 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneral-Purpose Question-Answering with Macaw
Sep 06, 2021
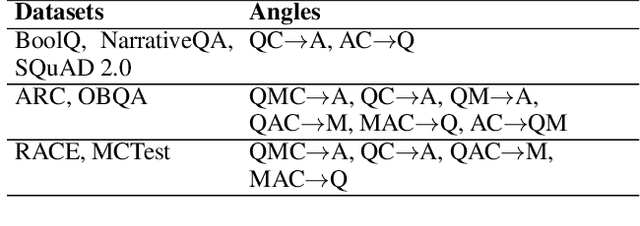

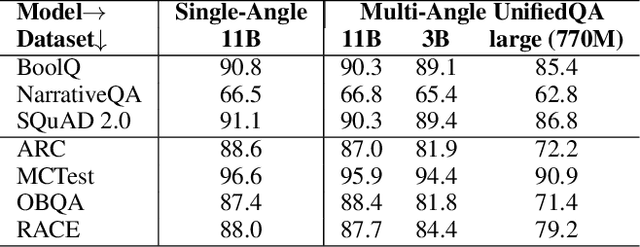
Despite the successes of pretrained language models, there are still few high-quality, general-purpose QA systems that are freely available. In response, we present Macaw, a versatile, generative question-answering (QA) system that we are making available to the community. Macaw is built on UnifiedQA, itself built on T5, and exhibits strong performance, zero-shot, on a wide variety of topics, including outperforming GPT-3 by over 10% (absolute) on Challenge300, a suite of 300 challenge questions, despite being an order of magnitude smaller (11 billion vs. 175 billion parameters). In addition, Macaw allows different permutations ("angles") of its inputs and outputs to be used, for example Macaw can take a question and produce an answer; or take an answer and produce a question; or take an answer and question, and produce multiple-choice options. We describe the system, and illustrate a variety of question types where it produces surprisingly good answers, well outside the training setup. We also identify question classes where it still appears to struggle, offering insights into the limitations of pretrained language models. Macaw is freely available, and we hope that it proves useful to the community. Macaw is available at https://github.com/allenai/macaw
Improving Neural Model Performance through Natural Language Feedback on Their Explanations
Apr 18, 2021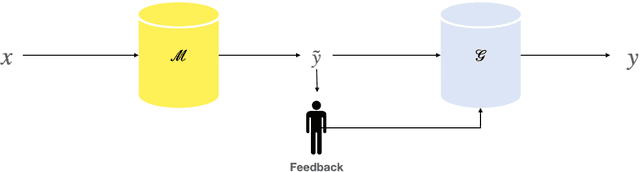
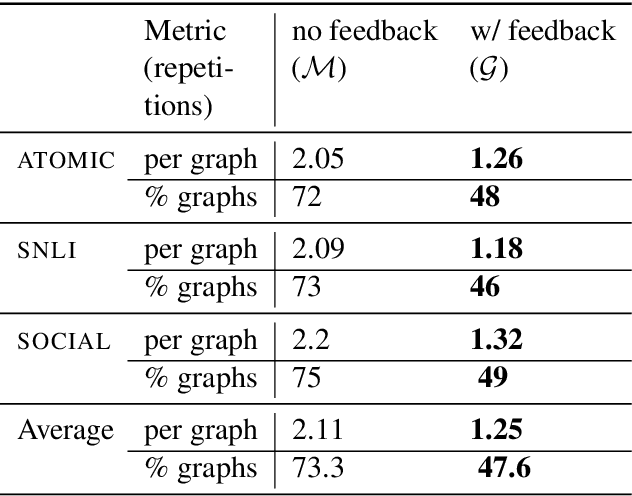
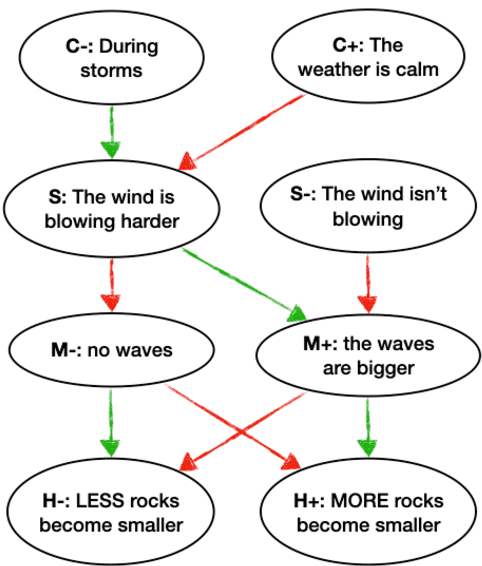
A class of explainable NLP models for reasoning tasks support their decisions by generating free-form or structured explanations, but what happens when these supporting structures contain errors? Our goal is to allow users to interactively correct explanation structures through natural language feedback. We introduce MERCURIE - an interactive system that refines its explanations for a given reasoning task by getting human feedback in natural language. Our approach generates graphs that have 40% fewer inconsistencies as compared with the off-the-shelf system. Further, simply appending the corrected explanation structures to the output leads to a gain of 1.2 points on accuracy on defeasible reasoning across all three domains. We release a dataset of over 450k graphs for defeasible reasoning generated by our system at https://tinyurl.com/mercurie .
