 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing the contribution of dependent features in XAI methods
Apr 04, 2023



Explainable Artificial Intelligence (XAI) provides tools to help understanding how the machine learning models work and reach a specific outcome. It helps to increase the interpretability of models and makes the models more trustworthy and transparent. In this context, many XAI methods were proposed being SHAP and LIME the most popular. However, the proposed methods assume that used predictors in the machine learning models are independent which in general is not necessarily true. Such assumption casts shadows on the robustness of the XAI outcomes such as the list of informative predictors. Here, we propose a simple, yet useful proxy that modifies the outcome of any XAI feature ranking method allowing to account for the dependency among the predictors. The proposed approach has the advantage of being model-agnostic as well as simple to calculate the impact of each predictor in the model in presence of collinearity.
Pre-NeRF 360: Enriching Unbounded Appearances for Neural Radiance Fields
Mar 21, 2023



Neural radiance fields (NeRF) appeared recently as a powerful tool to generate realistic views of objects and confined areas. Still, they face serious challenges with open scenes, where the camera has unrestricted movement and content can appear at any distance. In such scenarios, current NeRF-inspired models frequently yield hazy or pixelated outputs, suffer slow training times, and might display irregularities, because of the challenging task of reconstructing an extensive scene from a limited number of images. We propose a new framework to boost the performance of NeRF-based architectures yielding significantly superior outcomes compared to the prior work. Our solution overcomes several obstacles that plagued earlier versions of NeRF, including handling multiple video inputs, selecting keyframes, and extracting poses from real-world frames that are ambiguous and symmetrical. Furthermore, we applied our framework, dubbed as "Pre-NeRF 360", to enable the use of the Nutrition5k dataset in NeRF and introduce an updated version of this dataset, known as the N5k360 dataset.
ELFIS: Expert Learning for Fine-grained Image Recognition Using Subsets
Mar 16, 2023



Fine-Grained Visual Recognition (FGVR) tackles the problem of distinguishing highly similar categories. One of the main approaches to FGVR, namely subset learning, tries to leverage information from existing class taxonomies to improve the performance of deep neural networks. However, these methods rely on the existence of handcrafted hierarchies that are not necessarily optimal for the models. In this paper, we propose ELFIS, an expert learning framework for FGVR that clusters categories of the dataset into meta-categories using both dataset-inherent lexical and model-specific information. A set of neural networks-based experts are trained focusing on the meta-categories and are integrated into a multi-task framework. Extensive experimentation shows improvements in the SoTA FGVR benchmarks of up to +1.3% of accuracy using both CNNs and transformer-based networks. Overall, the obtained results evidence that ELFIS can be applied on top of any classification model, enabling the obtention of SoTA results. The source code will be made public soon.
All4One: Symbiotic Neighbour Contrastive Learning via Self-Attention and Redundancy Reduction
Mar 16, 2023Nearest neighbour based methods have proved to be one of the most successful self-supervised learning (SSL) approaches due to their high generalization capabilities. However, their computational efficiency decreases when more than one neighbour is used. In this paper, we propose a novel contrastive SSL approach, which we call All4One, that reduces the distance between neighbour representations using ''centroids'' created through a self-attention mechanism. We use a Centroid Contrasting objective along with single Neighbour Contrasting and Feature Contrasting objectives. Centroids help in learning contextual information from multiple neighbours whereas the neighbour contrast enables learning representations directly from the neighbours and the feature contrast allows learning representations unique to the features. This combination enables All4One to outperform popular instance discrimination approaches by more than 1% on linear classification evaluation for popular benchmark datasets and obtains state-of-the-art (SoTA) results. Finally, we show that All4One is robust towards embedding dimensionalities and augmentations, surpassing NNCLR and Barlow Twins by more than 5% on low dimensionality and weak augmentation settings. The source code would be made available soon.
