 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting Space Situational Awareness Events from News Text
Jan 15, 2022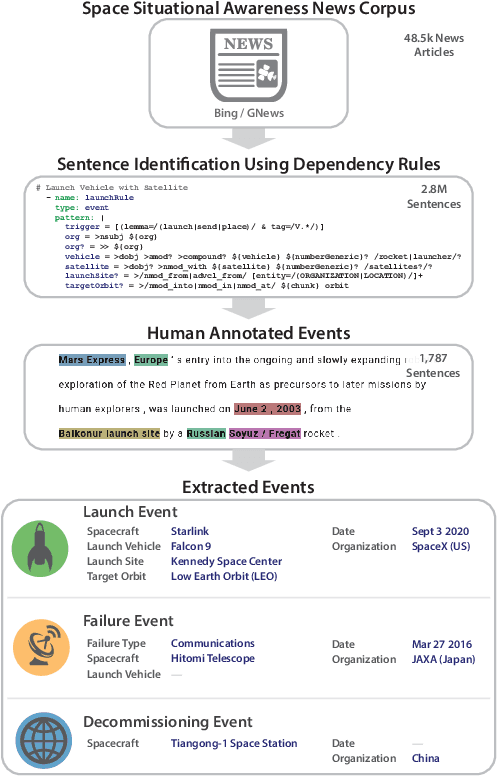
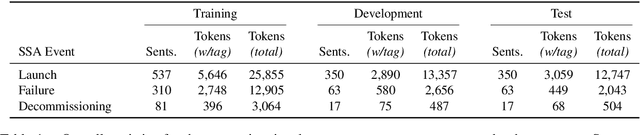

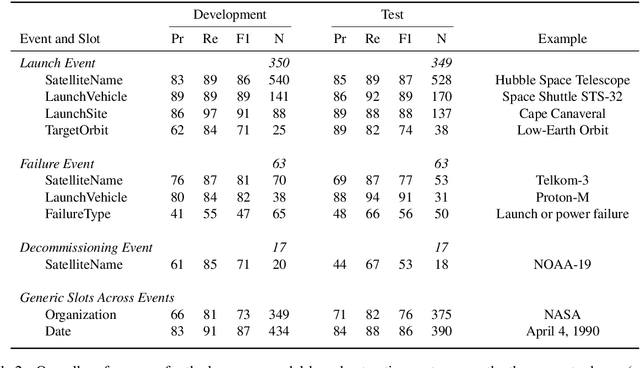
Space situational awareness typically makes use of physical measurements from radar, telescopes, and other assets to monitor satellites and other spacecraft for operational, navigational, and defense purposes. In this work we explore using textual input for the space situational awareness task. We construct a corpus of 48.5k news articles spanning all known active satellites between 2009 and 2020. Using a dependency-rule-based extraction system designed to target three high-impact events -- spacecraft launches, failures, and decommissionings, we identify 1,787 space-event sentences that are then annotated by humans with 15.9k labels for event slots. We empirically demonstrate a state-of-the-art neural extraction system achieves an overall F1 between 53 and 91 per slot for event extraction in this low-resource, high-impact domain.
Explaining Answers with Entailment Trees
Apr 17, 2021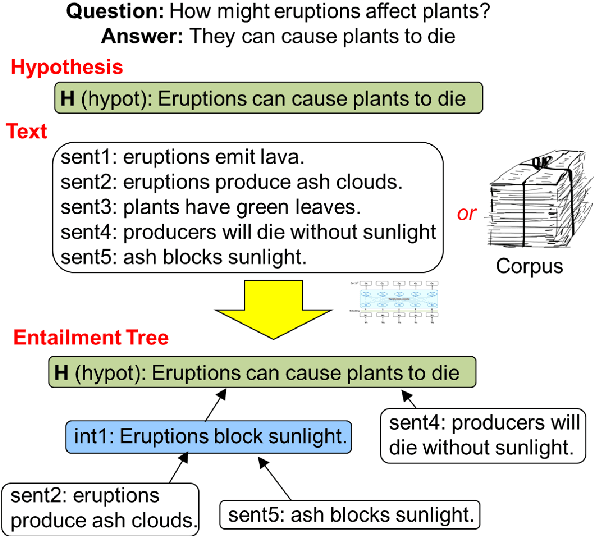