Explaining Answers with Entailment Trees
Apr 17, 2021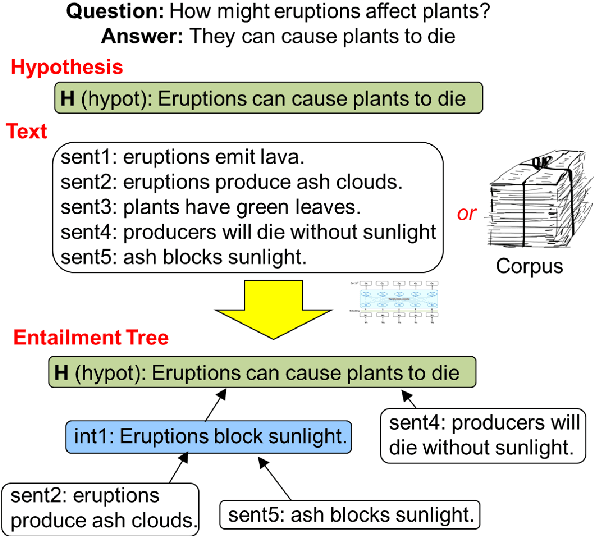

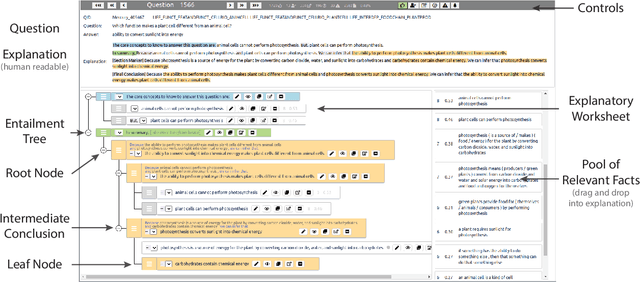

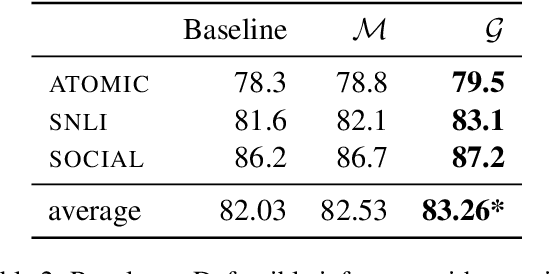
Our goal, in the context of open-domain textual question-answering (QA), is to explain answers by not just listing supporting textual evidence ("rationales"), but also showing how such evidence leads to the answer in a systematic way. If this could be done, new opportunities for understanding and debugging the system's reasoning would become possible. Our approach is to generate explanations in the form of entailment trees, namely a tree of entailment steps from facts that are known, through intermediate conclusions, to the final answer. To train a model with this skill, we created ENTAILMENTBANK, the first dataset to contain multistep entailment trees. At each node in the tree (typically) two or more facts compose together to produce a new conclusion. Given a hypothesis (question + answer), we define three increasingly difficult explanation tasks: generate a valid entailment tree given (a) all relevant sentences (the leaves of the gold entailment tree), (b) all relevant and some irrelevant sentences, or (c) a corpus. We show that a strong language model only partially solves these tasks, and identify several new directions to improve performance. This work is significant as it provides a new type of dataset (multistep entailments) and baselines, offering a new avenue for the community to generate richer, more systematic explanations.
