 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Reminiscence Therapy for Dementia
Oct 25, 2019


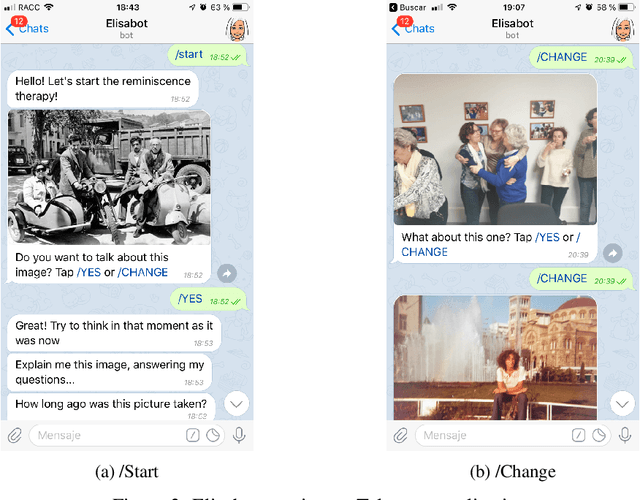
With people living longer than ever, the number of cases with dementia such as Alzheimer's disease increases steadily. It affects more than 46 million people worldwide, and it is estimated that in 2050 more than 100 million will be affected. While there are not effective treatments for these terminal diseases, therapies such as reminiscence, that stimulate memories from the past are recommended. Currently, reminiscence therapy takes place in care homes and is guided by a therapist or a carer. In this work, we present an AI-based solution to automatize the reminiscence therapy, which consists in a dialogue system that uses photos as input to generate questions. We run a usability case study with patients diagnosed of mild cognitive impairment that shows they found the system very entertaining and challenging. Overall, this paper presents how reminiscence therapy can be automatized by using machine learning, and deployed to smartphones and laptops, making the therapy more accessible to every person affected by dementia.
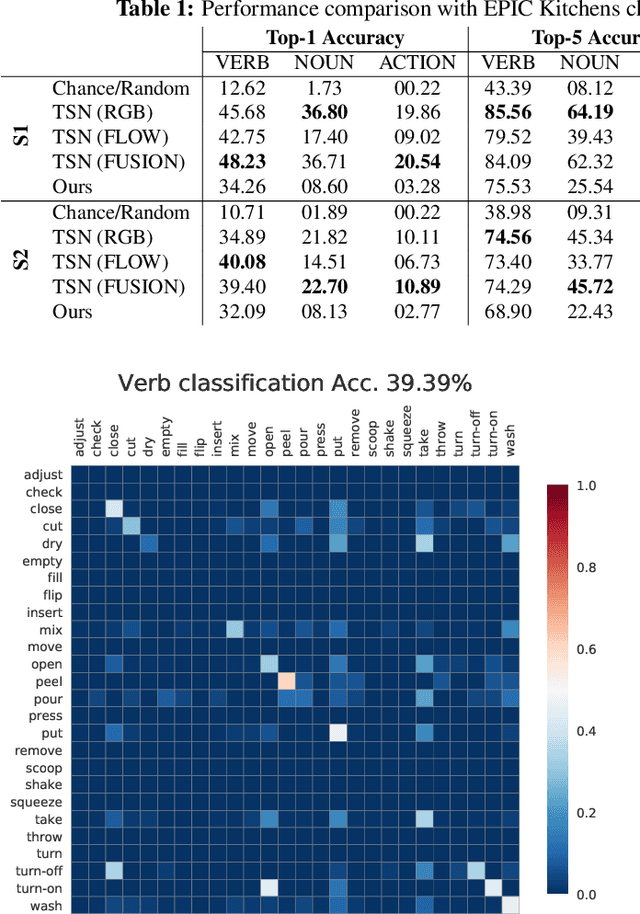
Seeing and Hearing Egocentric Actions: How Much Can We Learn?
