 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Evaluation of Multi-task Learning and Multi-task Pre-training on EHR Time-series Data
Jul 20, 2020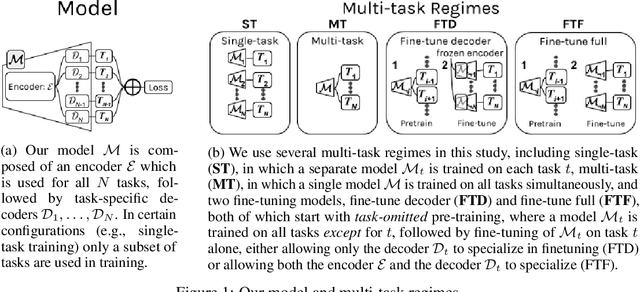
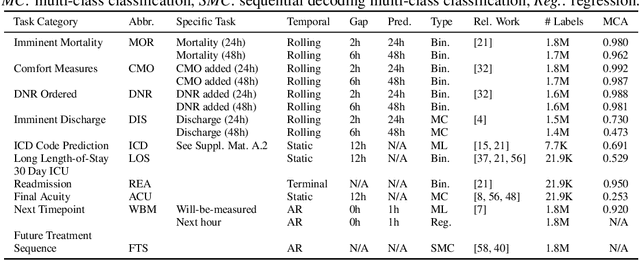
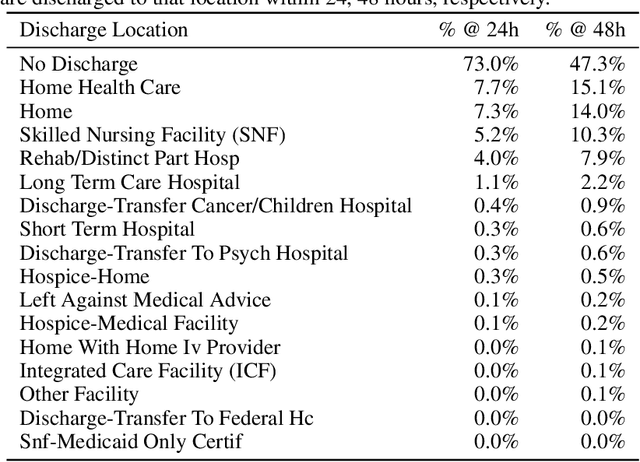
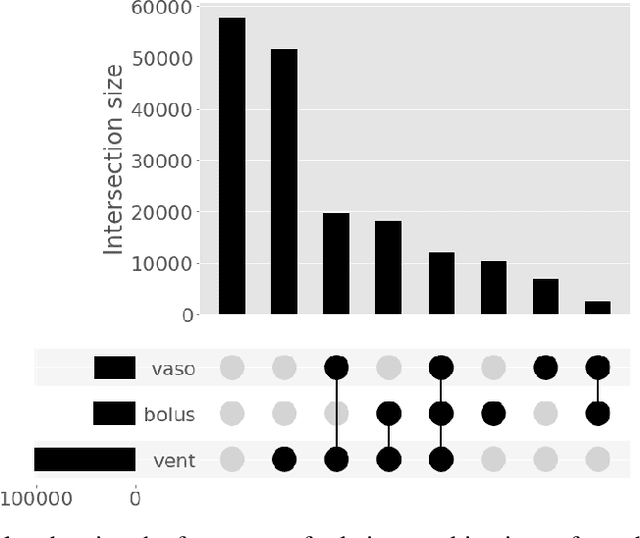
Multi-task learning (MTL) is a machine learning technique aiming to improve model performance by leveraging information across many tasks. It has been used extensively on various data modalities, including electronic health record (EHR) data. However, despite significant use on EHR data, there has been little systematic investigation of the utility of MTL across the diverse set of possible tasks and training schemes of interest in healthcare. In this work, we examine MTL across a battery of tasks on EHR time-series data. We find that while MTL does suffer from common negative transfer, we can realize significant gains via MTL pre-training combined with single-task fine-tuning. We demonstrate that these gains can be achieved in a task-independent manner and offer not only minor improvements under traditional learning, but also notable gains in a few-shot learning context, thereby suggesting this could be a scalable vehicle to offer improved performance in important healthcare contexts.
