 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Edinburgh International Accents of English Corpus: Towards the Democratization of English ASR
Mar 31, 2023English is the most widely spoken language in the world, used daily by millions of people as a first or second language in many different contexts. As a result, there are many varieties of English. Although the great many advances in English automatic speech recognition (ASR) over the past decades, results are usually reported based on test datasets which fail to represent the diversity of English as spoken today around the globe. We present the first release of The Edinburgh International Accents of English Corpus (EdAcc). This dataset attempts to better represent the wide diversity of English, encompassing almost 40 hours of dyadic video call conversations between friends. Unlike other datasets, EdAcc includes a wide range of first and second-language varieties of English and a linguistic background profile of each speaker. Results on latest public, and commercial models show that EdAcc highlights shortcomings of current English ASR models. The best performing model, trained on 680 thousand hours of transcribed data, obtains an average of 19.7% word error rate (WER) -- in contrast to the 2.7% WER obtained when evaluated on US English clean read speech. Across all models, we observe a drop in performance on Indian, Jamaican, and Nigerian English speakers. Recordings, linguistic backgrounds, data statement, and evaluation scripts are released on our website (https://groups.inf.ed.ac.uk/edacc/) under CC-BY-SA license.
Explanations for Automatic Speech Recognition
Feb 27, 2023We address quality assessment for neural network based ASR by providing explanations that help increase our understanding of the system and ultimately help build trust in the system. Compared to simple classification labels, explaining transcriptions is more challenging as judging their correctness is not straightforward and transcriptions as a variable-length sequence is not handled by existing interpretable machine learning models. We provide an explanation for an ASR transcription as a subset of audio frames that is both a minimal and sufficient cause of the transcription. To do this, we adapt existing explainable AI (XAI) techniques from image classification-Statistical Fault Localisation(SFL) and Causal. Additionally, we use an adapted version of Local Interpretable Model-Agnostic Explanations (LIME) for ASR as a baseline in our experiments. We evaluate the quality of the explanations generated by the proposed techniques over three different ASR ,Google API, the baseline model of Sphinx, Deepspeech and 100 audio samples from the Commonvoice dataset.
Transfer Learning for Olfactory Object Detection
Jan 24, 2023We investigate the effect of style and category similarity in multiple datasets used for object detection pretraining. We find that including an additional stage of object-detection pretraining can increase the detection performance considerably. While our experiments suggest that style similarities between pre-training and target datasets are less important than matching categories, further experiments are needed to verify this hypothesis.
* 6 pages, 4 figures
ODOR: The ICPR2022 ODeuropa Challenge on Olfactory Object Recognition
Jan 24, 2023The Odeuropa Challenge on Olfactory Object Recognition aims to foster the development of object detection in the visual arts and to promote an olfactory perspective on digital heritage. Object detection in historical artworks is particularly challenging due to varying styles and artistic periods. Moreover, the task is complicated due to the particularity and historical variance of predefined target objects, which exhibit a large intra-class variance, and the long tail distribution of the dataset labels, with some objects having only very few training examples. These challenges should encourage participants to create innovative approaches using domain adaptation or few-shot learning. We provide a dataset of 2647 artworks annotated with 20 120 tightly fit bounding boxes that are split into a training and validation set (public). A test set containing 1140 artworks and 15 480 annotations is kept private for the challenge evaluation.
* 6 pages, 6 figures
Evaluating and reducing the distance between synthetic and real speech distributions
Nov 29, 2022While modern Text-to-Speech (TTS) systems can produce speech rated highly in terms of subjective evaluation, the distance between real and synthetic speech distributions remains understudied, where we use the term \textit{distribution} to mean the sample space of all possible real speech recordings from a given set of speakers; or of the synthetic samples that could be generated for the same set of speakers. We evaluate the distance of real and synthetic speech distributions along the dimensions of the acoustic environment, speaker characteristics and prosody using a range of speech processing measures and the respective Wasserstein distances of their distributions. We reduce these distribution distances along said dimensions by providing utterance-level information derived from the measures to the model and show they can be generated at inference time. The improvements to the dimensions translate to overall distribution distance reduction approximated using Automatic Speech Recognition (ASR) by evaluating the fitness of the synthetic data as training data.