Enriching a Model's Notion of Belief using a Persistent Memory
Apr 16, 2021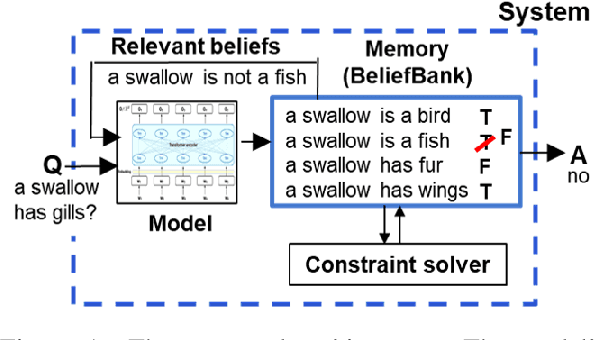

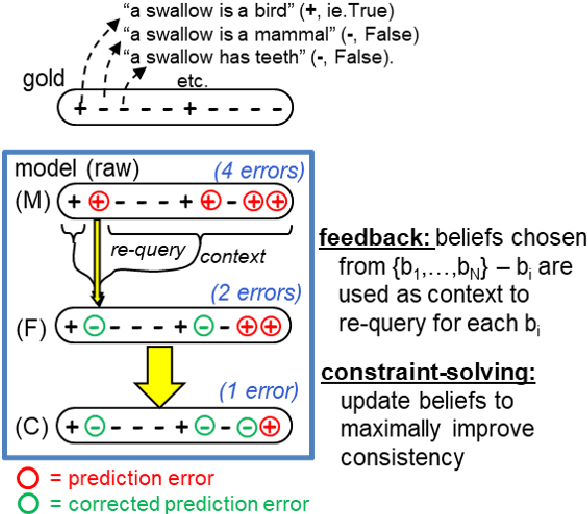
Although pretrained language models (PTLMs) have been shown to contain significant amounts of world knowledge, they can still produce inconsistent answers to questions when probed, even after using specialized training techniques to reduce inconsistency. As a result, it can be hard to identify what the model actually "believes" about the world. Our goal is to reduce this problem, so systems are more globally consistent and accurate in their answers. Our approach is to add a memory component - a BeliefBank - that records a model's answers, and two mechanisms that use it to improve consistency among beliefs. First, a reasoning component - a weighted SAT solver - improves consistency by flipping answers that significantly clash with others. Second, a feedback component re-queries the model but using known beliefs as context. We show that, in a controlled experimental setting, these two mechanisms improve both accuracy and consistency. This is significant as it is a first step towards endowing models with an evolving memory, allowing them to construct a more coherent picture of the world.
proScript: Partially Ordered Scripts Generation via Pre-trained Language Models
Apr 16, 2021
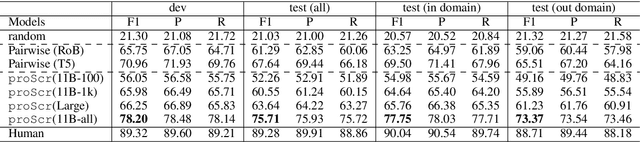
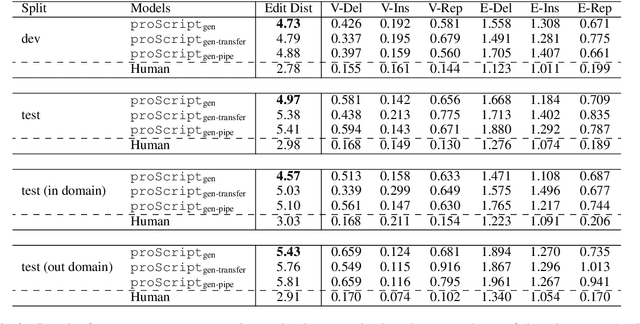
Scripts - standardized event sequences describing typical everyday activities - have been shown to help understand narratives by providing expectations, resolving ambiguity, and filling in unstated information. However, to date they have proved hard to author or extract from text. In this work, we demonstrate for the first time that pre-trained neural language models (LMs) can be be finetuned to generate high-quality scripts, at varying levels of granularity, for a wide range of everyday scenarios (e.g., bake a cake). To do this, we collected a large (6.4k), crowdsourced partially ordered scripts (named proScript), which is substantially larger than prior datasets, and developed models that generate scripts with combining language generation and structure prediction. We define two complementary tasks: (i) edge prediction: given a scenario and unordered events, organize the events into a valid (possibly partial-order) script, and (ii) script generation: given only a scenario, generate events and organize them into a (possibly partial-order) script. Our experiments show that our models perform well (e.g., F1=75.7 in task (i)), illustrating a new approach to overcoming previous barriers to script collection. We also show that there is still significant room for improvement toward human level performance. Together, our tasks, dataset, and models offer a new research direction for learning script knowledge.