Oct 15, 2019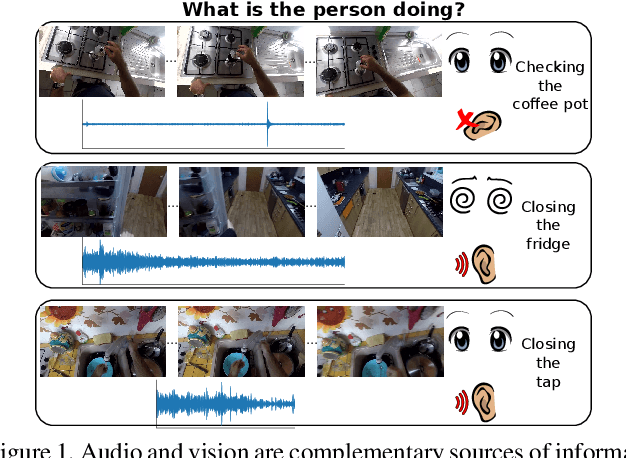
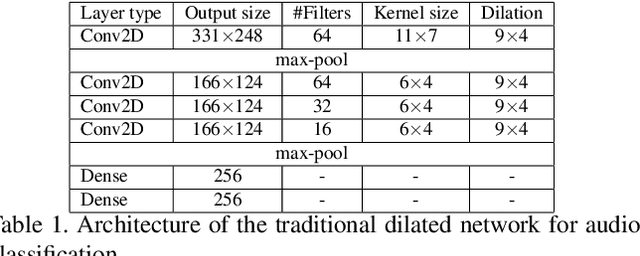
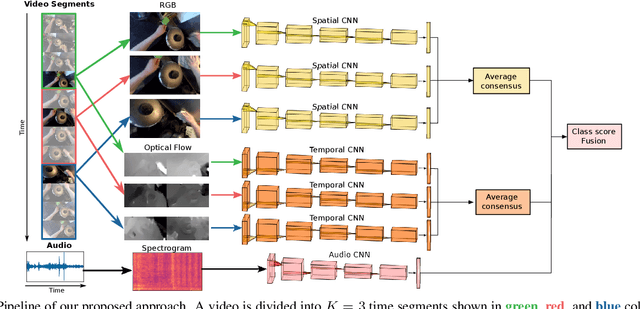
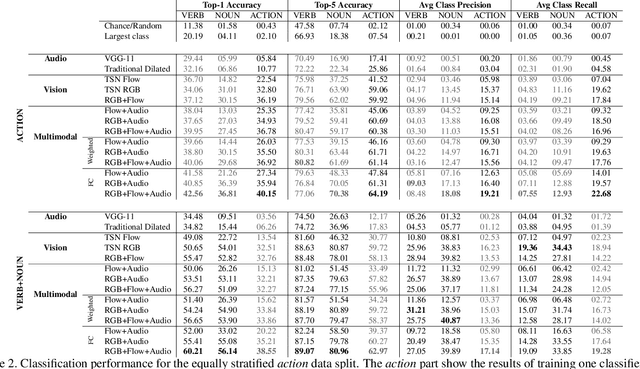
Our interaction with the world is an inherently multimodal experience. However, the understanding of human-to-object interactions has historically been addressed focusing on a single modality. In particular, a limited number of works have considered to integrate the visual and audio modalities for this purpose. In this work, we propose a multimodal approach for egocentric action recognition in a kitchen environment that relies on audio and visual information. Our model combines a sparse temporal sampling strategy with a late fusion of audio, spatial, and temporal streams. Experimental results on the EPIC-Kitchens dataset show that multimodal integration leads to better performance than unimodal approaches. In particular, we achieved a 5.18% improvement over the state of the art on verb classification.
