 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Graph-Based Method for Soccer Action Spotting Using Unsupervised Player Classification
Nov 22, 2022Action spotting in soccer videos is the task of identifying the specific time when a certain key action of the game occurs. Lately, it has received a large amount of attention and powerful methods have been introduced. Action spotting involves understanding the dynamics of the game, the complexity of events, and the variation of video sequences. Most approaches have focused on the latter, given that their models exploit the global visual features of the sequences. In this work, we focus on the former by (a) identifying and representing the players, referees, and goalkeepers as nodes in a graph, and by (b) modeling their temporal interactions as sequences of graphs. For the player identification, or player classification task, we obtain an accuracy of 97.72% in our annotated benchmark. For the action spotting task, our method obtains an overall performance of 57.83% average-mAP by combining it with other audiovisual modalities. This performance surpasses similar graph-based methods and has competitive results with heavy computing methods. Code and data are available at https://github.com/IPCV/soccer_action_spotting.
Modeling long-term interactions to enhance action recognition
Apr 23, 2021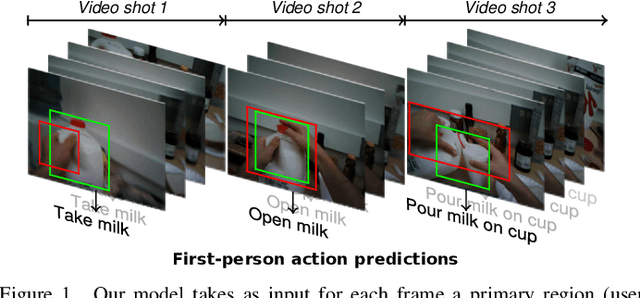

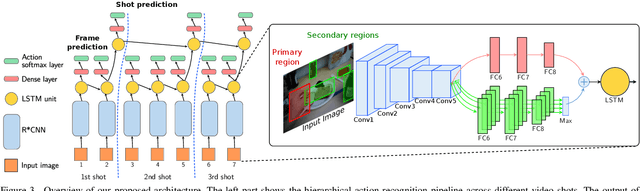
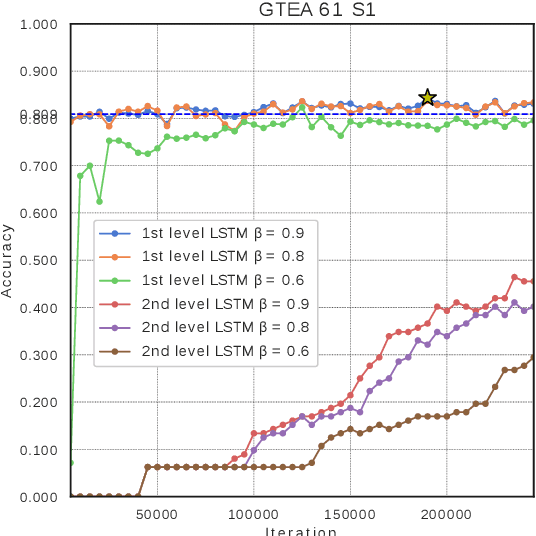
In this paper, we propose a new approach to under-stand actions in egocentric videos that exploits the semantics of object interactions at both frame and temporal levels. At the frame level, we use a region-based approach that takes as input a primary region roughly corresponding to the user hands and a set of secondary regions potentially corresponding to the interacting objects and calculates the action score through a CNN formulation. This information is then fed to a Hierarchical LongShort-Term Memory Network (HLSTM) that captures temporal dependencies between actions within and across shots. Ablation studies thoroughly validate the proposed approach, showing in particular that both levels of the HLSTM architecture contribute to performance improvement. Furthermore, quantitative comparisons show that the proposed approach outperforms the state-of-the-art in terms of action recognition on standard benchmarks,without relying on motion information
Seeing and Hearing Egocentric Actions: How Much Can We Learn?