TransINT: Embedding Implication Rules in Knowledge Graphs with Isomorphic Intersections of Linear Subspaces
Jul 01, 2020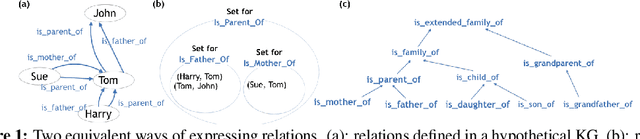
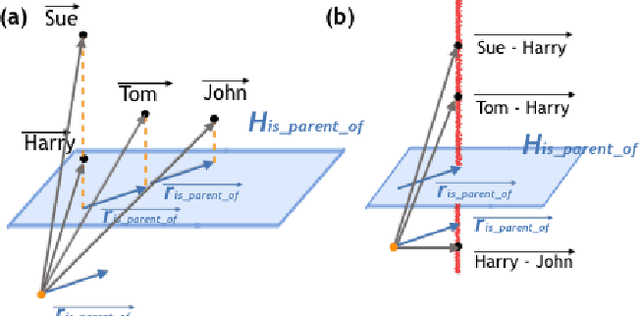
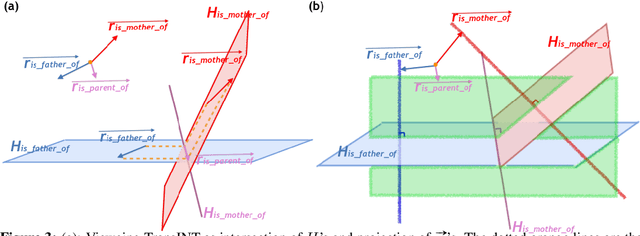
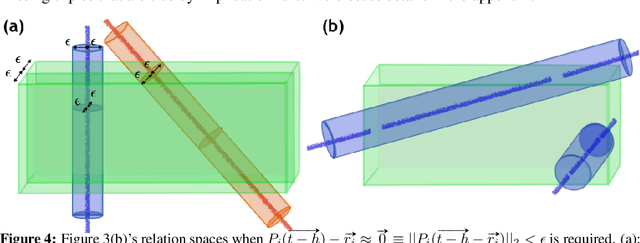
Knowledge Graphs (KG), composed of entities and relations, provide a structured representation of knowledge. For easy access to statistical approaches on relational data, multiple methods to embed a KG into f(KG) $\in$ R^d have been introduced. We propose TransINT, a novel and interpretable KG embedding method that isomorphically preserves the implication ordering among relations in the embedding space. Given implication rules, TransINT maps set of entities (tied by a relation) to continuous sets of vectors that are inclusion-ordered isomorphically to relation implications. With a novel parameter sharing scheme, TransINT enables automatic training on missing but implied facts without rule grounding. On a benchmark dataset, we outperform the best existing state-of-the-art rule integration embedding methods with significant margins in link Prediction and triple Classification. The angles between the continuous sets embedded by TransINT provide an interpretable way to mine semantic relatedness and implication rules among relations.