Multimodal Dyadic Impression Recognition via Listener Adaptive Cross-Domain Fusion
Nov 09, 2022As a sub-branch of affective computing, impression recognition, e.g., perception of speaker characteristics such as warmth or competence, is potentially a critical part of both human-human conversations and spoken dialogue systems. Most research has studied impressions only from the behaviors expressed by the speaker or the response from the listener, yet ignored their latent connection. In this paper, we perform impression recognition using a proposed listener adaptive cross-domain architecture, which consists of a listener adaptation function to model the causality between speaker and listener behaviors and a cross-domain fusion function to strengthen their connection. The experimental evaluation on the dyadic IMPRESSION dataset verified the efficacy of our method, producing concordance correlation coefficients of 78.8% and 77.5% in the competence and warmth dimensions, outperforming previous studies. The proposed method is expected to be generalized to similar dyadic interaction scenarios.
Exploration of A Self-Supervised Speech Model: A Study on Emotional Corpora
Oct 05, 2022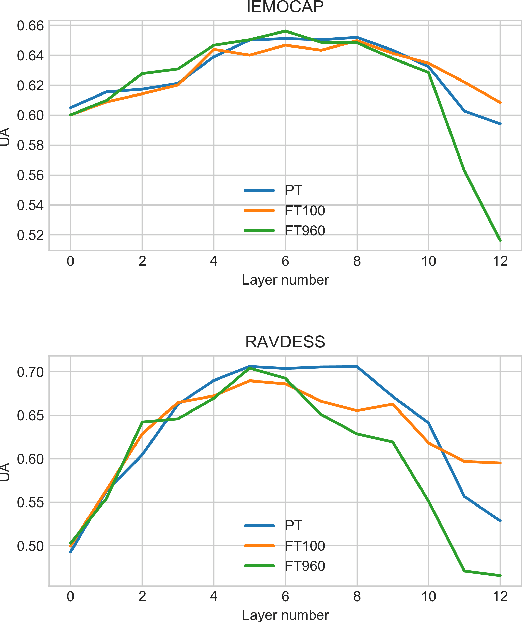
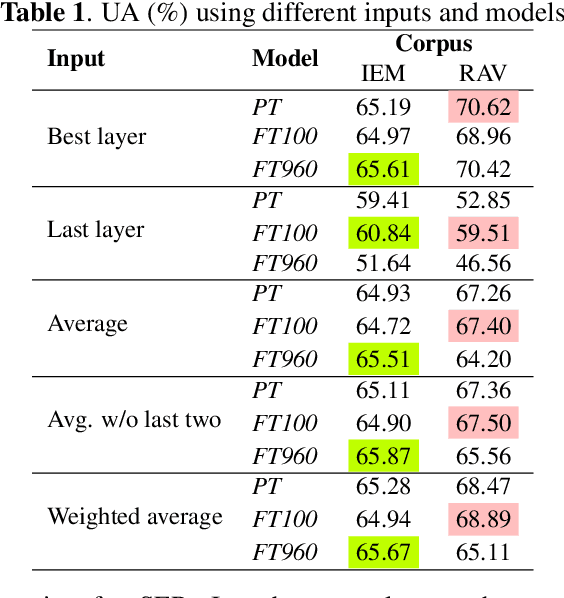
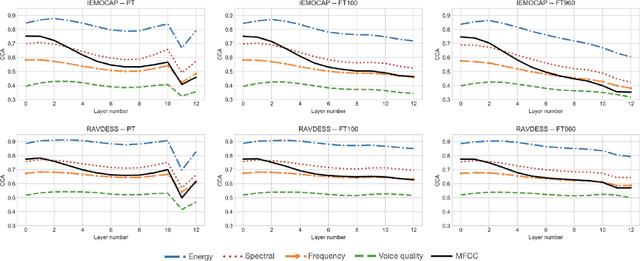

Self-supervised speech models have grown fast during the past few years and have proven feasible for use in various downstream tasks. Some recent work has started to look at the characteristics of these models, yet many concerns have not been fully addressed. In this work, we conduct a study on emotional corpora to explore a popular self-supervised model -- wav2vec 2.0. Via a set of quantitative analysis, we mainly demonstrate that: 1) wav2vec 2.0 appears to discard paralinguistic information that is less useful for word recognition purposes; 2) for emotion recognition, representations from the middle layer alone perform as well as those derived from layer averaging, while the final layer results in the worst performance in some cases; 3) current self-supervised models may not be the optimal solution for downstream tasks that make use of non-lexical features. Our work provides novel findings that will aid future research in this area and theoretical basis for the use of existing models.