Oct 15, 2019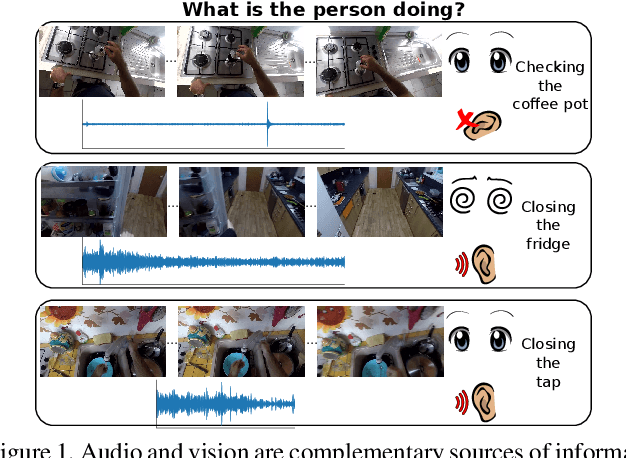
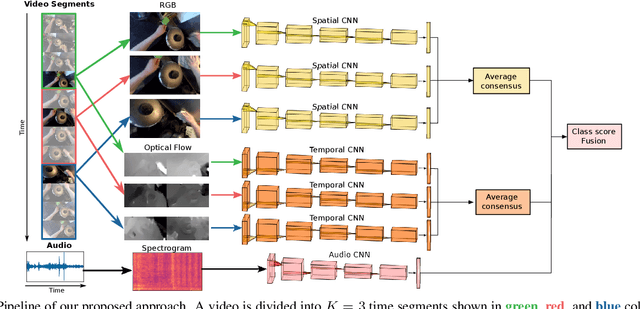
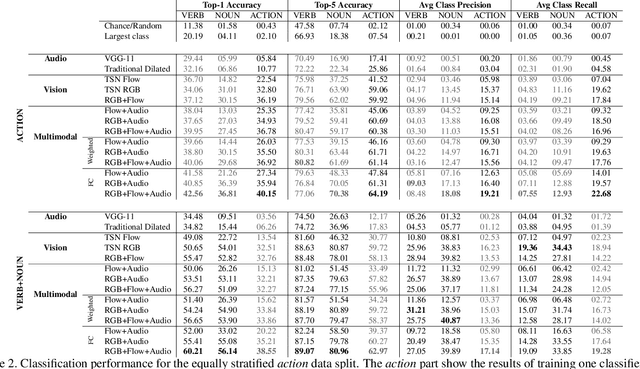
Our interaction with the world is an inherently multimodal experience. However, the understanding of human-to-object interactions has historically been addressed focusing on a single modality. In particular, a limited number of works have considered to integrate the visual and audio modalities for this purpose. In this work, we propose a multimodal approach for egocentric action recognition in a kitchen environment that relies on audio and visual information. Our model combines a sparse temporal sampling strategy with a late fusion of audio, spatial, and temporal streams. Experimental results on the EPIC-Kitchens dataset show that multimodal integration leads to better performance than unimodal approaches. In particular, we achieved a 5.18% improvement over the state of the art on verb classification.
How Much Does Audio Matter to Recognize Egocentric Object Interactions?
Jun 03, 2019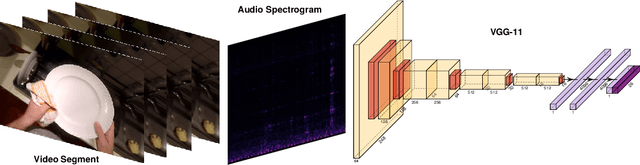
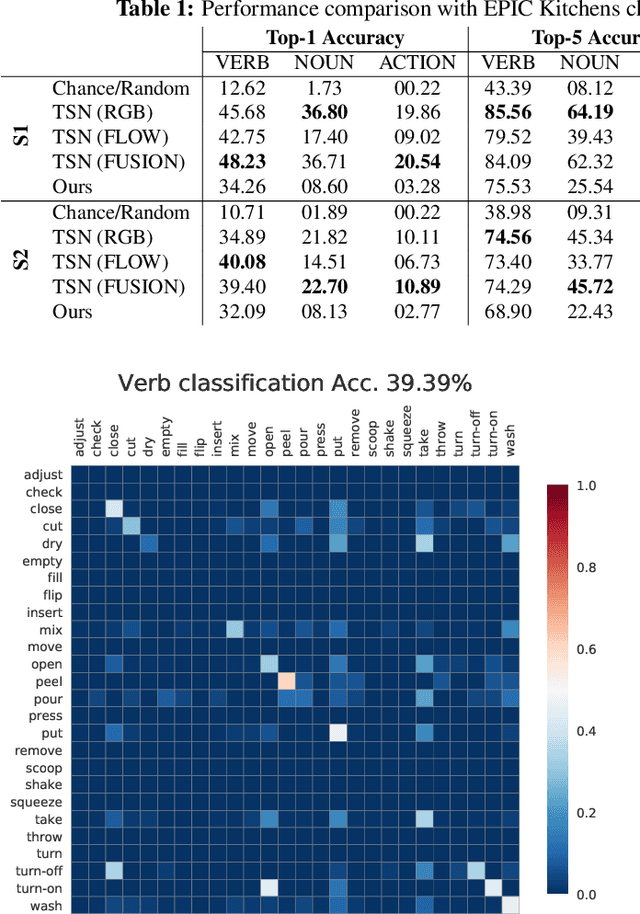

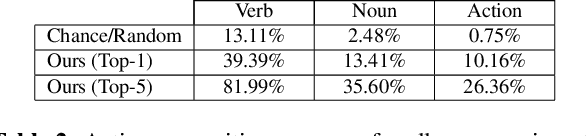
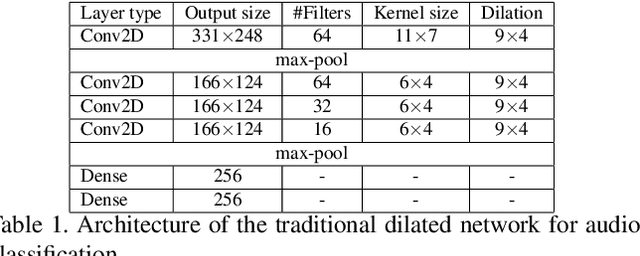
Sounds are an important source of information on our daily interactions with objects. For instance, a significant amount of people can discern the temperature of water that it is being poured just by using the sense of hearing. However, only a few works have explored the use of audio for the classification of object interactions in conjunction with vision or as single modality. In this preliminary work, we propose an audio model for egocentric action recognition and explore its usefulness on the parts of the problem (noun, verb, and action classification). Our model achieves a competitive result in terms of verb classification (34.26% accuracy) on a standard benchmark with respect to vision-based state of the art systems, using a comparatively lighter architecture.
On the Role of Event Boundaries in Egocentric Activity Recognition from Photostreams