MobileGAN: Skin Lesion Segmentation Using a Lightweight Generative Adversarial Network
Jul 01, 2019
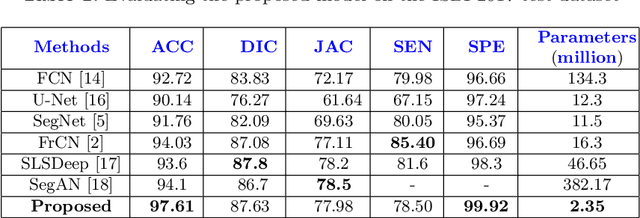
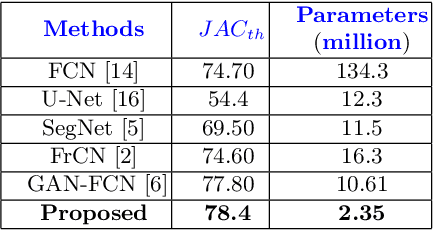
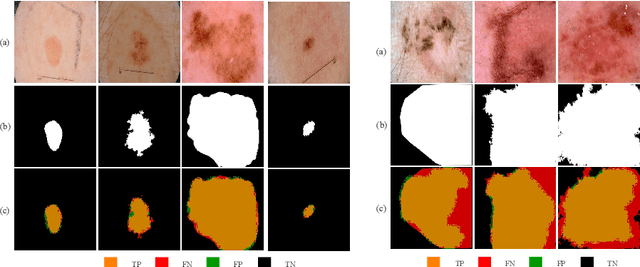
Skin lesion segmentation in dermoscopic images is a challenge due to their blurry and irregular boundaries. Most of the segmentation approaches based on deep learning are time and memory consuming due to the hundreds of millions of parameters. Consequently, it is difficult to apply them to real dermatoscope devices with limited GPU and memory resources. In this paper, we propose a lightweight and efficient Generative Adversarial Networks (GAN) model, called MobileGAN for skin lesion segmentation. More precisely, the MobileGAN combines 1D non-bottleneck factorization networks with position and channel attention modules in a GAN model. The proposed model is evaluated on the test dataset of the ISBI 2017 challenges and the validation dataset of ISIC 2018 challenges. Although the proposed network has only 2.35 millions of parameters, it is still comparable with the state-of-the-art. The experimental results show that our MobileGAN obtains comparable performance with an accuracy of 97.61%.
How Much Does Audio Matter to Recognize Egocentric Object Interactions?
Jun 03, 2019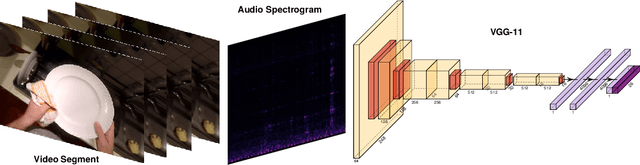

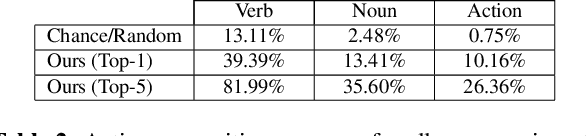
Sounds are an important source of information on our daily interactions with objects. For instance, a significant amount of people can discern the temperature of water that it is being poured just by using the sense of hearing. However, only a few works have explored the use of audio for the classification of object interactions in conjunction with vision or as single modality. In this preliminary work, we propose an audio model for egocentric action recognition and explore its usefulness on the parts of the problem (noun, verb, and action classification). Our model achieves a competitive result in terms of verb classification (34.26% accuracy) on a standard benchmark with respect to vision-based state of the art systems, using a comparatively lighter architecture.
Social Relation Recognition in Egocentric Photostreams
May 12, 2019
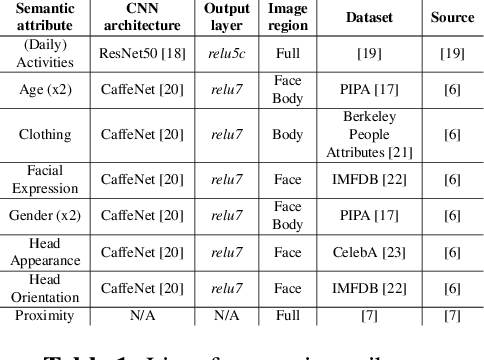

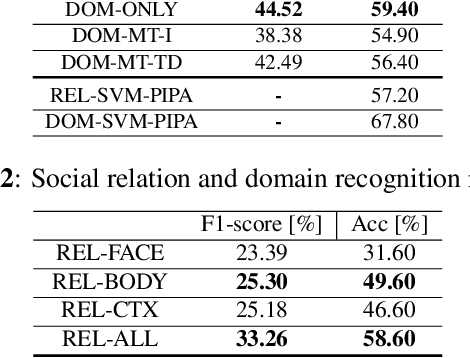
This paper proposes an approach to automatically categorize the social interactions of a user wearing a photo-camera 2fpm, by relying solely on what the camera is seeing. The problem is challenging due to the overwhelming complexity of social life and the extreme intra-class variability of social interactions captured under unconstrained conditions. We adopt the formalization proposed in Bugental's social theory, that groups human relations into five social domains with related categories. Our method is a new deep learning architecture that exploits the hierarchical structure of the label space and relies on a set of social attributes estimated at frame level to provide a semantic representation of social interactions. Experimental results on the new EgoSocialRelation dataset demonstrate the effectiveness of our proposal.