CheXpert++: Approximating the CheXpert labeler for Speed,Differentiability, and Probabilistic Output
Jun 26, 2020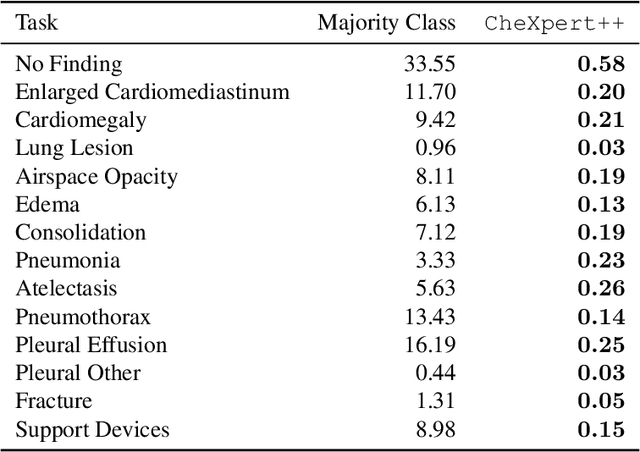
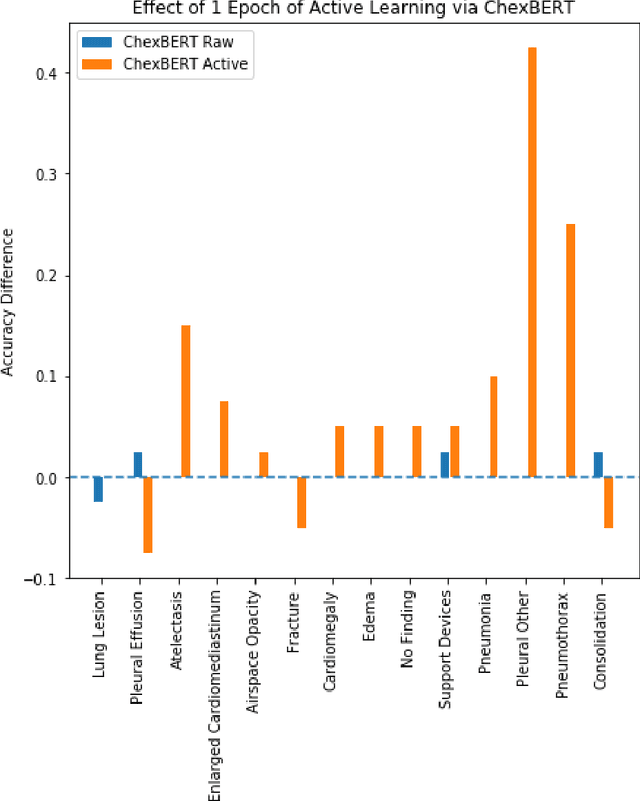
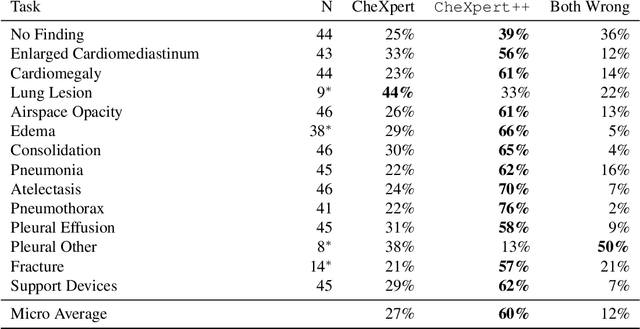
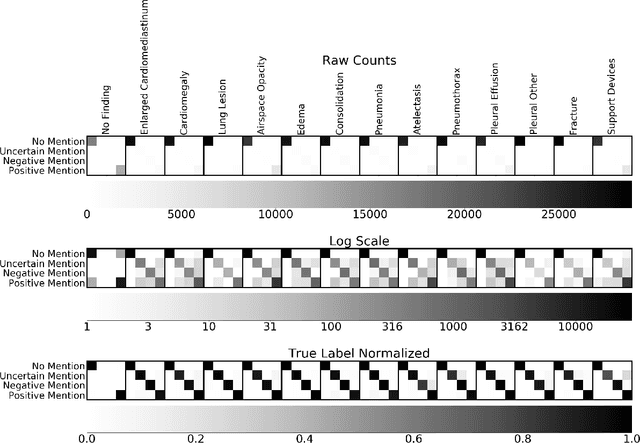
It is often infeasible or impossible to obtain ground truth labels for medical data. To circumvent this, one may build rule-based or other expert-knowledge driven labelers to ingest data and yield silver labels absent any ground-truth training data. One popular such labeler is CheXpert, a labeler that produces diagnostic labels for chest X-ray radiology reports. CheXpert is very useful, but is relatively computationally slow, especially when integrated with end-to-end neural pipelines, is non-differentiable so can't be used in any applications that require gradients to flow through the labeler, and does not yield probabilistic outputs, which limits our ability to improve the quality of the silver labeler through techniques such as active learning. In this work, we solve all three of these problems with $\texttt{CheXpert++}$, a BERT-based, high-fidelity approximation to CheXpert. $\texttt{CheXpert++}$ achieves 99.81\% parity with CheXpert, which means it can be reliably used as a drop-in replacement for CheXpert, all while being significantly faster, fully differentiable, and probabilistic in output. Error analysis of $\texttt{CheXpert++}$ also demonstrates that $\texttt{CheXpert++}$ has a tendency to actually correct errors in the CheXpert labels, with $\texttt{CheXpert++}$ labels being more often preferred by a clinician over CheXpert labels (when they disagree) on all but one disease task. To further demonstrate the utility of these advantages in this model, we conduct a proof-of-concept active