CURIE: An Iterative Querying Approach for Reasoning About Situations
Apr 05, 2021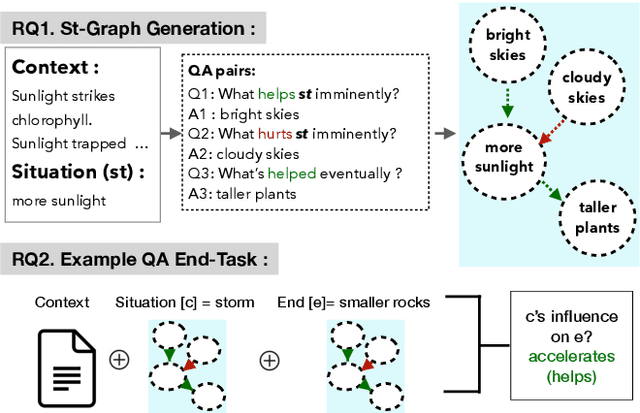
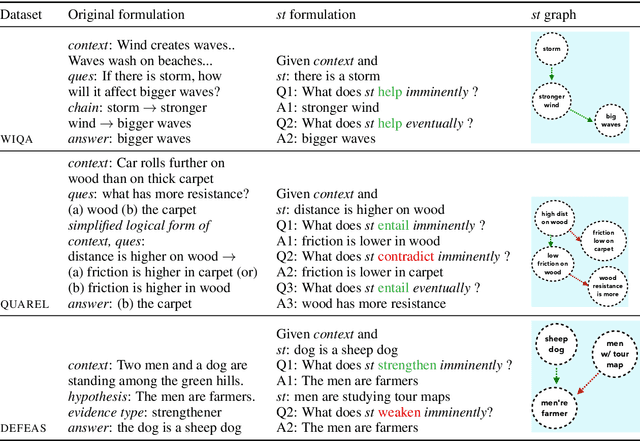
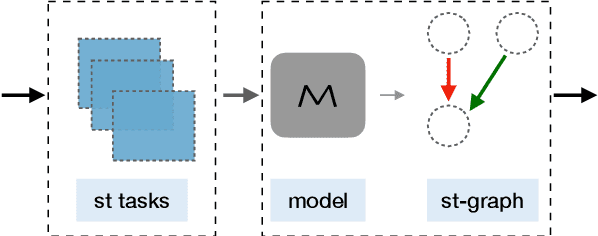
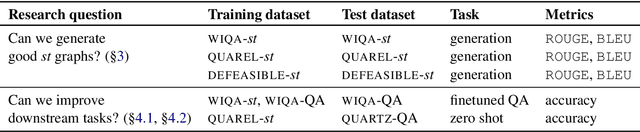
Recently, models have been shown to predict the effects of unexpected situations, e.g., would cloudy skies help or hinder plant growth? Given a context, the goal of such situational reasoning is to elicit the consequences of a new situation (st) that arises in that context. We propose a method to iteratively build a graph of relevant consequences explicitly in a structured situational graph (st-graph) using natural language queries over a finetuned language model (M). Across multiple domains, CURIE generates st-graphs that humans find relevant and meaningful in eliciting the consequences of a new situation. We show that st-graphs generated by CURIE improve a situational reasoning end task (WIQA-QA) by 3 points on accuracy by simply augmenting their input with our generated situational graphs, especially for a hard subset that requires background knowledge and multi-hop reasoning.