Towards Emotion Retrieval in Egocentric PhotoStream
May 10, 2019
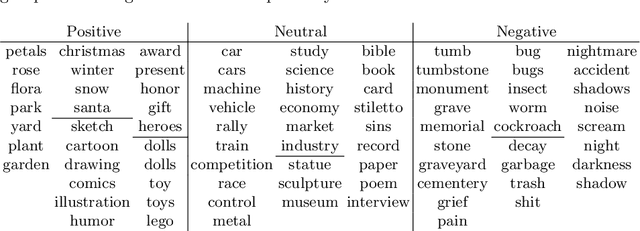
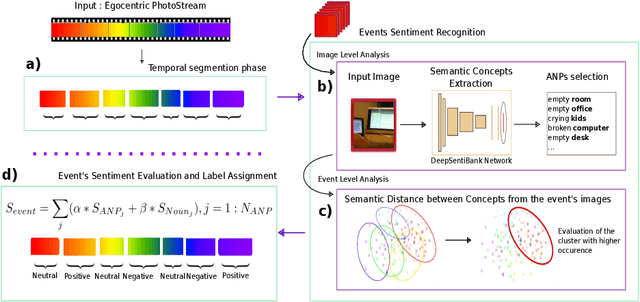
The availability and use of egocentric data are rapidly increasing due to the growing use of wearable cameras. Our aim is to study the effect (positive, neutral or negative) of egocentric images or events on an observer. Given egocentric photostreams capturing the wearer's days, we propose a method that aims to assign sentiment to events extracted from egocentric photostreams. Such moments can be candidates to retrieve according to their possibility of representing a positive experience for the camera's wearer. The proposed approach obtained a classification accuracy of 75% on the test set, with a deviation of 8%. Our model makes a step forward opening the door to sentiment recognition in egocentric photostreams.
Hierarchical approach to classify food scenes in egocentric photo-streams
May 10, 2019
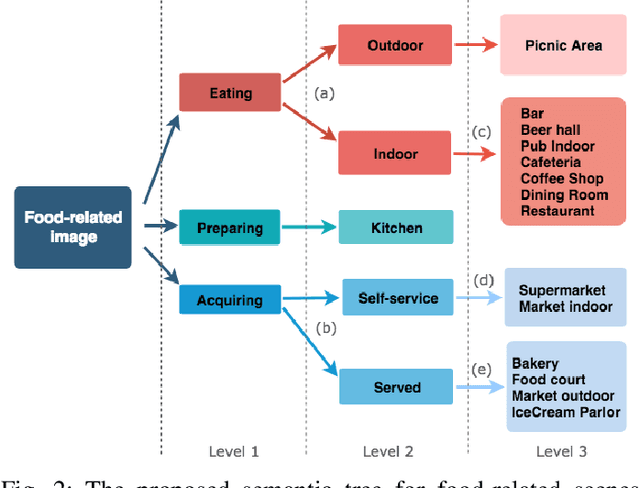
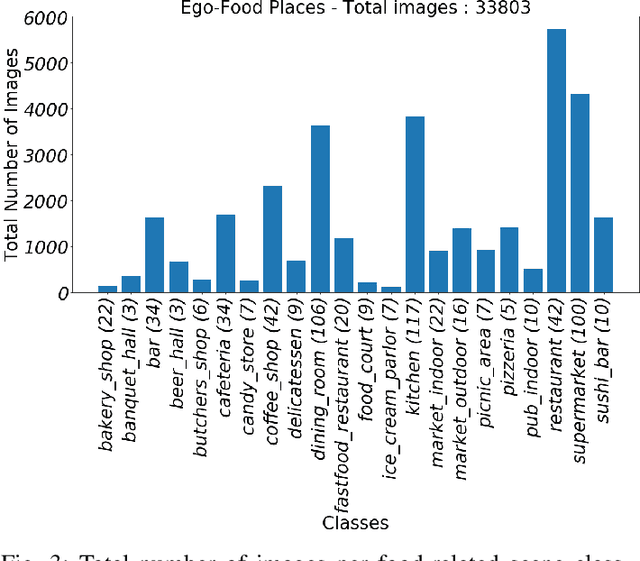
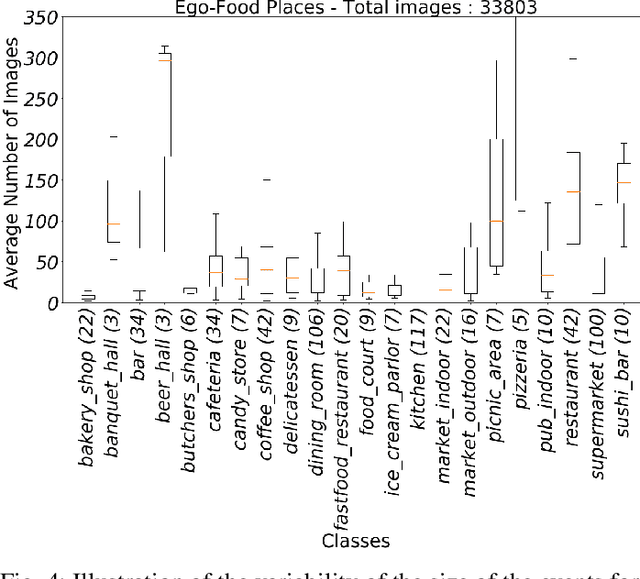
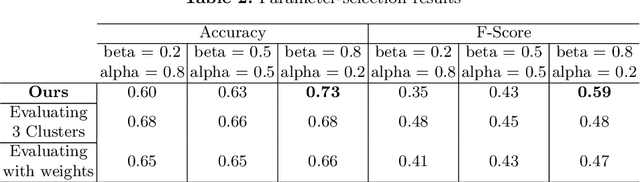
Recent studies have shown that the environment where people eat can affect their nutritional behaviour. In this work, we provide automatic tools for a personalised analysis of a person's health habits by the examination of daily recorded