learning study, demonstrating we can improve accuracy on an expert labeled random subset of report sentences by approximately 8\% over raw, unaltered CheXpert by using one-iteration of active-learning inspired re-training. These findings suggest that simple techniques in co-learning and active learning can yield high-quality labelers under minimal, and controllable human labeling demands.
Expert-Supervised Reinforcement Learning for Offline Policy Learning and Evaluation
Jun 23, 2020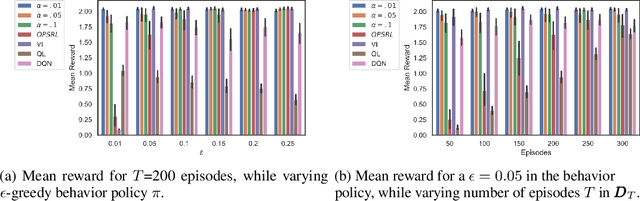
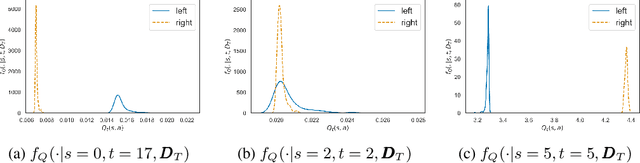
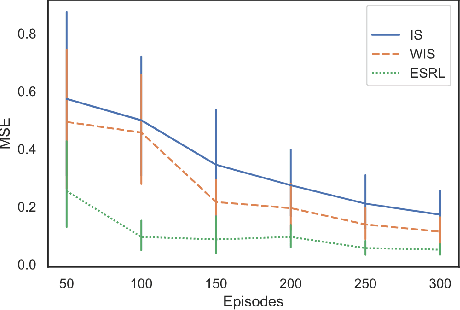
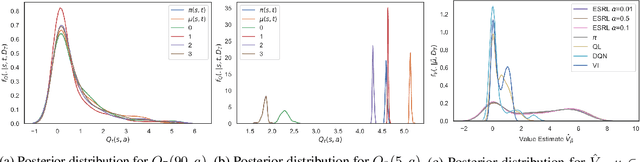
Offline Reinforcement Learning (RL) is a promising approach for learning optimal policies in environments where direct exploration is expensive or unfeasible. However, the adoption of such policies in practice is often challenging, as they are hard to interpret within the application context, and lack measures of uncertainty for the learned policy value and its decisions. To overcome these issues, we propose an Expert-Supervised RL (ESRL) framework which uses uncertainty quantification for offline policy learning. In particular, we have three contributions: 1) the method can learn safe and optimal policies through hypothesis testing, 2) ESRL allows for different levels of risk aversion within the application context, and finally, 3) we propose a way to interpret ESRL's policy at every state through posterior distributions, and use this framework to compute off-policy value function posteriors. We provide theoretical guarantees for our estimators and regret bounds consistent with Posterior Sampling for RL (PSRL) that account for any risk aversion threshold. We further propose an offline version of PSRL as a special case of ESRL.
