 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCliNER 2.0: Accessible and Accurate Clinical Concept Extraction
Mar 06, 2018
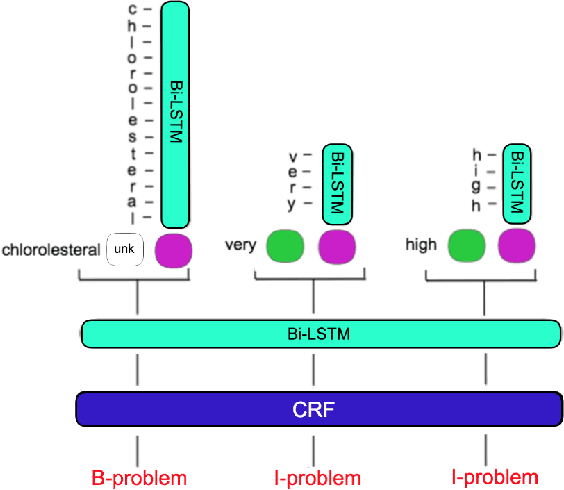

Clinical notes often describe important aspects of a patient's stay and are therefore critical to medical research. Clinical concept extraction (CCE) of named entities - such as problems, tests, and treatments - aids in forming an understanding of notes and provides a foundation for many downstream clinical decision-making tasks. Historically, this task has been posed as a standard named entity recognition (NER) sequence tagging problem, and solved with feature-based methods using handengineered domain knowledge. Recent advances, however, have demonstrated the efficacy of LSTM-based models for NER tasks, including CCE. This work presents CliNER 2.0, a simple-to-install, open-source tool for extracting concepts from clinical text. CliNER 2.0 uses a word- and character- level LSTM model, and achieves state-of-the-art performance. For ease of use, the tool also includes pre-trained models available for public use.
Representation and Reinforcement Learning for Personalized Glycemic Control in Septic Patients
Dec 02, 2017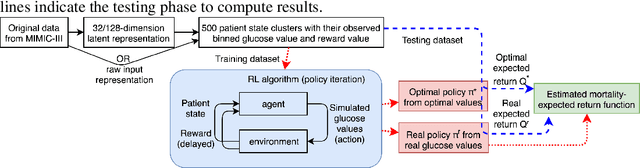

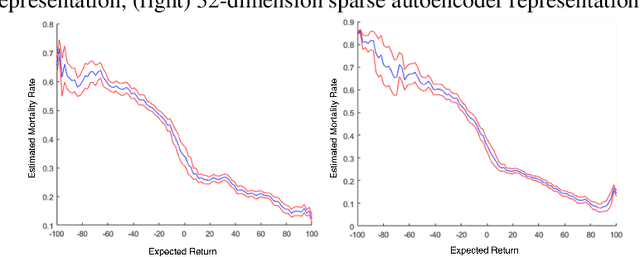
Glycemic control is essential for critical care. However, it is a challenging task because there has been no study on personalized optimal strategies for glycemic control. This work aims to learn personalized optimal glycemic trajectories for severely ill septic patients by learning data-driven policies to identify optimal targeted blood glucose levels as a reference for clinicians. We encoded patient states using a sparse autoencoder and adopted a reinforcement learning paradigm using policy iteration to learn the optimal policy from data. We also estimated the expected return following the policy learned from the recorded glycemic trajectories, which yielded a function indicating the relationship between real blood glucose values and 90-day mortality rates. This suggests that the learned optimal policy could reduce the patients' estimated 90-day mortality rate by 6.3%, from 31% to 24.7%. The result demonstrates that reinforcement learning with appropriate patient state encoding can potentially provide optimal glycemic trajectories and allow clinicians to design a personalized strategy for glycemic control in septic patients.