Sep 06, 2018
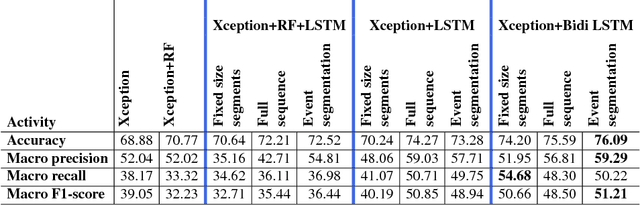

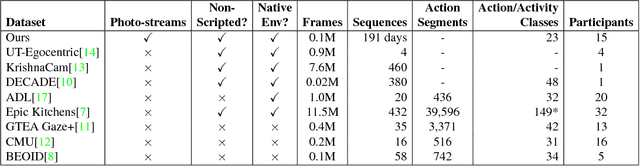
Event boundaries play a crucial role as a pre-processing step for detection, localization, and recognition tasks of human activities in videos. Typically, although their intrinsic subjectiveness, temporal bounds are provided manually as input for training action recognition algorithms. However, their role for activity recognition in the domain of egocentric photostreams has been so far neglected. In this paper, we provide insights of how automatically computed boundaries can impact activity recognition results in the emerging domain of egocentric photostreams. Furthermore, we collected a new annotated dataset acquired by 15 people by a wearable photo-camera and we used it to show the generalization capabilities of several deep learning based architectures to unseen users.
Batch-based Activity Recognition from Egocentric Photo-Streams Revisited
May 09, 2018
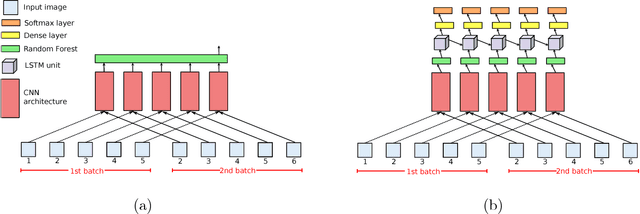
Wearable cameras can gather large a\-mounts of image data that provide rich visual information about the daily activities of the wearer. Motivated by the large number of health applications that could be enabled by the automatic recognition of daily activities, such as lifestyle characterization for habit improvement, context-aware personal assistance and tele-rehabilitation services, we propose a system to classify 21 daily activities from photo-streams acquired by a wearable photo-camera. Our approach combines the advantages of a Late Fusion Ensemble strategy relying on convolutional neural networks at image level with the ability of recurrent neural networks to account for the temporal evolution of high level features in photo-streams without relying on event boundaries. The proposed batch-based approach achieved an overall accuracy of 89.85\%, outperforming state of the art end-to-end methodologies. These results were achieved on a dataset consists of 44,902 egocentric pictures from three persons captured during 26 days in average.