Entity-Enriched Neural Models for Clinical Question Answering
May 13, 2020
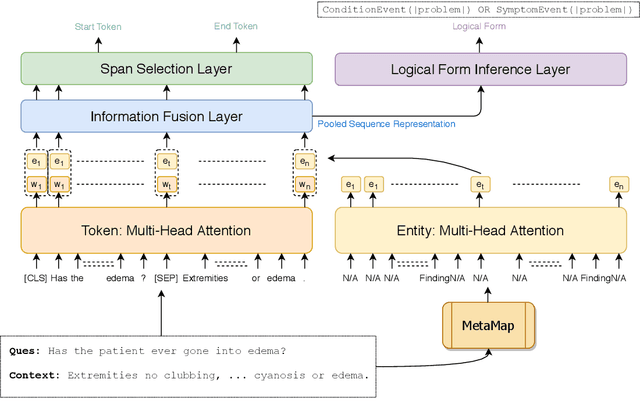
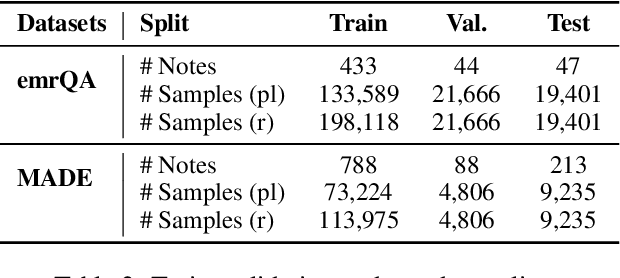
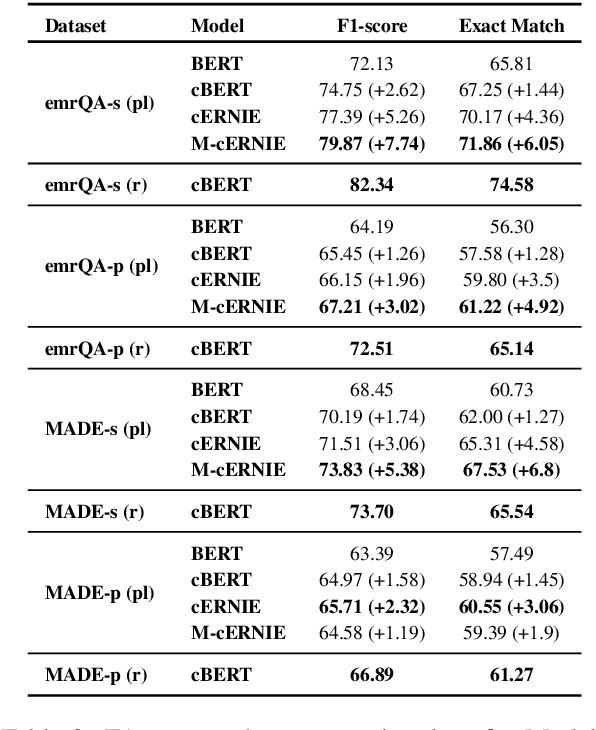
We explore state-of-the-art neural models for question answering on electronic medical records and improve their ability to generalize better on previously unseen (paraphrased) questions at test time. We enable this by learning to predict logical forms as an auxiliary task along with the main task of answer span detection. The predicted logical forms also serve as a rationale for the answer. Further, we also incorporate medical entity information in these models via the ERNIE architecture. We train our models on the large-scale emrQA dataset and observe that our multi-task entity-enriched models generalize to paraphrased questions ~5% better than the baseline BERT model.