egocentric photo-streams. Specifically, we propose a new automatic approach for the classification of food-related environments, that is able to classify up to 15 such scenes. In this way, people can monitor the context around their food intake in order to get an objective insight into their daily eating routine. We propose a model that classifies food-related scenes organized in a semantic hierarchy. Additionally, we present and make available a new egocentric dataset composed of more than 33000 images recorded by a wearable camera, over which our proposed model has been tested. Our approach obtains an accuracy and F-score of 56\% and 65\%, respectively, clearly outperforming the baseline methods.
Towards Unsupervised Familiar Scene Recognition in Egocentric Videos
May 10, 2019

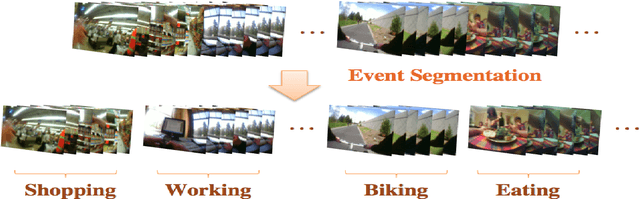
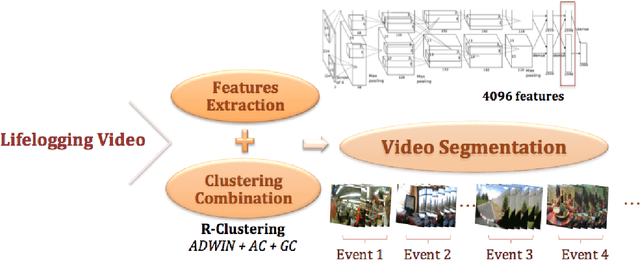
Nowadays, there is an upsurge of interest in using lifelogging devices. Such devices generate huge amounts of image data; consequently, the need for automatic methods for analyzing and summarizing these data is drastically increasing. We present a new method for familiar scene recognition in egocentric videos, based on background pattern detection through automatically configurable COSFIRE filters. We present some experiments over egocentric data acquired with the Narrative Clip.