Think you have Solved Direct-Answer Question Answering? Try ARC-DA, the Direct-Answer AI2 Reasoning Challenge
Feb 05, 2021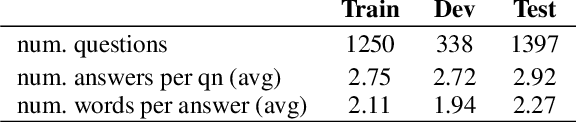
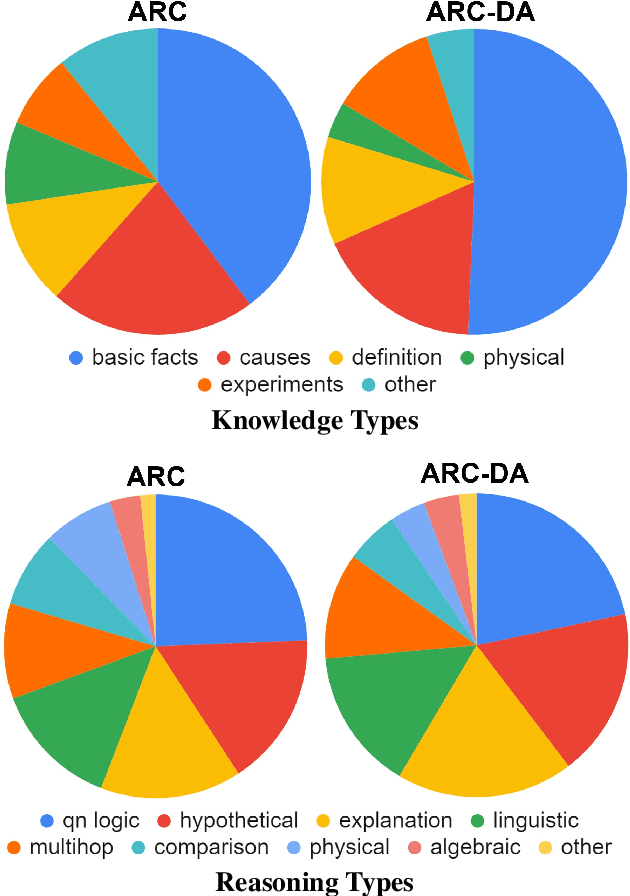
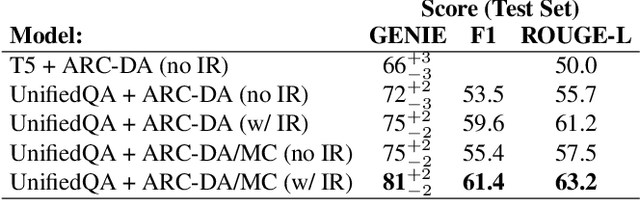
We present the ARC-DA dataset, a direct-answer ("open response", "freeform") version of the ARC (AI2 Reasoning Challenge) multiple-choice dataset. While ARC has been influential in the community, its multiple-choice format is unrepresentative of real-world questions, and multiple choice formats can be particularly susceptible to artifacts. The ARC-DA dataset addresses these concerns by converting questions to direct-answer format using a combination of crowdsourcing and expert review. The resulting dataset contains 2985 questions with a total of 8436 valid answers (questions typically have more than one valid answer). ARC-DA is one of the first DA datasets of natural questions that often require reasoning, and where appropriate question decompositions are not evident from the questions themselves. We describe the conversion approach taken, appropriate evaluation metrics, and several strong models. Although high, the best scores (81% GENIE, 61.4% F1, 63.2% ROUGE-L) still leave considerable room for improvement. In addition, the dataset provides a natural setting for new research on explanation, as many questions require reasoning to construct answers. We hope the dataset spurs further advances in complex question-answering by the community. ARC-DA is available at https://allenai.org/data/arc-da