Hooks in the Headline: Learning to Generate Headlines with Controlled Styles
Apr 30, 2020

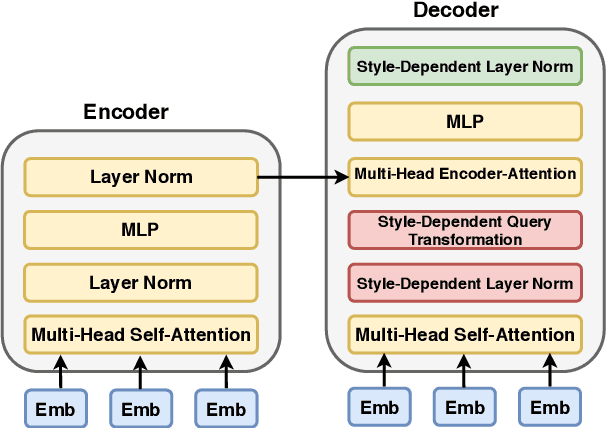
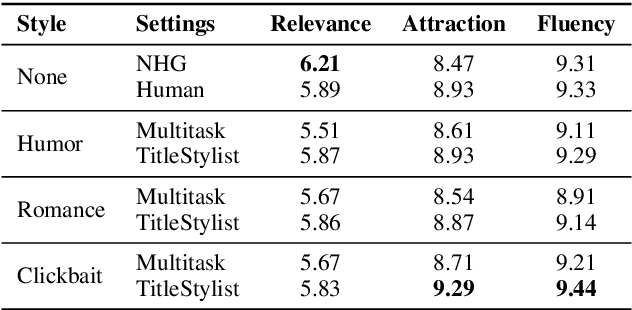
Current summarization systems only produce plain, factual headlines, but do not meet the practical needs of creating memorable titles to increase exposure. We propose a new task, Stylistic Headline Generation (SHG), to enrich the headlines with three style options (humor, romance and clickbait), in order to attract more readers. With no style-specific article-headline pair (only a standard headline summarization dataset and mono-style corpora), our method TitleStylist generates style-specific headlines by combining the summarization and reconstruction tasks into a multitasking framework. We also introduced a novel parameter sharing scheme to further disentangle the style from the text. Through both automatic and human evaluation, we demonstrate that TitleStylist can generate relevant, fluent headlines with three target styles: humor, romance, and clickbait. The attraction score of our model generated headlines surpasses that of the state-of-the-art summarization model by 9.68%, and even outperforms human-written references.
Unsupervised Domain Adaptation for Neural Machine Translation with Iterative Back Translation
Jan 22, 2020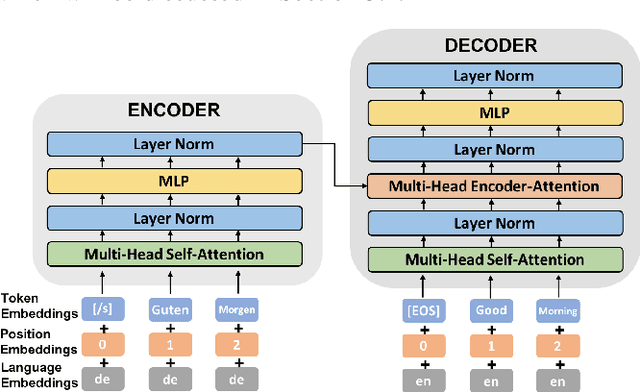
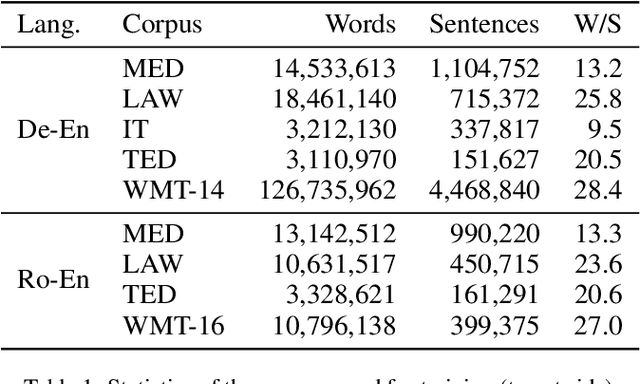
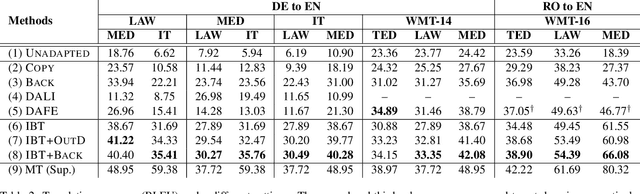
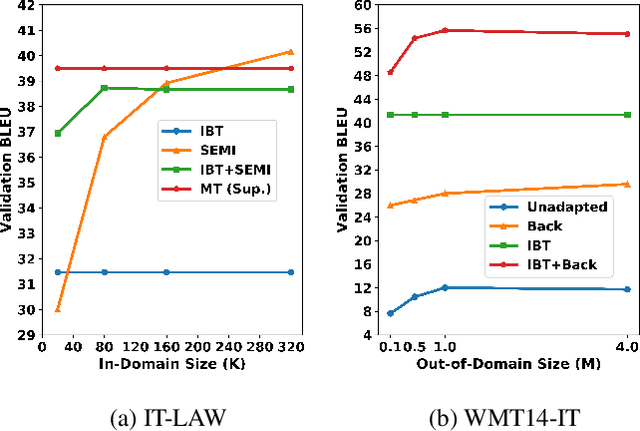
State-of-the-art neural machine translation (NMT) systems are data-hungry and perform poorly on domains with little supervised data. As data collection is expensive and infeasible in many cases, unsupervised domain adaptation methods are needed. We apply an Iterative Back Translation (IBT) training scheme on in-domain monolingual data, which repeatedly uses a Transformer-based NMT model to create in-domain pseudo-parallel sentence pairs in one translation direction on the fly and then use them to train the model in the other direction. Evaluated on three domains of German-to-English