Deep Reinforcement Learning for Sepsis Treatment
Nov 27, 2017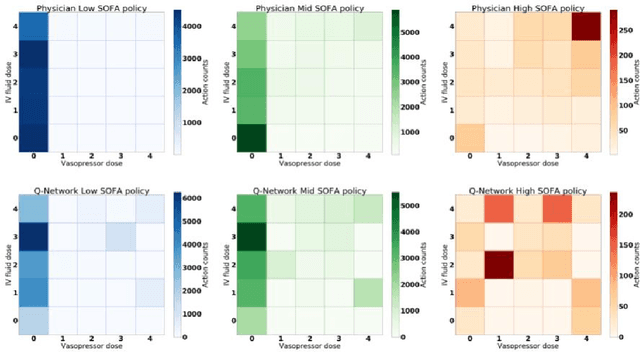

Sepsis is a leading cause of mortality in intensive care units and costs hospitals billions annually. Treating a septic patient is highly challenging, because individual patients respond very differently to medical interventions and there is no universally agreed-upon treatment for sepsis. In this work, we propose an approach to deduce treatment policies for septic patients by using continuous state-space models and deep reinforcement learning. Our model learns clinically interpretable treatment policies, similar in important aspects to the treatment policies of physicians. The learned policies could be used to aid intensive care clinicians in medical decision making and improve the likelihood of patient survival.
Clinical Intervention Prediction and Understanding using Deep Networks
May 23, 2017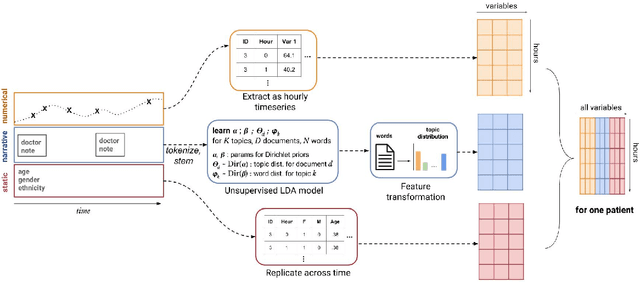
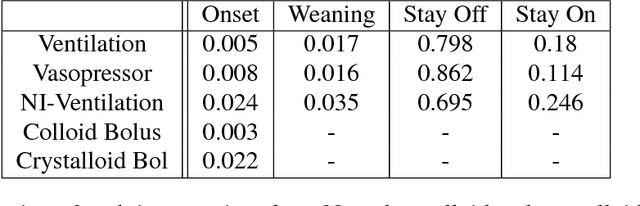
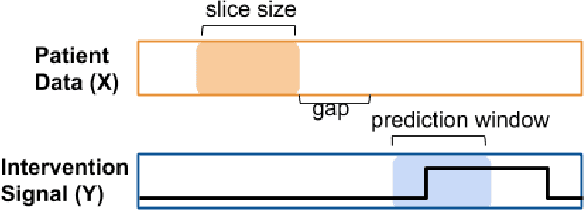
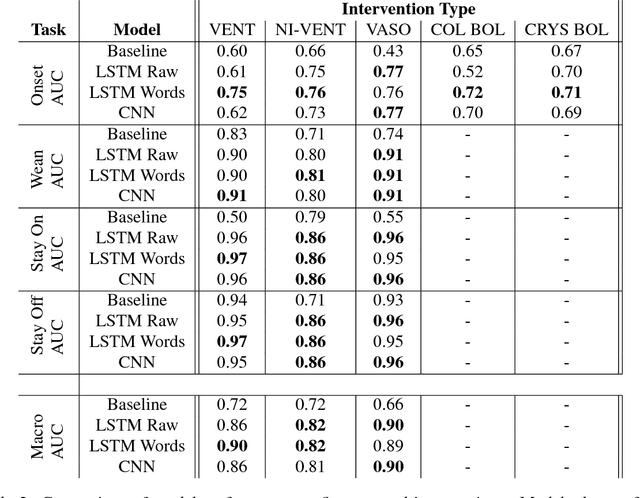
Real-time prediction of clinical interventions remains a challenge within intensive care units (ICUs). This task is complicated by data sources that are noisy, sparse, heterogeneous and outcomes that are imbalanced. In this paper, we integrate data from all available ICU sources (vitals, labs, notes, demographics) and focus on learning rich representations of this data to predict onset and weaning of multiple invasive interventions. In particular, we compare both long short-term memory networks (LSTM) and convolutional neural networks (CNN) for prediction of five intervention tasks: invasive ventilation, non-invasive ventilation, vasopressors, colloid boluses, and crystalloid boluses. Our predictions are done in a forward-facing manner to enable "real-time" performance, and predictions are made with a six hour gap time to support clinically actionable planning. We achieve state-of-the-art results on our predictive tasks using deep architectures. We explore the use of feature occlusion to interpret LSTM models, and compare this to the interpretability gained from examining inputs that maximally activate CNN outputs. We show that our models are able to significantly outperform baselines in intervention prediction, and provide insight into model learning, which is crucial for the adoption of such models in practice.
