 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeight Pruning via Adaptive Sparsity Loss
Jun 04, 2020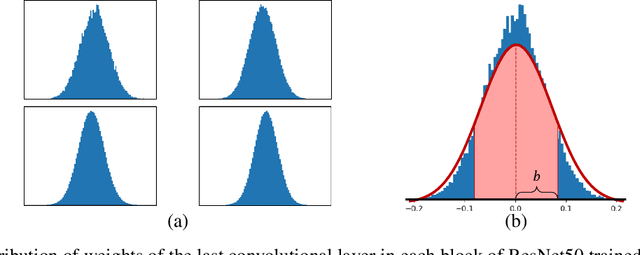
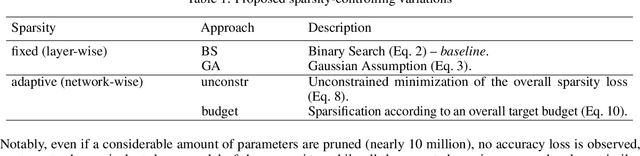
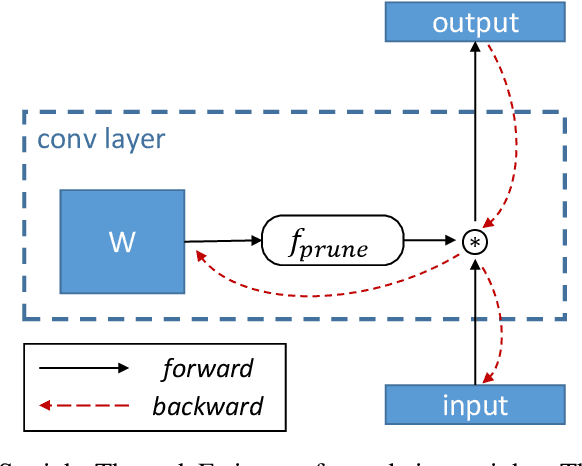
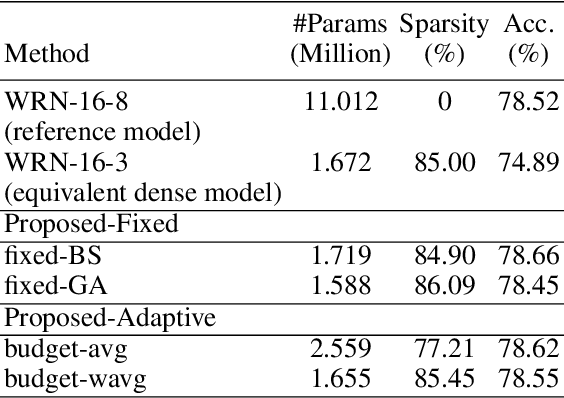
Pruning neural networks has regained interest in recent years as a means to compress state-of-the-art deep neural networks and enable their deployment on resource-constrained devices. In this paper, we propose a robust compressive learning framework that efficiently prunes network parameters during training with minimal computational overhead. We incorporate fast mechanisms to prune individual layers and build upon these to automatically prune the entire network under a user-defined budget constraint. Key to our end-to-end network pruning approach is the formulation of an intuitive and easy-to-implement adaptive sparsity loss that is used to explicitly control sparsity during training, enabling efficient budget-aware optimization. Extensive experiments demonstrate the effectiveness of the proposed framework for image classification on the CIFAR and ImageNet datasets using different architectures, including AlexNet, ResNets and Wide ResNets.