ProofWriter: Generating Implications, Proofs, and Abductive Statements over Natural Language
Dec 24, 2020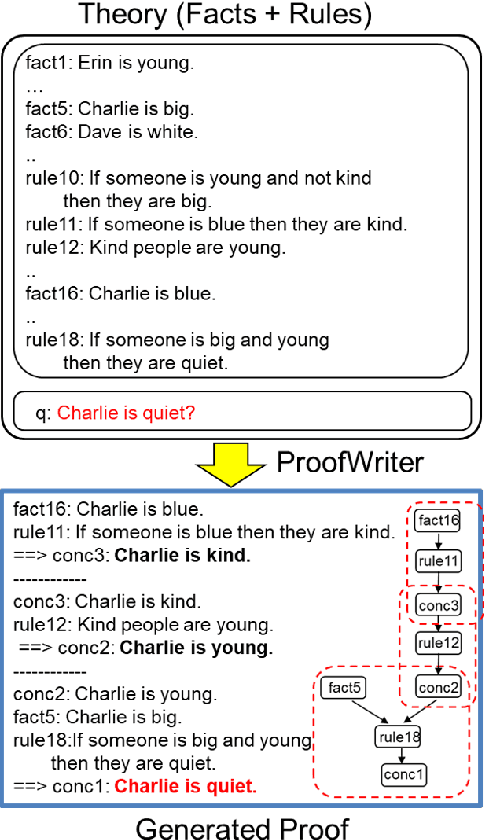

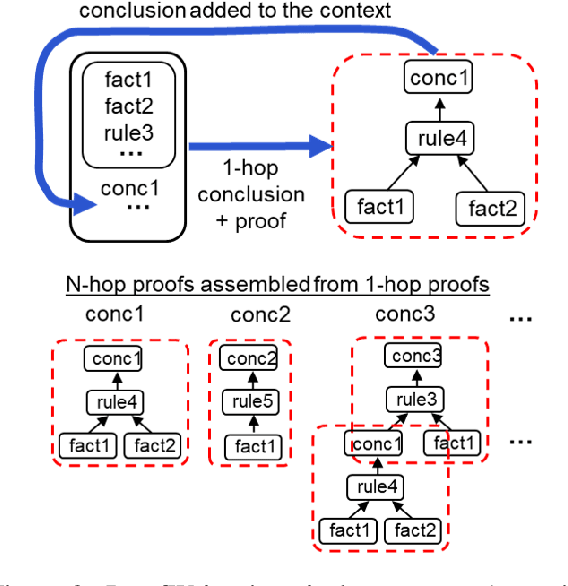
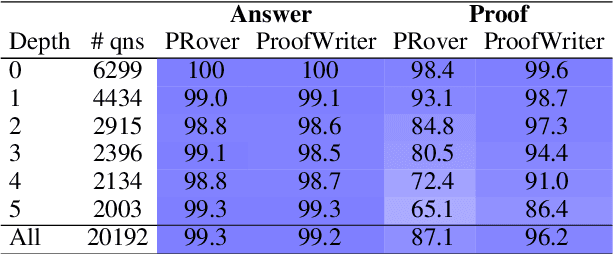
Transformers have been shown to emulate logical deduction over natural language theories (logical rules expressed in natural language), reliably assigning true/false labels to candidate implications. However, their ability to generate implications of a theory has not yet been demonstrated, and methods for reconstructing proofs of answers are imperfect. In this work we show that a generative model, called ProofWriter, can reliably generate both implications of a theory and the natural language proof(s) that support them. In particular, iterating a 1-step implication generator results in proofs that are highly reliable, and represent actual model decisions (rather than post-hoc rationalizations). On the RuleTaker dataset, the accuracy of ProofWriter's proofs exceed previous methods by +9% absolute, and in a way that generalizes to proof depths unseen in training and on out-of-domain problems. We also show that generative techniques can perform a type of abduction with high precision: Given a theory and an unprovable conclusion, identify a missing fact that allows the conclusion to be proved, along with a proof. These results significantly improve the viability of neural methods for systematically reasoning over natural language.