Determination of Digital Straight Segments Using the Slope
Jan 20, 2018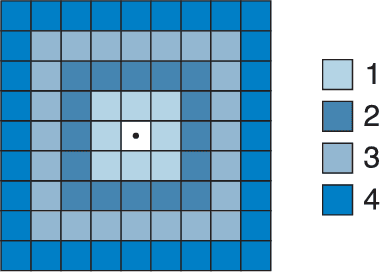
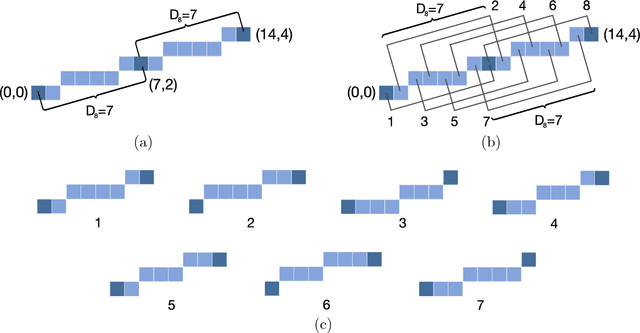
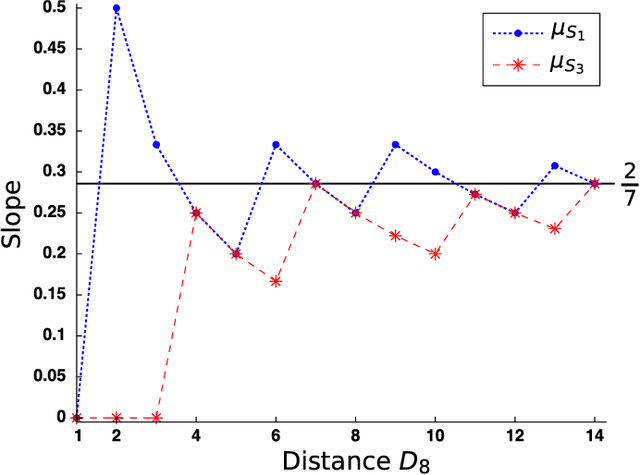
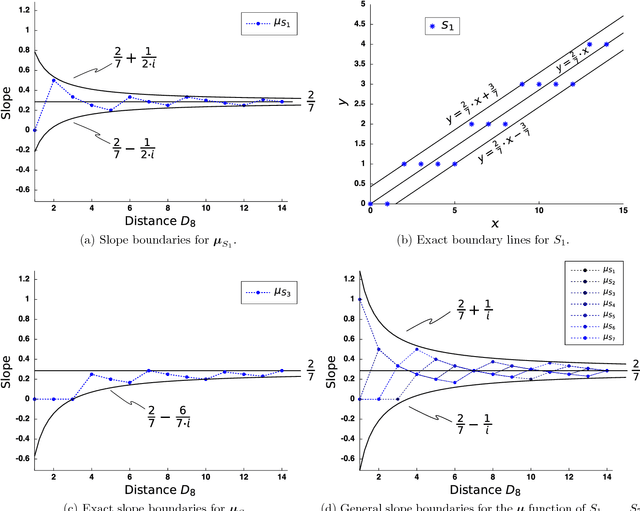
We present a new method for the recognition of digital straight lines based on the slope. This method combines the Freeman's chain coding scheme and new discovered properties of the digital slope introduced in this paper. We also present the efficiency of our method from a testbed.