Continuous State-Space Models for Optimal Sepsis Treatment - a Deep Reinforcement Learning Approach
May 23, 2017
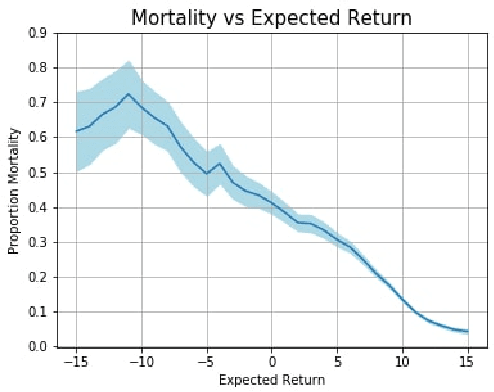

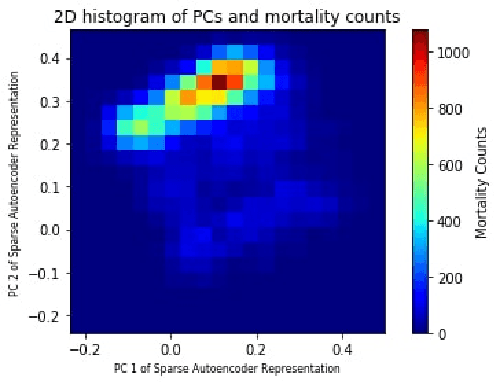
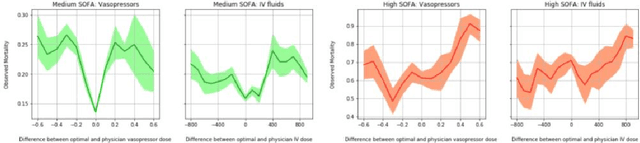
Sepsis is a leading cause of mortality in intensive care units (ICUs) and costs hospitals billions annually. Treating a septic patient is highly challenging, because individual patients respond very differently to medical interventions and there is no universally agreed-upon treatment for sepsis. Understanding more about a patient's physiological state at a given time could hold the key to effective treatment policies. In this work, we propose a new approach to deduce optimal treatment policies for septic patients by using continuous state-space models and deep reinforcement learning. Learning treatment policies over continuous spaces is important, because we retain more of the patient's physiological information. Our model is able to learn clinically interpretable treatment policies, similar in important aspects to the treatment policies of physicians. Evaluating our algorithm on past ICU patient data, we find that our model could reduce patient mortality in the hospital by up to 3.6% over observed clinical policies, from a baseline mortality of 13.7%. The learned treatment policies could be used to aid intensive care clinicians in medical decision making and improve the likelihood of patient survival.
Transfer Learning for Named-Entity Recognition with Neural Networks
May 17, 2017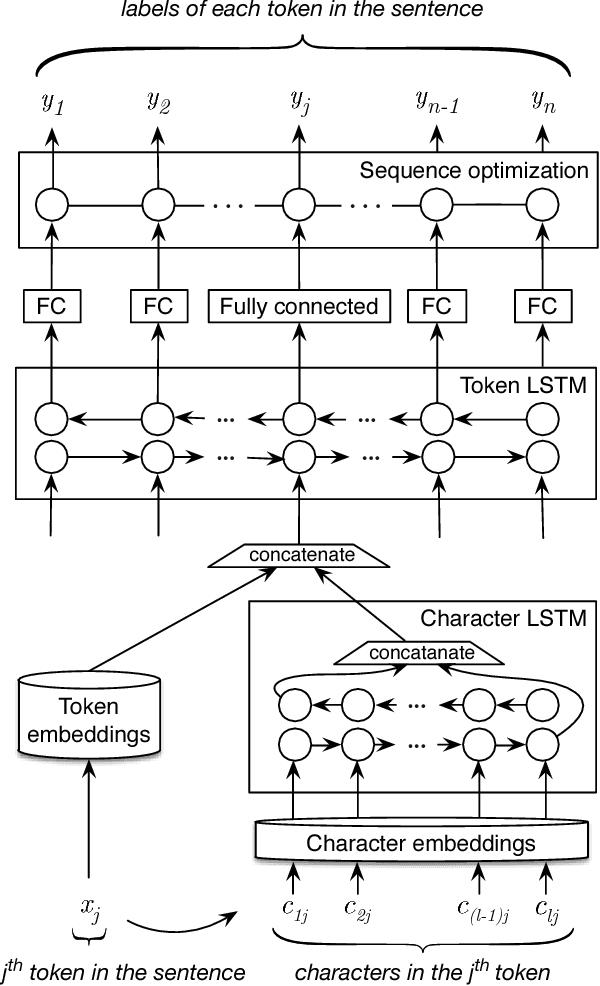

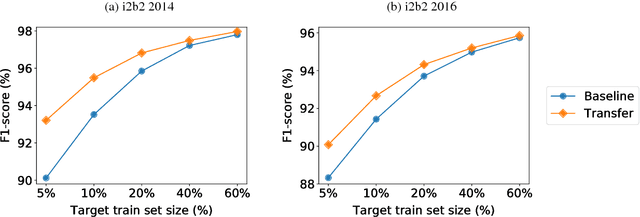