A Dataset for Tracking Entities in Open Domain Procedural Text
Oct 31, 2020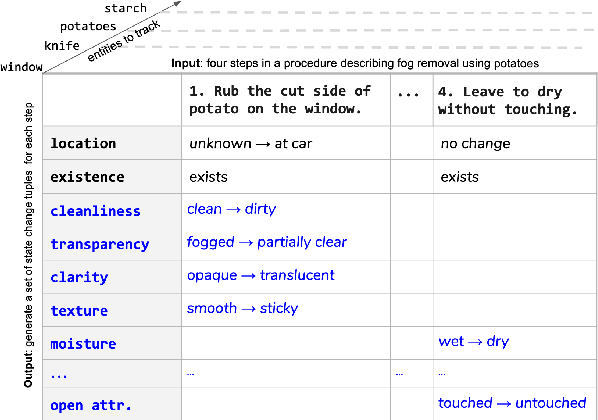
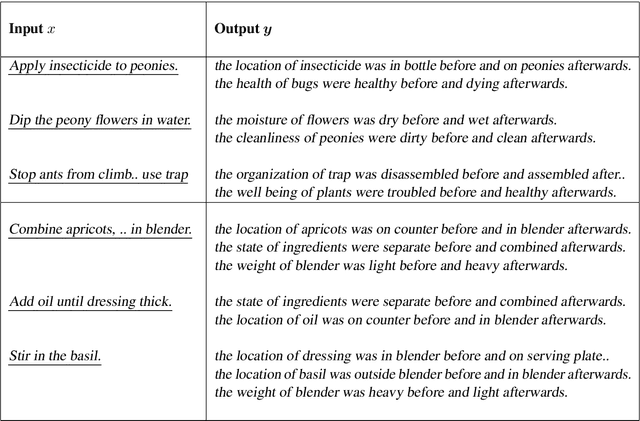
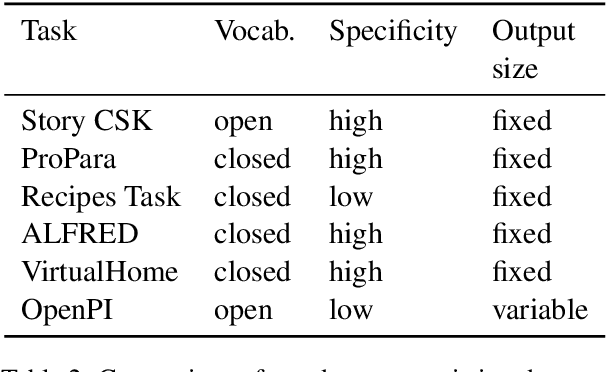

We present the first dataset for tracking state changes in procedural text from arbitrary domains by using an unrestricted (open) vocabulary. For example, in a text describing fog removal using potatoes, a car window may transition between being foggy, sticky,opaque, and clear. Previous formulations of this task provide the text and entities involved,and ask how those entities change for just a small, pre-defined set of attributes (e.g., location), limiting their fidelity. Our solution is a new task formulation where given just a procedural text as input, the task is to generate a set of state change tuples(entity, at-tribute, before-state, after-state)for each step,where the entity, attribute, and state values must be predicted from an open vocabulary. Using crowdsourcing, we create OPENPI1, a high-quality (91.5% coverage as judged by humans and completely vetted), and large-scale dataset comprising 29,928 state changes over 4,050 sentences from 810 procedural real-world paragraphs from WikiHow.com. A current state-of-the-art generation model on this task achieves 16.1% F1 based on BLEU metric, leaving enough room for novel model architectures.
Learning to Explain: Datasets and Models for Identifying Valid Reasoning Chains in Multihop Question-Answering
Oct 07, 2020Despite the rapid progress in multihop question-answering (QA), models still have trouble explaining why an answer is correct, with limited explanation training data available to learn from. To address this, we introduce three explanation datasets in which explanations formed from corpus facts are annotated. Our first dataset, eQASC, contains over 98K explanation annotations for the multihop question answering dataset QASC, and is the first that annotates multiple candidate explanations for each answer. The second dataset eQASC-perturbed is constructed by crowd-sourcing perturbations (while preserving their validity) of a subset of explanations in QASC, to test consistency and generalization of explanation prediction models. The third dataset eOBQA is constructed by adding explanation annotations to the OBQA dataset to test generalization of models trained on eQASC. We show that this data can be used to significantly improve explanation quality (+14% absolute F1 over a strong retrieval baseline) using a BERT-based classifier, but still behind the upper bound, offering a new challenge for future research. We also explore a delexicalized chain representation in which repeated noun phrases are replaced by variables, thus turning them into generalized reasoning chains (for example: "X is a Y" AND "Y has Z" IMPLIES "X has Z"). We find that generalized chains maintain performance while also being more robust to certain perturbations.