ICC++: Explainable Image Retrieval for Art Historical Corpora using Image Composition Canvas
Jun 22, 2022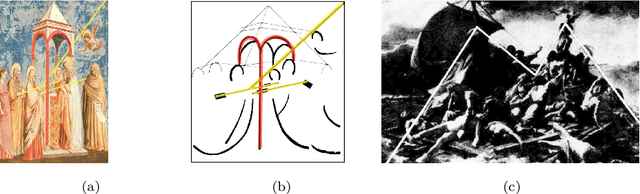
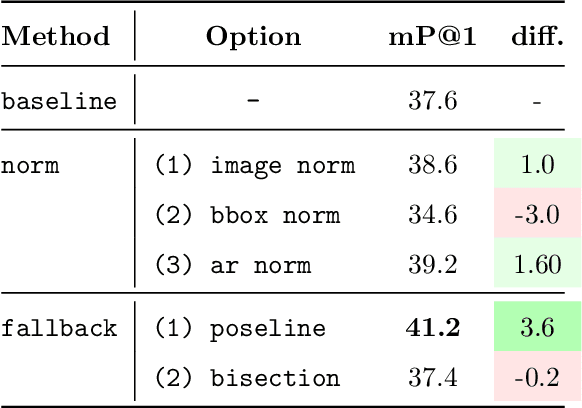
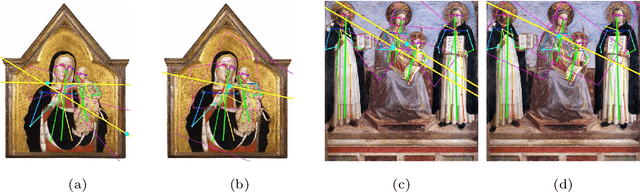
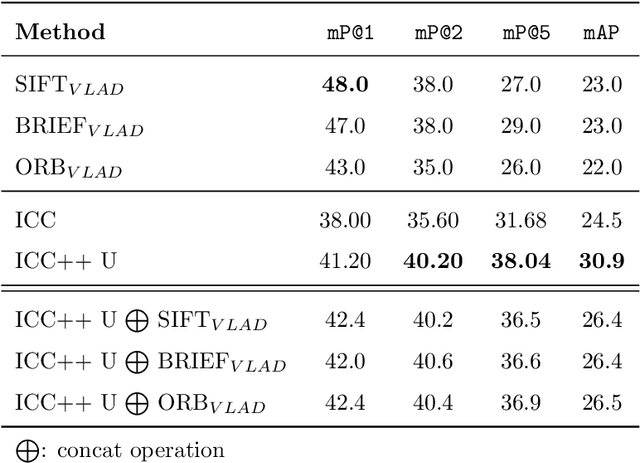
Image compositions are helpful in the study of image structures and assist in discovering the semantics of the underlying scene portrayed across art forms and styles. With the digitization of artworks in recent years, thousands of images of a particular scene or narrative could potentially be linked together. However, manually linking this data with consistent objectiveness can be a highly challenging and time-consuming task. In this work, we present a novel approach called Image Composition Canvas (ICC++) to compare and retrieve images having similar compositional elements. ICC++ is an improvement over ICC specializing in generating low and high-level features (compositional elements) motivated by Max Imdahl's work. To this end, we present a rigorous quantitative and qualitative comparison of our approach with traditional and state-of-the-art (SOTA) methods showing that our proposed method outperforms all of them. In combination with deep features, our method outperforms the best deep learning-based method, opening the research direction for explainable machine learning for digital humanities. We will release the code and the data post-publication.