Hyper-Spectral Imaging for Overlapping Plastic Flakes Segmentation
Mar 23, 2022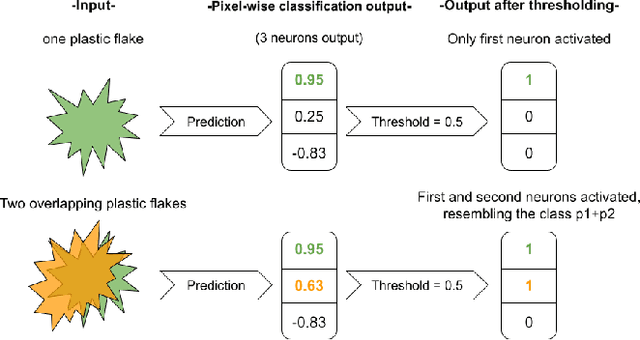
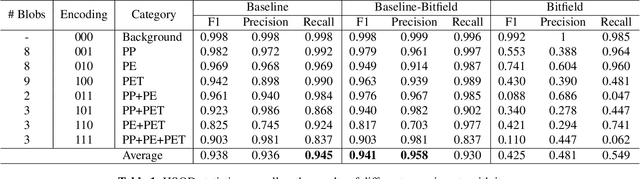

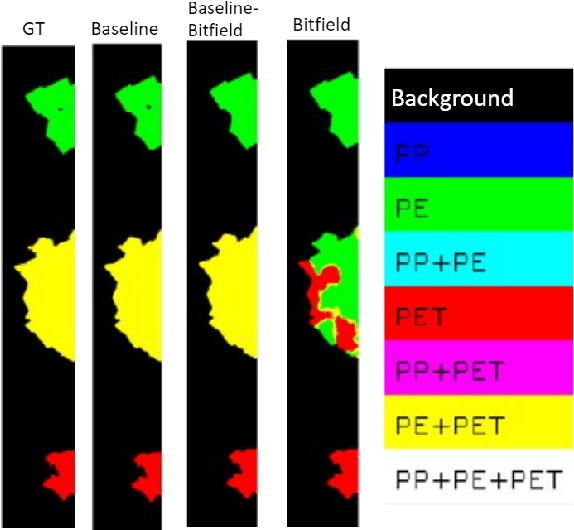
Given the hyper-spectral imaging unique potentials in grasping the polymer characteristics of different materials, it is commonly used in sorting procedures. In a practical plastic sorting scenario, multiple plastic flakes may overlap which depending on their characteristics, the overlap can be reflected in their spectral signature. In this work, we use hyper-spectral imaging for the segmentation of three types of plastic flakes and their possible overlapping combinations. We propose an intuitive and simple multi-label encoding approach, bitfield encoding, to account for the overlapping regions. With our experiments, we show that the bitfield encoding improves over the baseline single-label approach and we further demonstrate its potential in predicting multiple labels for overlapping classes even when the model is only trained with non-overlapping classes.
Layer Ensembles: A Single-Pass Uncertainty Estimation in Deep Learning for Segmentation
Mar 16, 2022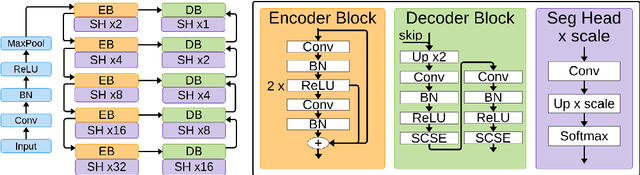

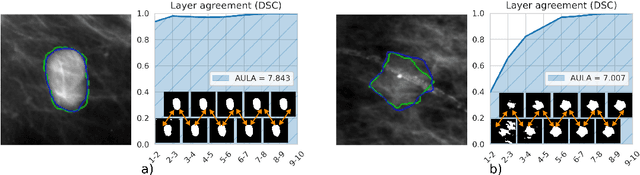
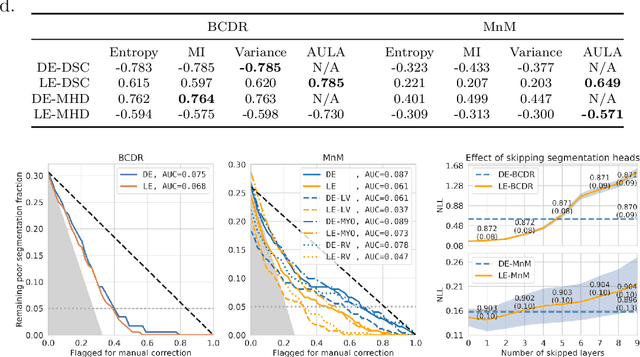
Uncertainty estimation in deep learning has become a leading research field in medical image analysis due to the need for safe utilisation of AI algorithms in clinical practice. Most approaches for uncertainty estimation require sampling the network weights multiple times during testing or training multiple networks. This leads to higher training and testing costs in terms of time and computational resources. In this paper, we propose Layer Ensembles, a novel uncertainty estimation method that uses a single network and requires only a single pass to estimate predictive uncertainty of a network. Moreover, we introduce an image-level uncertainty metric, which is more beneficial for segmentation tasks compared to the commonly used pixel-wise metrics such as entropy and variance. We evaluate our approach on 2D and 3D, binary and multi-class medical image segmentation tasks. Our method shows competitive results with state-of-the-art Deep Ensembles, requiring only a single network and a single pass.