Detecting Hands in Egocentric Videos: Towards Action Recognition
Sep 08, 2017
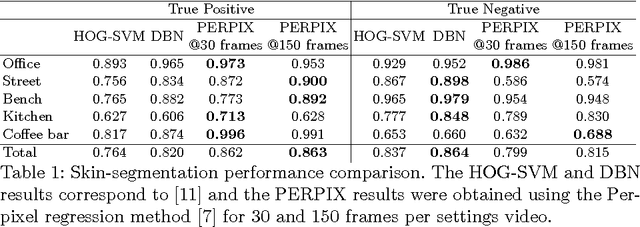

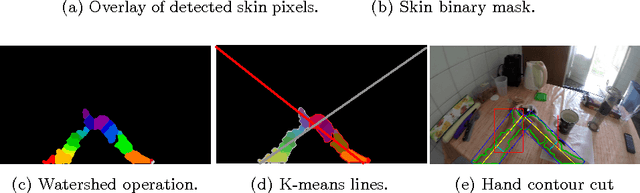
Recently, there has been a growing interest in analyzing human daily activities from data collected by wearable cameras. Since the hands are involved in a vast set of daily tasks, detecting hands in egocentric images is an important step towards the recognition of a variety of egocentric actions. However, besides extreme illumination changes in egocentric images, hand detection is not a trivial task because of the intrinsic large variability of hand appearance. We propose a hand detector that exploits skin modeling for fast hand proposal generation and Convolutional Neural Networks for hand recognition. We tested our method on UNIGE-HANDS dataset and we showed that the proposed approach achieves competitive hand detection results.
Batch-Based Activity Recognition from Egocentric Photo-Streams
Aug 25, 2017
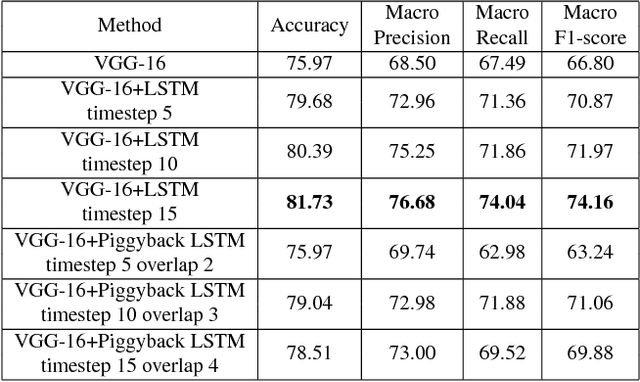
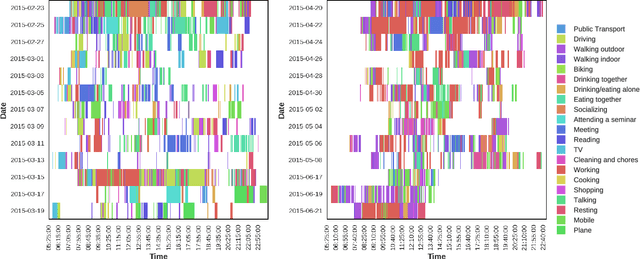
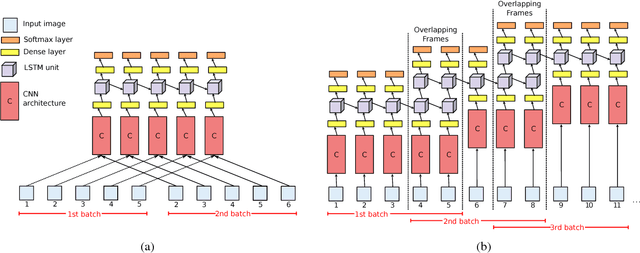
Activity recognition from long unstructured egocentric photo-streams has several applications in assistive technology such as health monitoring and frailty detection, just to name a few. However, one of its main technical challenges is to deal with the low frame rate of wearable photo-cameras, which causes abrupt appearance changes between consecutive frames. In consequence, important discriminatory low-level features from motion such as optical flow cannot be estimated. In this paper, we present a batch-driven approach for training a deep learning architecture that strongly rely on Long short-term units to tackle this problem. We propose two different implementations of the same approach that process a photo-stream sequence using batches of fixed size with the goal of capturing the temporal evolution of high-level features. The main difference between these implementations is that one explicitly models consecutive batches by overlapping them. Experimental results over a public dataset acquired by three users demonstrate the validity of the proposed architectures to exploit the temporal evolution of convolutional features over time without relying on event boundaries.