translation task with no supervised data, this simple technique alone (without any out-of-domain parallel data) can already surpass all previous domain adaptation methods---up to +9.48 BLEU over the strongest previous method, and up to +27.77 BLEU over the unadapted baseline. Moreover, given available supervised out-of-domain data on German-to-English and Romanian-to-English language pairs, we can further enhance the performance and obtain up to +19.31 BLEU improvement over the strongest baseline, and +47.69 BLEU increment against the unadapted model.
Representation Learning for Electronic Health Records
Sep 19, 2019Information in electronic health records (EHR), such as clinical narratives, examination reports, lab measurements, demographics, and other patient encounter entries, can be transformed into appropriate data representations that can be used for downstream clinical machine learning tasks using representation learning. Learning better representations is critical to improve the performance of downstream tasks. Due to the advances in machine learning, we now can learn better and meaningful representations from EHR through disentangling the underlying factors inside data and distilling large amounts of information and knowledge from heterogeneous EHR sources. In this chapter, we first introduce the background of learning representations and reasons why we need good EHR representations in machine learning for medicine and healthcare in Section 1. Next, we explain the commonly-used machine learning and evaluation methods for representation learning using a deep learning approach in Section 2. Following that, we review recent related studies of learning patient state representation from EHR for clinical machine learning tasks in Section 3. Finally, in Section 4 we discuss more techniques, studies, and challenges for learning natural language representations when free texts, such as clinical notes, examination reports, or biomedical literature are used. We also discuss challenges and opportunities in these rapidly growing research fields.