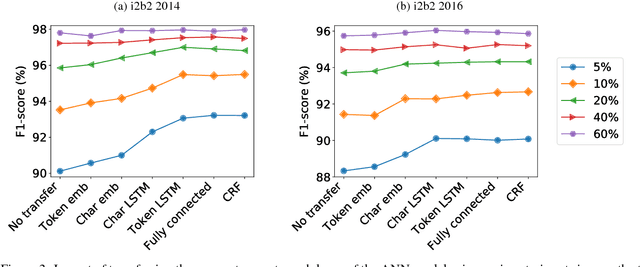
Recent approaches based on artificial neural networks (ANNs) have shown promising results for named-entity recognition (NER). In order to achieve high performances, ANNs need to be trained on a large labeled dataset. However, labels might be difficult to obtain for the dataset on which the user wants to perform NER: label scarcity is particularly pronounced for patient note de-identification, which is an instance of NER. In this work, we analyze to what extent transfer learning may address this issue. In particular, we demonstrate that transferring an ANN model trained on a large labeled dataset to another dataset with a limited number of labels improves upon the state-of-the-art results on two different datasets for patient note de-identification.
NeuroNER: an easy-to-use program for named-entity recognition based on neural networks
May 16, 2017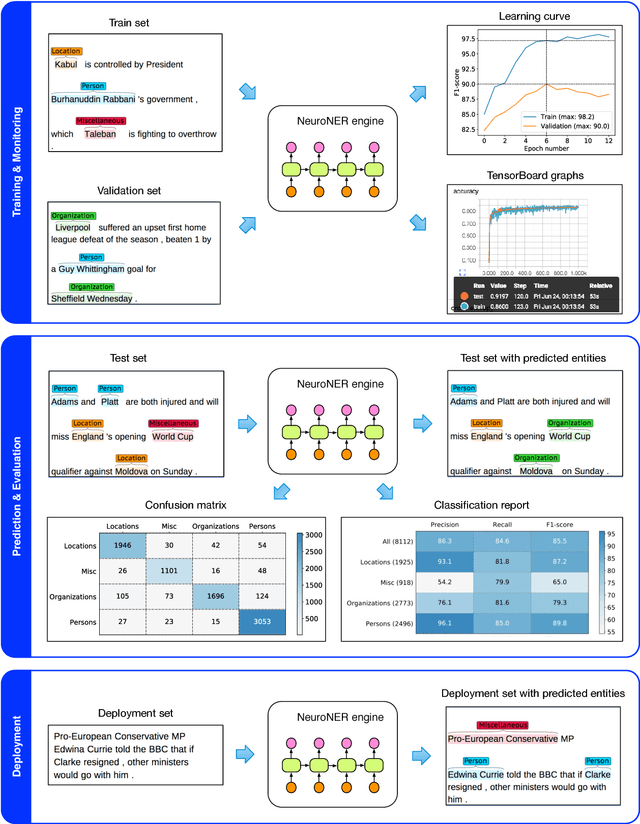
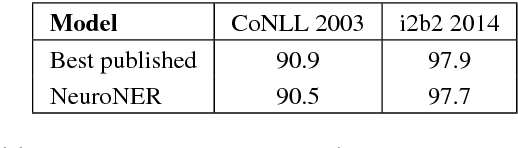
Named-entity recognition (NER) aims at identifying entities of interest in a text. Artificial neural networks (ANNs) have recently been shown to outperform existing NER systems. However, ANNs remain challenging to use for non-expert users. In this paper, we present NeuroNER, an easy-to-use named-entity recognition tool based on ANNs. Users can annotate entities using a graphical web-based user interface (BRAT): the annotations are then used to train an ANN, which in turn predict entities' locations and categories in new texts. NeuroNER makes this annotation-training-prediction flow smooth and accessible to anyone.