Recognizing Activities of Daily Living from Egocentric Images
Apr 13, 2017
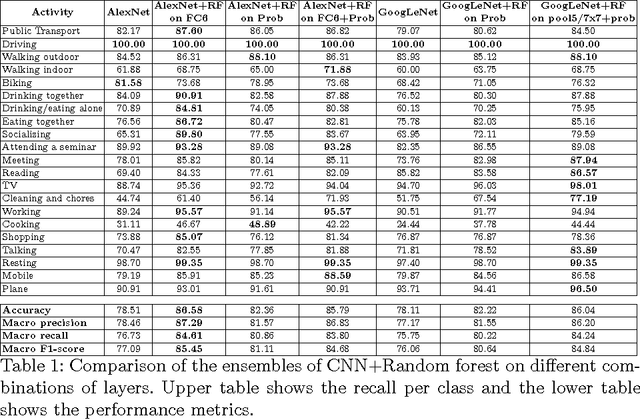
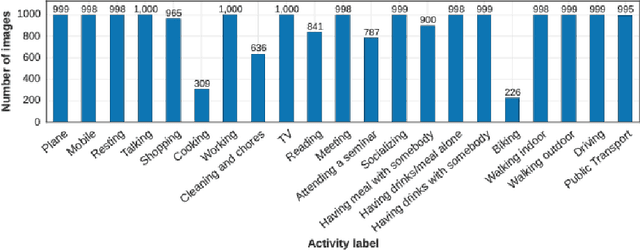
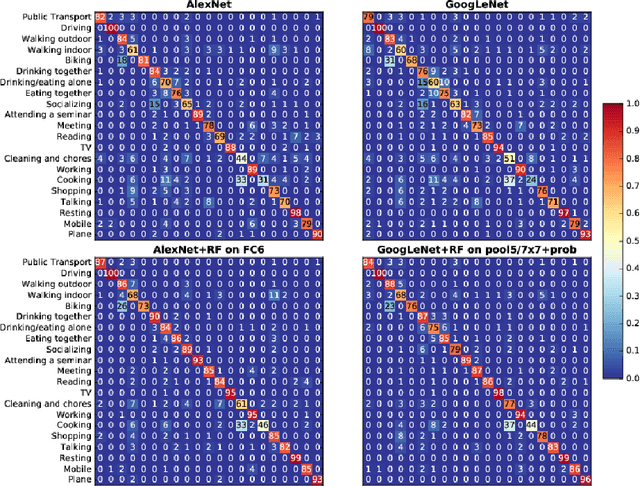
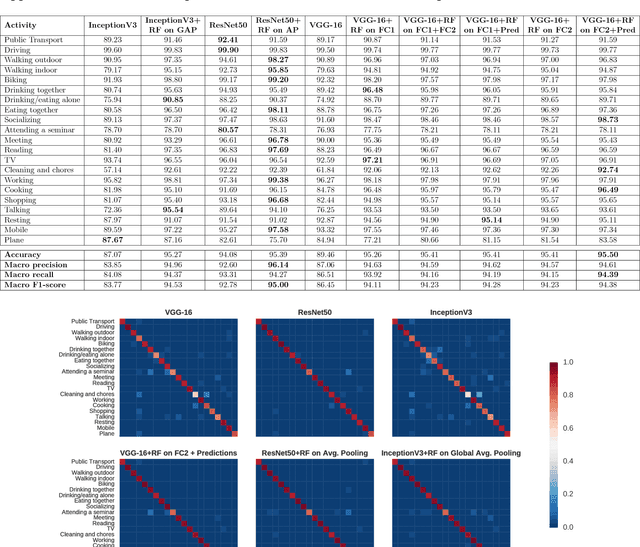
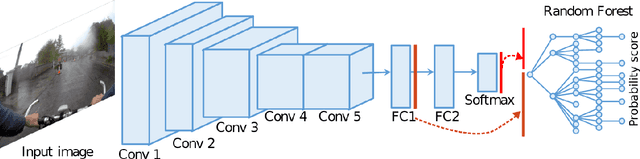
Recognizing Activities of Daily Living (ADLs) has a large number of health applications, such as characterize lifestyle for habit improvement, nursing and rehabilitation services. Wearable cameras can daily gather large amounts of image data that provide rich visual information about ADLs than using other wearable sensors. In this paper, we explore the classification of ADLs from images captured by low temporal resolution wearable camera (2fpm) by using a Convolutional Neural Networks (CNN) approach. We show that the classification accuracy of a CNN largely improves when its output is combined, through a random decision forest, with contextual information from a fully connected layer. The proposed method was tested on a subset of the NTCIR-12 egocentric dataset, consisting of 18,674 images and achieved an overall accuracy of 86% activity recognition on 21 classes.