Is BERT Really Robust? A Strong Baseline for Natural Language Attack on Text Classification and Entailment
Sep 07, 2019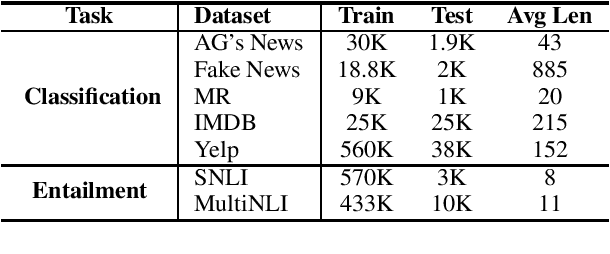
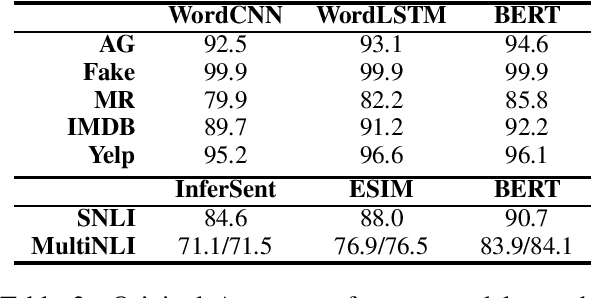

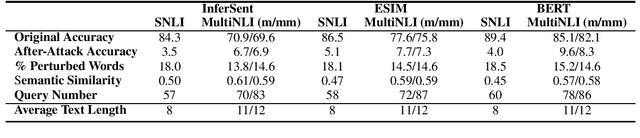
Machine learning algorithms are often vulnerable to adversarial examples that have imperceptible alterations from the original counterparts but can fool the state-of-the-art models. It is helpful to evaluate or even improve the robustness of these models by exposing the maliciously crafted adversarial examples. In this paper, we present TextFooler, a simple but strong baseline to generate natural adversarial text. By applying it to two fundamental natural language tasks, text classification and textual entailment, we successfully attacked three target models, including the powerful pre-trained BERT, and the widely used convolutional and recurrent neural networks. We demonstrate the advantages of this framework in three ways: (1) effective---it outperforms state-of-the-art attacks in terms of success rate and perturbation rate, (2) utility-preserving---it preserves semantic content and grammaticality, and remains correctly classified by humans, and (3) efficient---it generates adversarial text with computational complexity linear to the text length.
REflex: Flexible Framework for Relation Extraction in Multiple Domains
Jul 20, 2019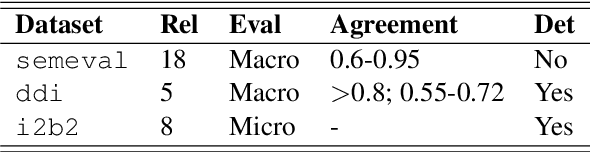

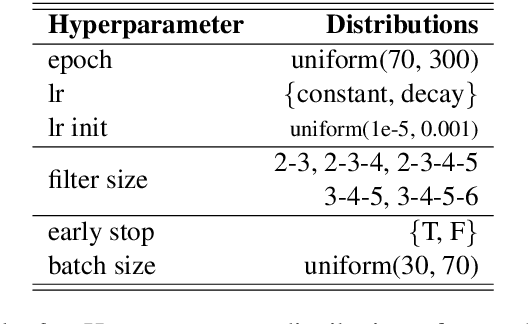
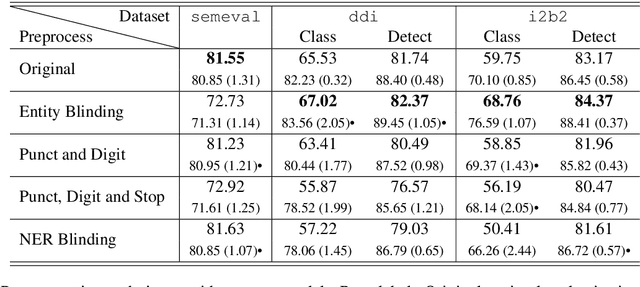
Systematic comparison of methods for relation extraction (RE) is difficult because many experiments in the field are not described precisely enough to be completely reproducible and many papers fail to report ablation studies that would highlight the relative contributions of their various combined techniques. In this work, we build a unifying framework for RE, applying this on three highly used datasets (from the general, biomedical and clinical domains) with the ability to be extendable to new datasets. By performing a systematic exploration of modeling, pre-processing and training methodologies, we find that choices of pre-processing are a large contributor performance and that omission of such information can further hinder fair comparison. Other insights from our exploration allow us to provide recommendations for future research in this area.