEsis (ORANGE) framework that jointly solves a bin classification problem and a real-value regression. The grasp synthesis is attentively supervised by combining discrete and continuous estimations into a single map. We provide experimental evidence by appending ORANGE to two existing unimodal architectures and boost their performance to state-of-the-art levels on Jacquard, specifically 94.71\%, over all related works, even multimodal. Code is available at \url{https://github.com/nickgkan/orange}.
Weight Pruning via Adaptive Sparsity Loss
Jun 04, 2020
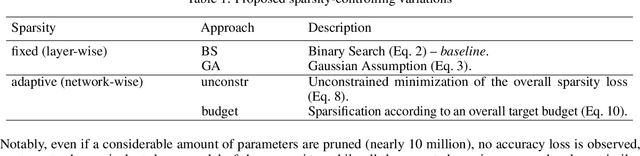
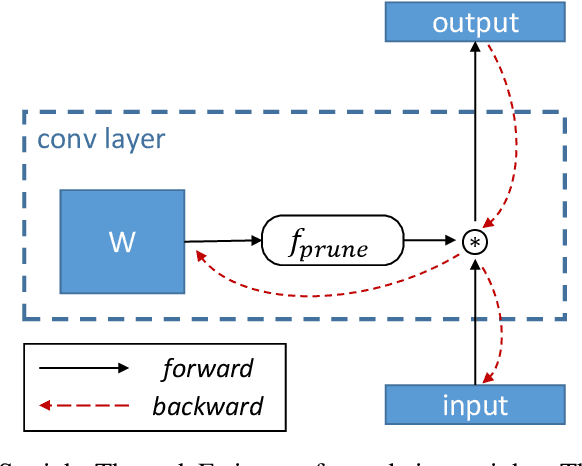
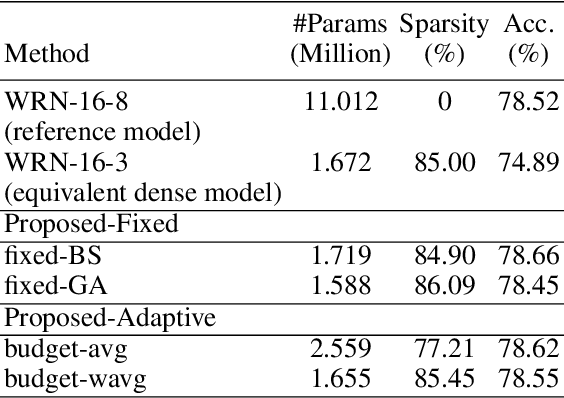
Pruning neural networks has regained interest in recent years as a means to compress state-of-the-art deep neural networks and enable their deployment on resource-constrained devices. In this paper, we propose a robust compressive learning framework that efficiently prunes network parameters during training with minimal computational overhead. We incorporate fast mechanisms to prune individual layers and build upon these to automatically prune the entire network under a user-defined budget constraint. Key to our end-to-end network pruning approach is the formulation of an intuitive and easy-to-implement adaptive sparsity loss that is used to explicitly control sparsity during training, enabling efficient budget-aware optimization. Extensive experiments demonstrate the effectiveness of the proposed framework for image classification on the CIFAR and ImageNet datasets using different architectures, including AlexNet, ResNets and Wide ResNets.
How to track your dragon: A Multi-Attentional Framework for real-time RGB-D 6-DOF Object Pose Tracking
Apr 21, 2020

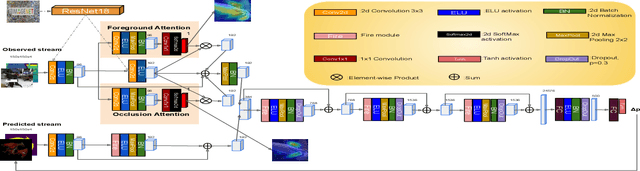

We present a novel multi-attentional convolutional architecture to tackle the problem of real-time RGB-D 6D object pose tracking of single, known objects. Such a problem poses multiple challenges originating both from the objects' nature and their interaction with their environment, which previous approaches have failed to fully address. The proposed framework encapsulates methods for background clutter and occlusion handling by integrating multiple parallel soft spatial attention modules into a multitask Convolutional Neural Network (CNN) architecture. Moreover, we consider the special geometrical properties of both the object's 3D model and the pose space, and we use a more sophisticated approach for data augmentation for training. The provided experimental results confirm the effectiveness of the proposed multi-attentional architecture, as it improves the State-of-the-Art (SoA) tracking performance by an average score of 40.5% for translation and 57.5% for rotation, when testing on the dataset presented in [1], the most complete dataset designed, up to date, for the problem of RGB-D object tracking.