Modeling long-term interactions to enhance action recognition
Apr 23, 2021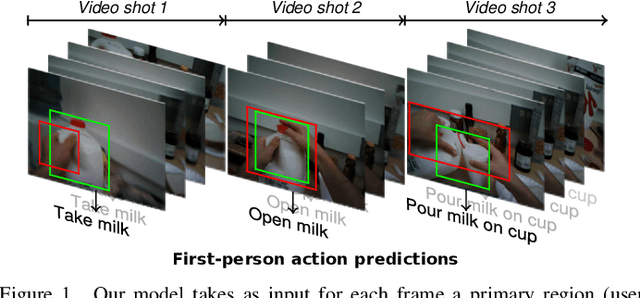

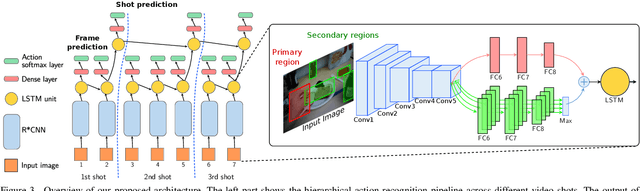
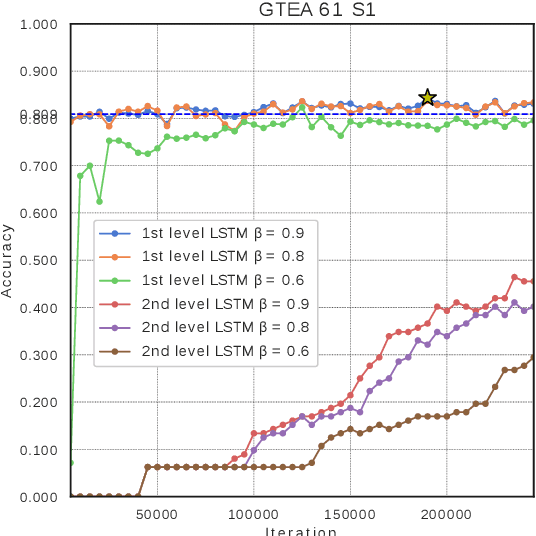
In this paper, we propose a new approach to under-stand actions in egocentric videos that exploits the semantics of object interactions at both frame and temporal levels. At the frame level, we use a region-based approach that takes as input a primary region roughly corresponding to the user hands and a set of secondary regions potentially corresponding to the interacting objects and calculates the action score through a CNN formulation. This information is then fed to a Hierarchical LongShort-Term Memory Network (HLSTM) that captures temporal dependencies between actions within and across shots. Ablation studies thoroughly validate the proposed approach, showing in particular that both levels of the HLSTM architecture contribute to performance improvement. Furthermore, quantitative comparisons show that the proposed approach outperforms the state-of-the-art in terms of action recognition on standard benchmarks,without relying on motion information
Eating Habits Discovery in Egocentric Photo-streams
Sep 16, 2020

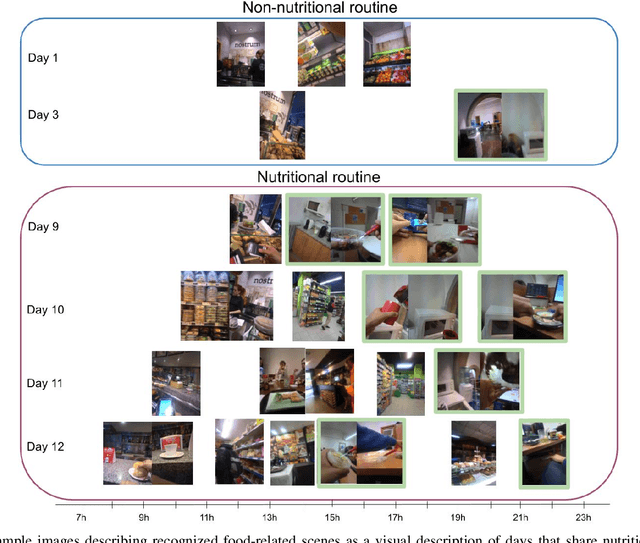
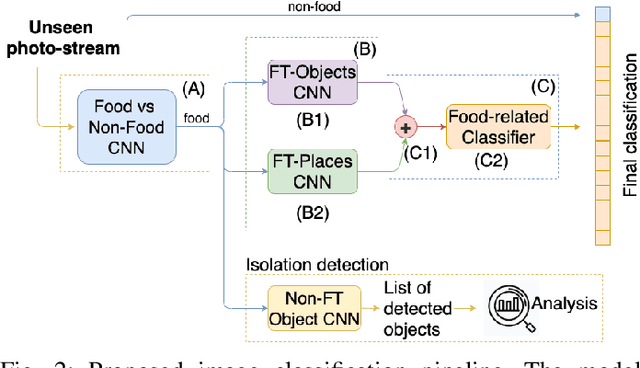
Eating habits are learned throughout the early stages of our lives. However, it is not easy to be aware of how our food-related routine affects our healthy living. In this work, we address the unsupervised discovery of nutritional habits from egocentric photo-streams. We build a food-related behavioural pattern discovery model, which discloses nutritional routines from the activities performed throughout the days. To do so, we rely on Dynamic-Time-Warping for the evaluation of similarity among the collected days. Within this framework, we present