Mask-combine Decoding and Classification Approach for Punctuation Prediction with real-time Inference Constraints
Dec 17, 2021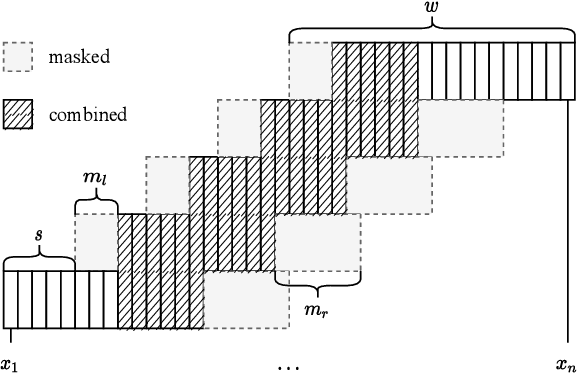
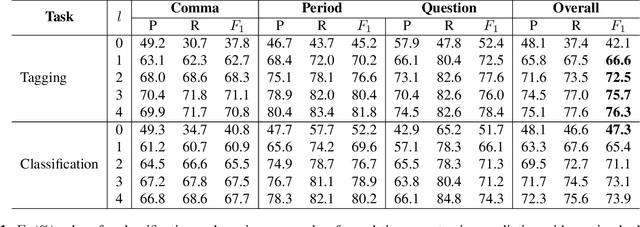
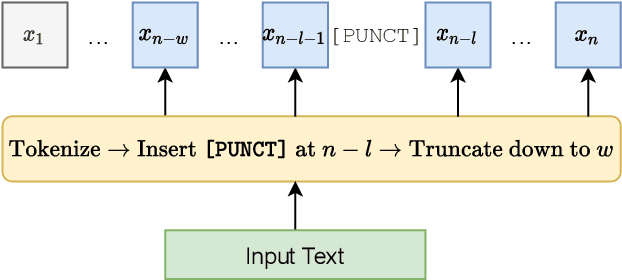
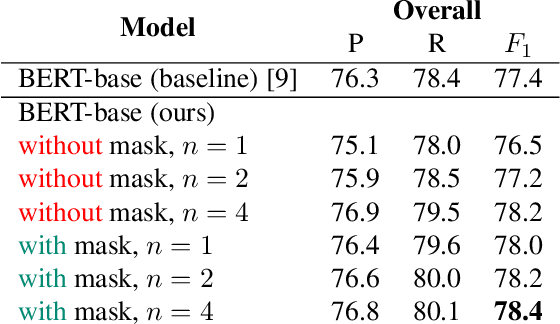
In this work, we unify several existing decoding strategies for punctuation prediction in one framework and introduce a novel strategy which utilises multiple predictions at each word across different windows. We show that significant improvements can be achieved by optimising these strategies after training a model, only leading to a potential increase in inference time, with no requirement for retraining. We further use our decoding strategy framework for the first comparison of tagging and classification approaches for punctuation prediction in a real-time setting. Our results show that a classification approach for punctuation prediction can be beneficial when little or no right-side context is available.
Deciphering Speech: a Zero-Resource Approach to Cross-Lingual Transfer in ASR
Nov 22, 2021



We present a method for cross-lingual training an ASR system using absolutely no transcribed training data from the target language, and with no phonetic knowledge of the language in question. Our approach uses a novel application of a decipherment algorithm, which operates given only unpaired speech and text data from the target language. We apply this decipherment to phone sequences generated by a universal phone recogniser trained on out-of-language speech corpora, which we follow with flat-start semi-supervised training to obtain an acoustic model for the new language. To the best of our knowledge, this is the first practical approach to zero-resource cross-lingual ASR which does not rely on any hand-crafted phonetic information. We carry out experiments on read speech from the GlobalPhone corpus, and show that it is possible to learn a decipherment model on just 20 minutes of data from the target language. When used to generate pseudo-labels for semi-supervised training, we obtain WERs that range from 25% to just 5% absolute worse than the equivalent fully supervised models trained on the same data.