MIT at SemEval-2017 Task 10: Relation Extraction with Convolutional Neural Networks
Apr 05, 2017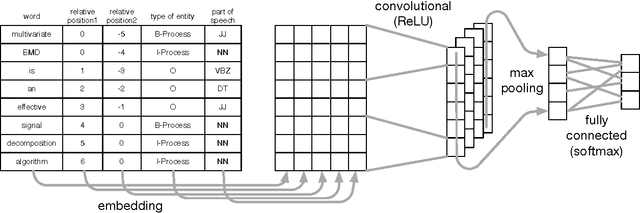

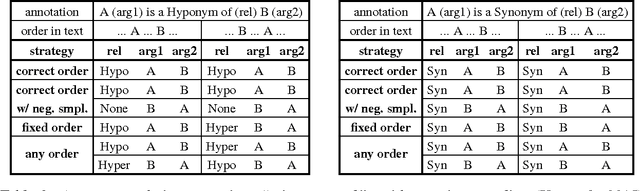
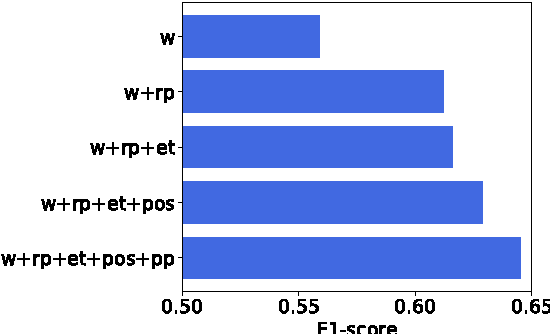
Over 50 million scholarly articles have been published: they constitute a unique repository of knowledge. In particular, one may infer from them relations between scientific concepts, such as synonyms and hyponyms. Artificial neural networks have been recently explored for relation extraction. In this work, we continue this line of work and present a system based on a convolutional neural network to extract relations. Our model ranked first in the SemEval-2017 task 10 (ScienceIE) for relation extraction in scientific articles (subtask C).
The Use of Autoencoders for Discovering Patient Phenotypes
Mar 20, 2017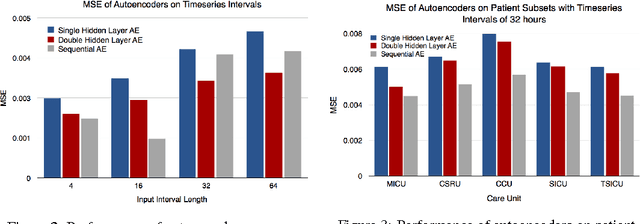
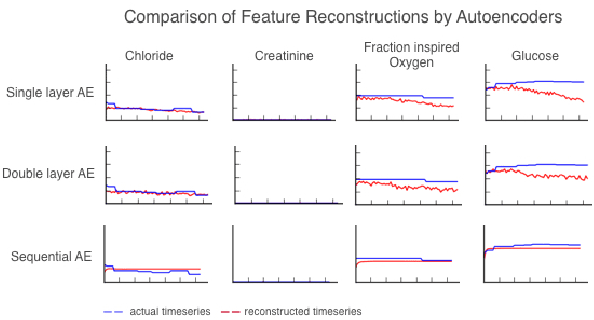
We use autoencoders to create low-dimensional embeddings of underlying patient phenotypes that we hypothesize are a governing factor in determining how different patients will react to different interventions. We compare the performance of autoencoders that take fixed length sequences of concatenated timesteps as input with a recurrent sequence-to-sequence autoencoder. We evaluate our methods on around 35,500 patients from the latest MIMIC III dataset from Beth Israel Deaconess Hospital.