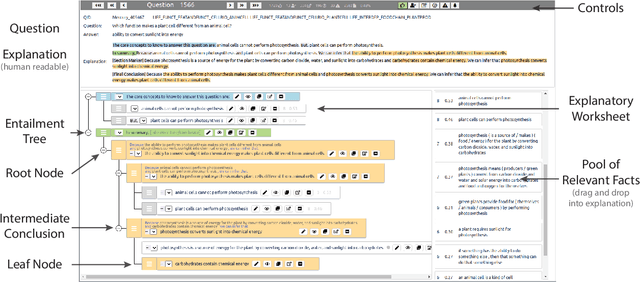

Our goal, in the context of open-domain textual question-answering (QA), is to explain answers by not just listing supporting textual evidence ("rationales"), but also showing how such evidence leads to the answer in a systematic way. If this could be done, new opportunities for understanding and debugging the system's reasoning would become possible. Our approach is to generate explanations in the form of entailment trees, namely a tree of entailment steps from facts that are known, through intermediate conclusions, to the final answer. To train a model with this skill, we created ENTAILMENTBANK, the first dataset to contain multistep entailment trees. At each node in the tree (typically) two or more facts compose together to produce a new conclusion. Given a hypothesis (question + answer), we define three increasingly difficult explanation tasks: generate a valid entailment tree given (a) all relevant sentences (the leaves of the gold entailment tree), (b) all relevant and some irrelevant sentences, or (c) a corpus. We show that a strong language model only partially solves these tasks, and identify several new directions to improve performance. This work is significant as it provides a new type of dataset (multistep entailments) and baselines, offering a new avenue for the community to generate richer, more systematic explanations.
Multi-class Hierarchical Question Classification for Multiple Choice Science Exams
Aug 15, 2019
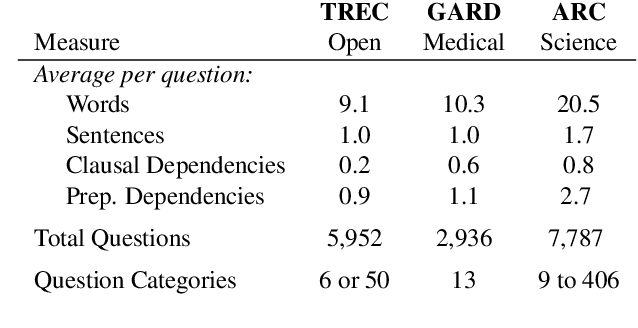

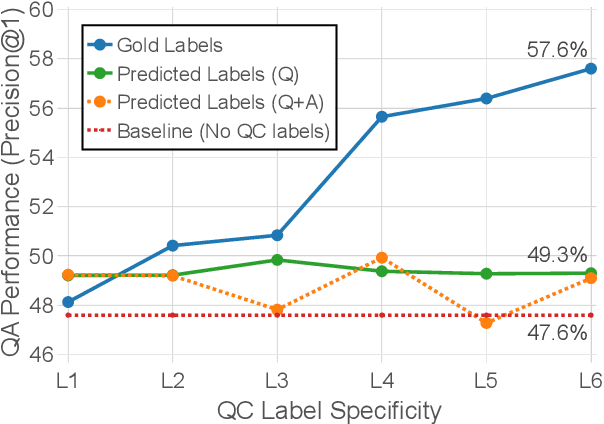
Prior work has demonstrated that question classification (QC), recognizing the problem domain of a question, can help answer it more accurately. However, developing strong QC algorithms has been hindered by the limited size and complexity of annotated data available. To address this, we present the largest challenge dataset for QC, containing 7,787 science exam questions paired with detailed classification labels from a fine-grained hierarchical taxonomy of 406 problem domains. We then show that a BERT-based model trained on this dataset achieves a large (+0.12 MAP) gain compared with previous methods, while also achieving state-of-the-art performance on benchmark open-domain and biomedical QC datasets. Finally, we show that using this model's predictions of question topic significantly improves the accuracy of a question answering system by +1.7% P@1, with substantial future gains possible as QC performance improves.