 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurning Video Models into Generalist Robot Policies
May 27, 2026Video generative models have emerged as a promising robotics backbone, capable of generating videos that depict the completion of complex tasks across embodiments and environments. Recent work proposes robot foundation models that jointly predict future observations and actions by finetuning video models with action-labeled data. In this paper, we test the limits of an alternative approach: leave the video planner as-is while training an embodiment-specific inverse dynamics model (IDM). This decoupling offers several natural benefits: the video planner remains embodiment-agnostic, different video models can be interchanged easily without re-training the IDM, and the IDM can be independently trained with readily available self-play data. We present a closed-loop, video-to-action policy that combines an action-free video world model with a carefully-designed IDM based on the robot embodiment Jacobian. We demonstrate that our IDM design is both data-efficient and scalable to high-dimensional action spaces. Our policy, which we coin the Video-to-Embodied Robot Action Model (VERA), achieves strong performance across simulated and real-world benchmarks, including zero-shot Panda arm manipulation and 16-DoF Allegro-hand dexterous cube re-orientation. The same video planner can be used across multiple embodiments by pairing it with different embodiment-specific IDMs. Our results show that decoupled video planning plus faithful video-to-action translation is a viable alternative route towards zero-shot, cross-embodiment, and generalizable robot control. More results are available on our project website: https://vera.csail.mit.edu.
Scaling View Synthesis Transformers
Feb 24, 2026Geometry-free view synthesis transformers have recently achieved state-of-the-art performance in Novel View Synthesis (NVS), outperforming traditional approaches that rely on explicit geometry modeling. Yet the factors governing their scaling with compute remain unclear. We present a systematic study of scaling laws for view synthesis transformers and derive design principles for training compute-optimal NVS models. Contrary to prior findings, we show that encoder-decoder architectures can be compute-optimal; we trace earlier negative results to suboptimal architectural choices and comparisons across unequal training compute budgets. Across several compute levels, we demonstrate that our encoder-decoder architecture, which we call the Scalable View Synthesis Model (SVSM), scales as effectively as decoder-only models, achieves a superior performance-compute Pareto frontier, and surpasses the previous state-of-the-art on real-world NVS benchmarks with substantially reduced training compute.
* Project page: https://www.evn.kim/research/svsm
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
A Comprehensive Evaluation of Multi-task Learning and Multi-task Pre-training on EHR Time-series Data
Jul 20, 2020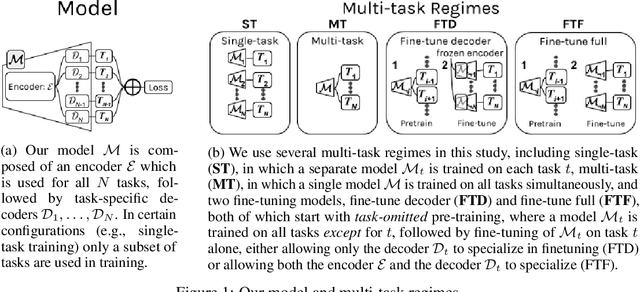
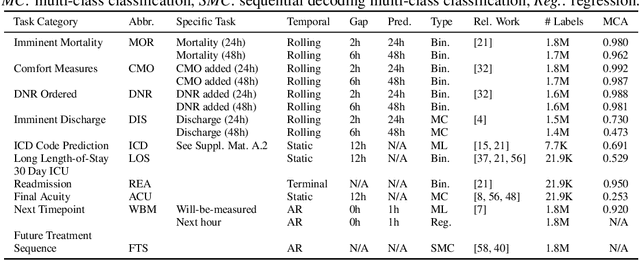
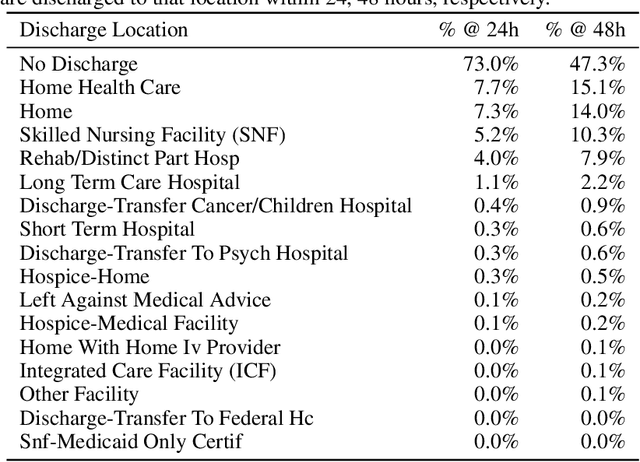
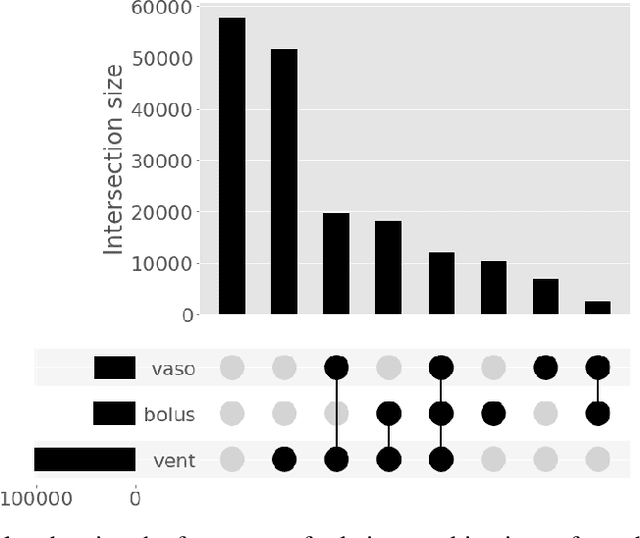
Multi-task learning (MTL) is a machine learning technique aiming to improve model performance by leveraging information across many tasks. It has been used extensively on various data modalities, including electronic health record (EHR) data. However, despite significant use on EHR data, there has been little systematic investigation of the utility of MTL across the diverse set of possible tasks and training schemes of interest in healthcare. In this work, we examine MTL across a battery of tasks on EHR time-series data. We find that while MTL does suffer from common negative transfer, we can realize significant gains via MTL pre-training combined with single-task fine-tuning. We demonstrate that these gains can be achieved in a task-independent manner and offer not only minor improvements under traditional learning, but also notable gains in a few-shot learning context, thereby suggesting this could be a scalable vehicle to offer improved performance in important healthcare contexts.