 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-Free Acceleration for Document Parsing Vision-Language Model with Hierarchical Speculative Decoding
Feb 13, 2026Document parsing is a fundamental task in multimodal understanding, supporting a wide range of downstream applications such as information extraction and intelligent document analysis. Benefiting from strong semantic modeling and robust generalization, VLM-based end-to-end approaches have emerged as the mainstream paradigm in recent years. However, these models often suffer from substantial inference latency, as they must auto-regressively generate long token sequences when processing long-form documents. In this work, motivated by the extremely long outputs and complex layout structures commonly found in document parsing, we propose a training-free and highly efficient acceleration method. Inspired by speculative decoding, we employ a lightweight document parsing pipeline as a draft model to predict batches of future tokens, while the more accurate VLM verifies these draft predictions in parallel. Moreover, we further exploit the layout-structured nature of documents by partitioning each page into independent regions, enabling parallel decoding of each region using the same draft-verify strategy. The final predictions are then assembled according to the natural reading order. Experimental results demonstrate the effectiveness of our approach: on the general-purpose OmniDocBench, our method provides a 2.42x lossless acceleration for the dots.ocr model, and achieves up to 4.89x acceleration on long-document parsing tasks. We will release our code to facilitate reproducibility and future research.
Unsupervised Video Person Re-identification via Noise and Hard frame Aware Clustering
Jun 10, 2021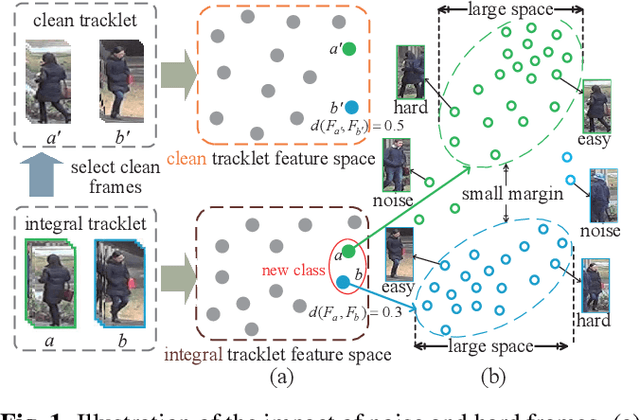
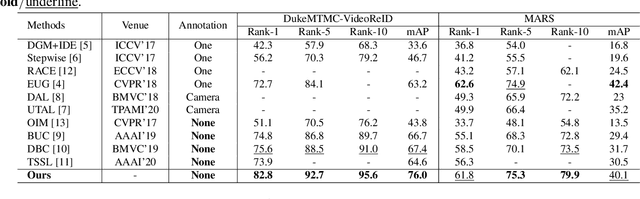
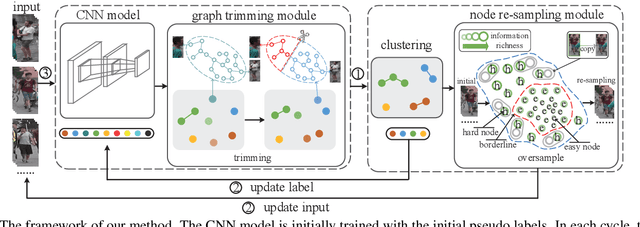
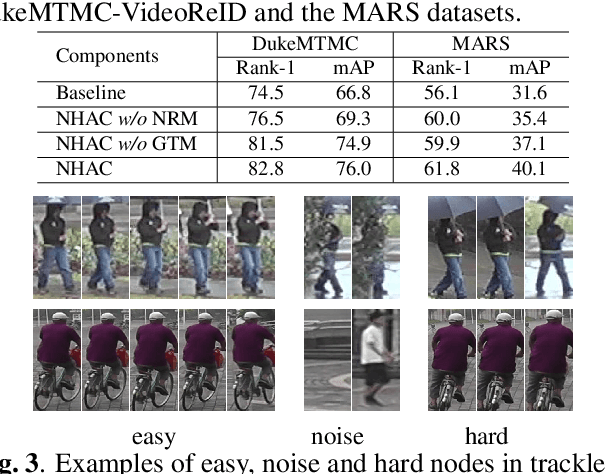
Unsupervised video-based person re-identification (re-ID) methods extract richer features from video tracklets than image-based ones. The state-of-the-art methods utilize clustering to obtain pseudo-labels and train the models iteratively. However, they underestimate the influence of two kinds of frames in the tracklet: 1) noise frames caused by detection errors or heavy occlusions exist in the tracklet, which may be allocated with unreliable labels during clustering; 2) the tracklet also contains hard frames caused by pose changes or partial occlusions, which are difficult to distinguish but informative. This paper proposes a Noise and Hard frame Aware Clustering (NHAC) method. NHAC consists of a graph trimming module and a node re-sampling module. The graph trimming module obtains stable graphs by removing noise frame nodes to improve the clustering accuracy. The node re-sampling module enhances the training of hard frame nodes to learn rich tracklet information. Experiments conducted on two video-based datasets demonstrate the effectiveness of the proposed NHAC under the unsupervised re-ID setting.