RecNets: Channel-wise Recurrent Convolutional Neural Networks
May 28, 2019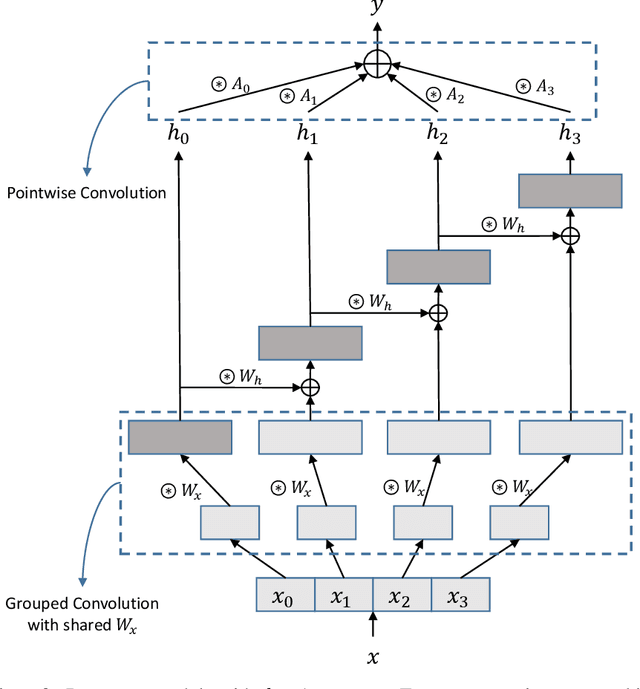
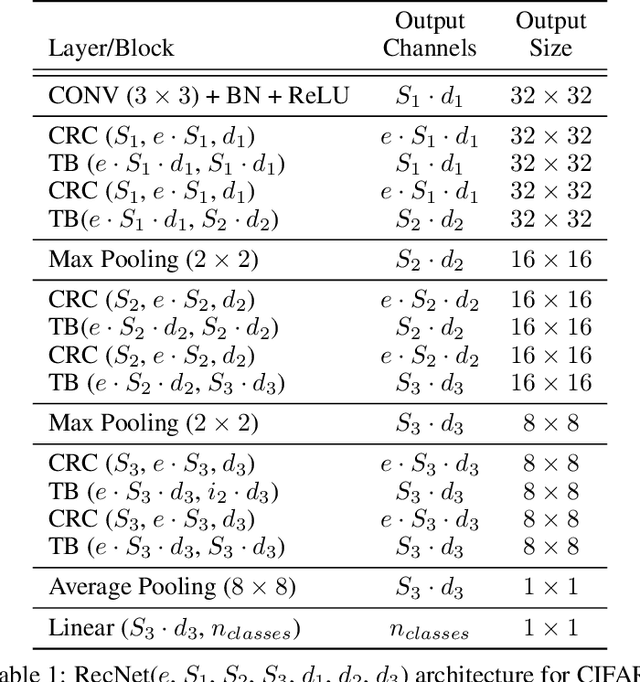
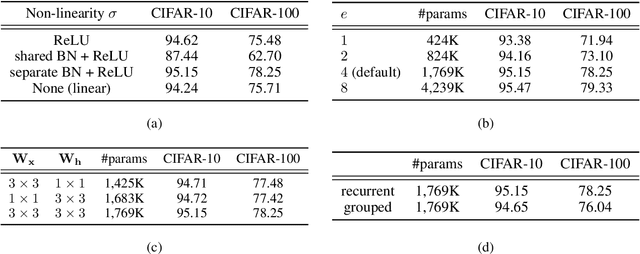
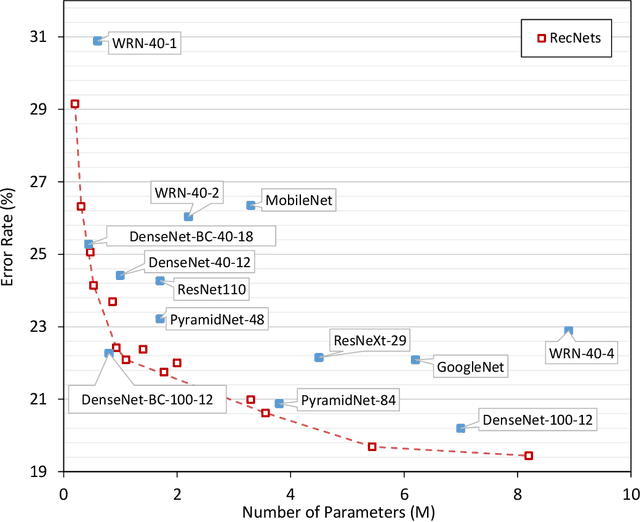
In this paper, we introduce Channel-wise recurrent convolutional neural networks (RecNets), a family of novel, compact neural network architectures for computer vision tasks inspired by recurrent neural networks (RNNs). RecNets build upon Channel-wise recurrent convolutional (CRC) layers, a novel type of convolutional layer that splits the input channels into disjoint segments and processes them in a recurrent fashion. In this way, we simulate wide, yet compact models, since the number of parameters is vastly reduced via the parameter sharing of the RNN formulation. Experimental results on the CIFAR-10 and CIFAR-100 image classification tasks demonstrate the superior size-accuracy trade-off of RecNets compared to other compact state-of-the-art architectures.