Neural Networks for Joint Sentence Classification in Medical Paper Abstracts
Dec 15, 2016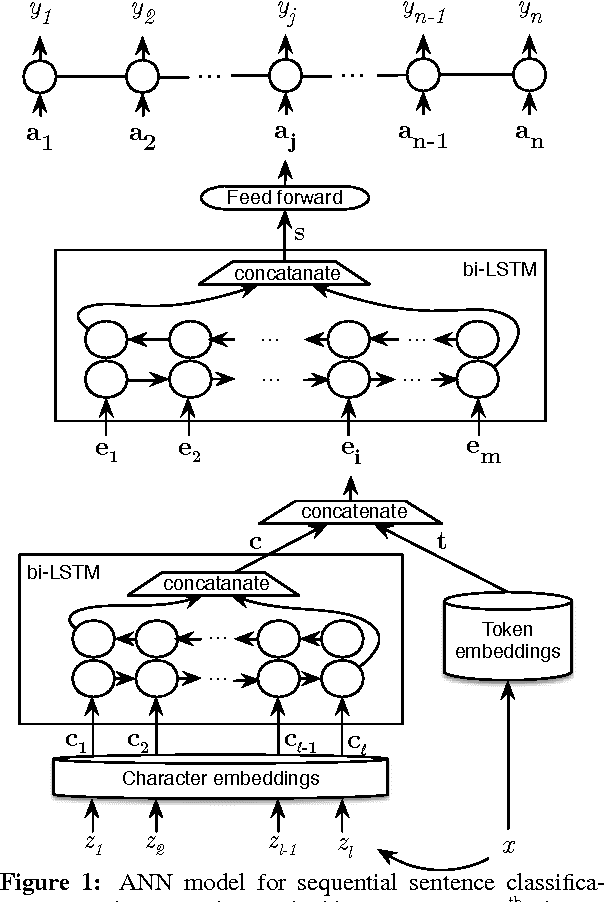
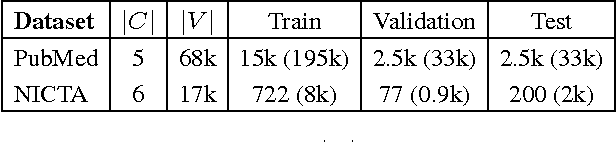
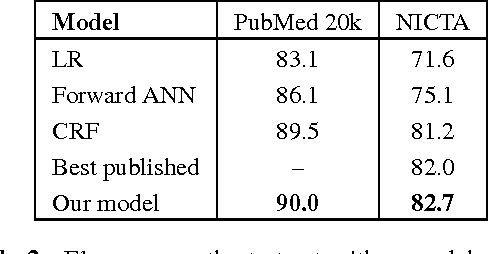
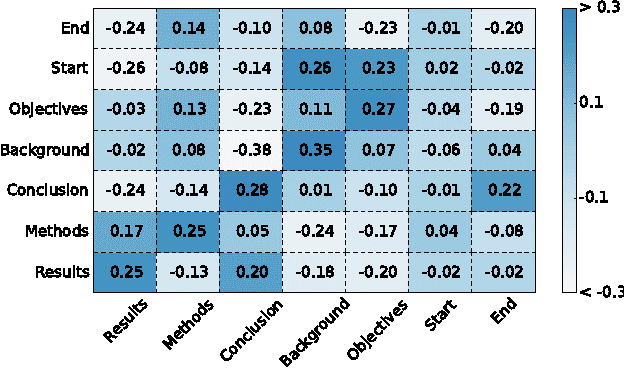
Existing models based on artificial neural networks (ANNs) for sentence classification often do not incorporate the context in which sentences appear, and classify sentences individually. However, traditional sentence classification approaches have been shown to greatly benefit from jointly classifying subsequent sentences, such as with conditional random fields. In this work, we present an ANN architecture that combines the effectiveness of typical ANN models to classify sentences in isolation, with the strength of structured prediction. Our model achieves state-of-the-art results on two different datasets for sequential sentence classification in medical abstracts.