Unsupervised routine discovery in egocentric photo-streams
May 10, 2019
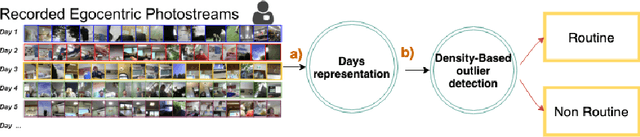
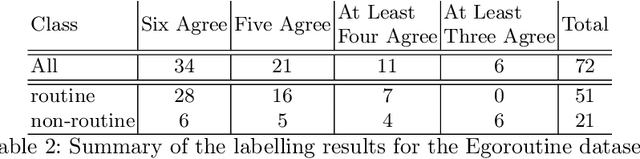
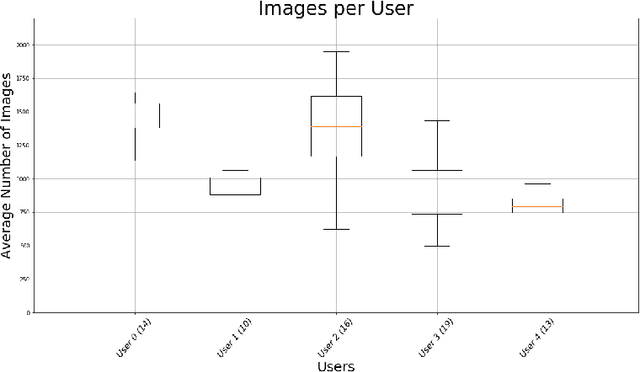
The routine of a person is defined by the occurrence of activities throughout different days, and can directly affect the person's health. In this work, we address the recognition of routine related days. To do so, we rely on egocentric images, which are recorded by a wearable camera and allow to monitor the life of the user from a first-person view perspective. We propose an unsupervised model that identifies routine related days, following an outlier detection approach. We test the proposed framework over a total of 72 days in the form of photo-streams covering around 2 weeks of the life of 5 different camera wearers. Our model achieves an average of 76% Accuracy and 68% Weighted F-Score for all the users. Thus, we show that our framework is able to recognise routine related days and opens the door to the understanding of the behaviour of people.
Towards Egocentric Person Re-identification and Social Pattern Analysis
May 10, 2019

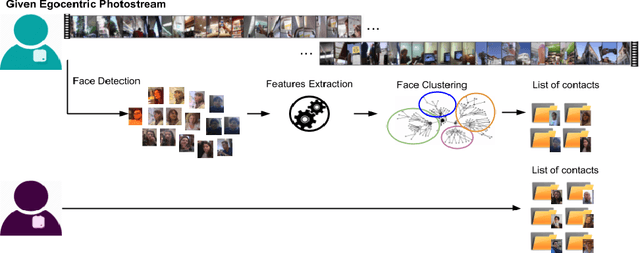
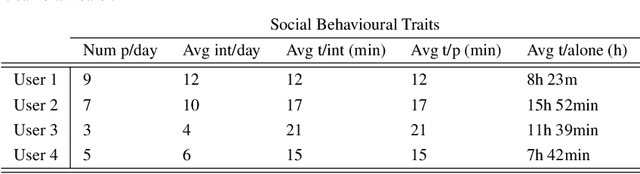
Wearable cameras capture a first-person view of the daily activities of the camera wearer, offering a visual diary of the user behaviour. Detection of the appearance of people the camera user interacts with for social interactions analysis is of high interest. Generally speaking, social events, lifestyle and health are highly correlated, but there is a lack of tools to monitor and analyse them. We consider that egocentric vision provides a tool to obtain information and understand users social interactions. We propose a model that enables us to evaluate and visualize social traits obtained by analysing social interactions appearance within egocentric photostreams. Given sets of egocentric images, we detect the appearance of faces within the days of the camera wearer, and rely on clustering algorithms to group their feature descriptors in order to re-identify persons. Recurrence of detected faces within photostreams allows us to shape an idea of the social pattern of behaviour of the user. We validated our model over several weeks recorded by different camera wearers. Our findings indicate that social profiles are potentially useful for social behaviour interpretation.