a simple, but robust and fast novel classification pipeline that outperforms the state-of-the-art on food-related image classification with a weighted accuracy and F-score of 70% and 63%, respectively. Later, we identify days composed of nutritional activities that do not describe the habits of the person as anomalies in the daily life of the user with the Isolation Forest method. Furthermore, we show an application for the identification of food-related scenes when the camera wearer eats in isolation. Results have shown the good performance of the proposed model and its relevance to visualize the nutritional habits of individuals.
Behavioural pattern discovery from collections of egocentric photo-streams
Aug 21, 2020
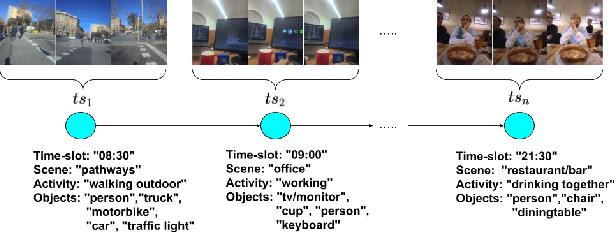
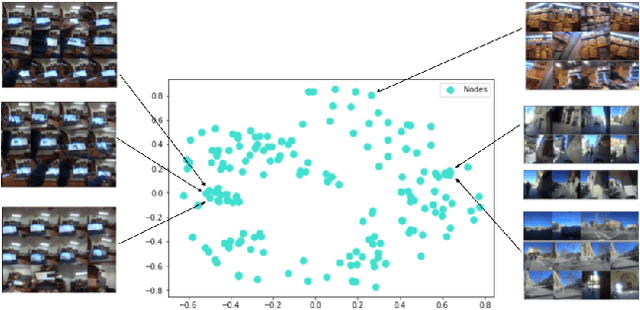
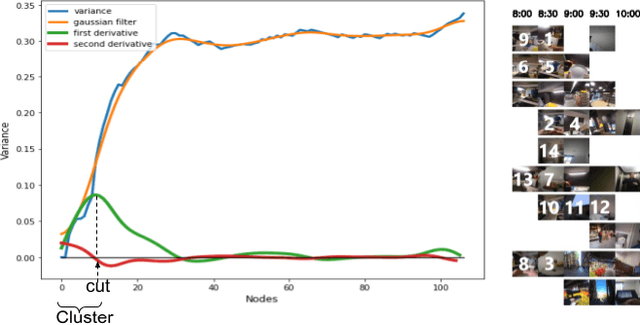
The automatic discovery of behaviour is of high importance when aiming to assess and improve the quality of life of people. Egocentric images offer a rich and objective description of the daily life of the camera wearer. This work proposes a new method to identify a person's patterns of behaviour from collected egocentric photo-streams. Our model characterizes time-frames based on the context (place, activities and environment objects) that define the images composition. Based on the similarity among the time-frames that describe the collected days for a user, we propose a new unsupervised greedy method to discover the behavioural pattern set based on a novel semantic clustering approach. Moreover, we present a new score metric to evaluate the performance of the proposed algorithm. We validate our method on 104 days and more than 100k images extracted from 7 users. Results show that behavioural patterns can be discovered to characterize the routine of individuals and consequently their lifestyle.
Exploration of Interpretability Techniques for Deep COVID-19 Classification using Chest X-ray Images
Jun 10, 2020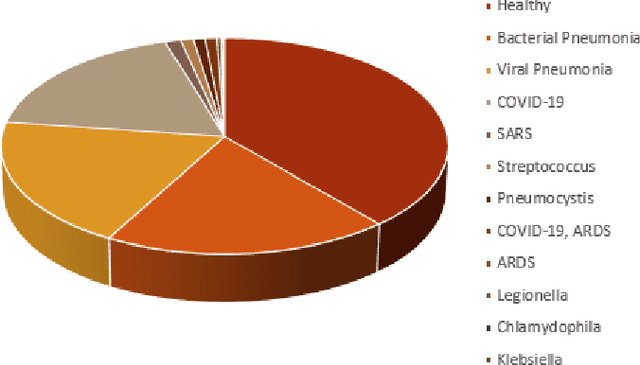
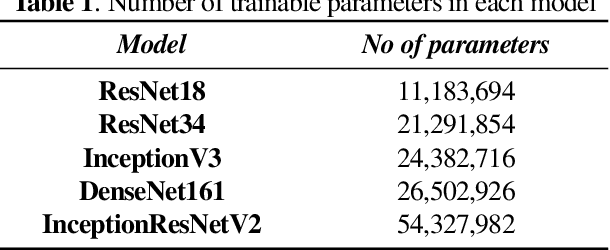
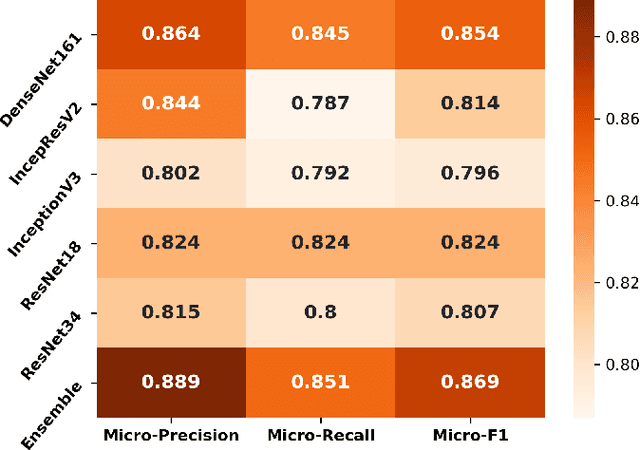
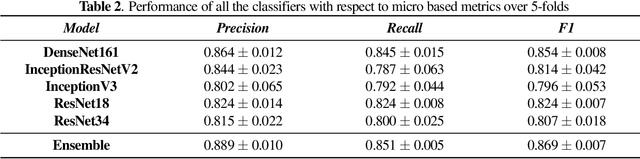
The outbreak of COVID-19 has shocked the entire world with its fairly rapid spread and has challenged different sectors. One of the most effective ways to limit its spread is the early and accurate diagnosis of infected patients. Medical imaging such as X-ray and Computed Tomography (CT) combined with the potential of Artificial Intelligence (AI) plays an essential role in supporting the medical staff in the diagnosis process. Thereby, the use of five different deep learning models (ResNet18, ResNet34, InceptionV3, InceptionResNetV2, and DenseNet161) and their Ensemble have been used in this paper, to classify COVID-19, pneumoni{\ae} and healthy subjects using Chest X-Ray. Multi-label classification was performed to predict multiple pathologies for each patient, if present. Foremost, the interpretability of each of the networks was thoroughly studied using techniques like occlusion, saliency, input X gradient, guided backpropagation, integrated gradients, and DeepLIFT. The mean Micro-F1 score of the models for COVID-19 classifications ranges from 0.66 to 0.875, and is 0.89 for the Ensemble of the network models. The qualitative results depicted the ResNets to be the most interpretable model.