 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance of GPT-5 Frontier Models in Ophthalmology Question Answering
Aug 14, 2025



Large language models (LLMs) such as GPT-5 integrate advanced reasoning capabilities that may improve performance on complex medical question-answering tasks. For this latest generation of reasoning models, the configurations that maximize both accuracy and cost-efficiency have yet to be established. We evaluated 12 configurations of OpenAI's GPT-5 series (three model tiers across four reasoning effort settings) alongside o1-high, o3-high, and GPT-4o, using 260 closed-access multiple-choice questions from the American Academy of Ophthalmology Basic Clinical Science Course (BCSC) dataset. The primary outcome was multiple-choice accuracy; secondary outcomes included head-to-head ranking via a Bradley-Terry model, rationale quality assessment using a reference-anchored, pairwise LLM-as-a-judge framework, and analysis of accuracy-cost trade-offs using token-based cost estimates. GPT-5-high achieved the highest accuracy (0.965; 95% CI, 0.942-0.985), outperforming all GPT-5-nano variants (P < .001), o1-high (P = .04), and GPT-4o (P < .001), but not o3-high (0.958; 95% CI, 0.931-0.981). GPT-5-high ranked first in both accuracy (1.66x stronger than o3-high) and rationale quality (1.11x stronger than o3-high). Cost-accuracy analysis identified several GPT-5 configurations on the Pareto frontier, with GPT-5-mini-low offering the most favorable low-cost, high-performance balance. These results benchmark GPT-5 on a high-quality ophthalmology dataset, demonstrate the influence of reasoning effort on accuracy, and introduce an autograder framework for scalable evaluation of LLM-generated answers against reference standards in ophthalmology.
Enhancing Contrastive Learning for Retinal Imaging via Adjusted Augmentation Scales
Jan 05, 2025



Contrastive learning, a prominent approach within self-supervised learning, has demonstrated significant effectiveness in developing generalizable models for various applications involving natural images. However, recent research indicates that these successes do not necessarily extend to the medical imaging domain. In this paper, we investigate the reasons for this suboptimal performance and hypothesize that the dense distribution of medical images poses challenges to the pretext tasks in contrastive learning, particularly in constructing positive and negative pairs. We explore model performance under different augmentation strategies and compare the results to those achieved with strong augmentations. Our study includes six publicly available datasets covering multiple clinically relevant tasks. We further assess the model's generalizability through external evaluations. The model pre-trained with weak augmentation outperforms those with strong augmentation, improving AUROC from 0.838 to 0.848 and AUPR from 0.523 to 0.597 on MESSIDOR2, and showing similar enhancements across other datasets. Our findings suggest that optimizing the scale of augmentation is critical for enhancing the efficacy of contrastive learning in medical imaging.
Predicting optical coherence tomography-derived diabetic macular edema grades from fundus photographs using deep learning
Oct 18, 2018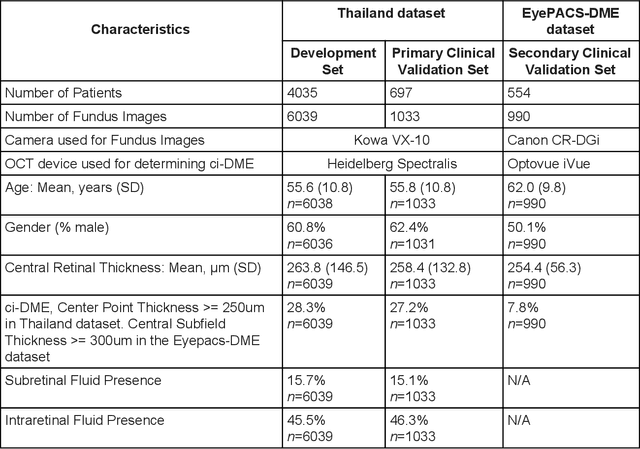
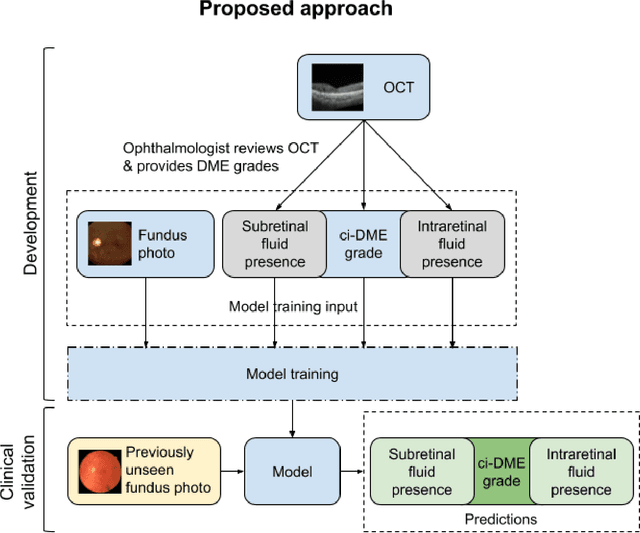
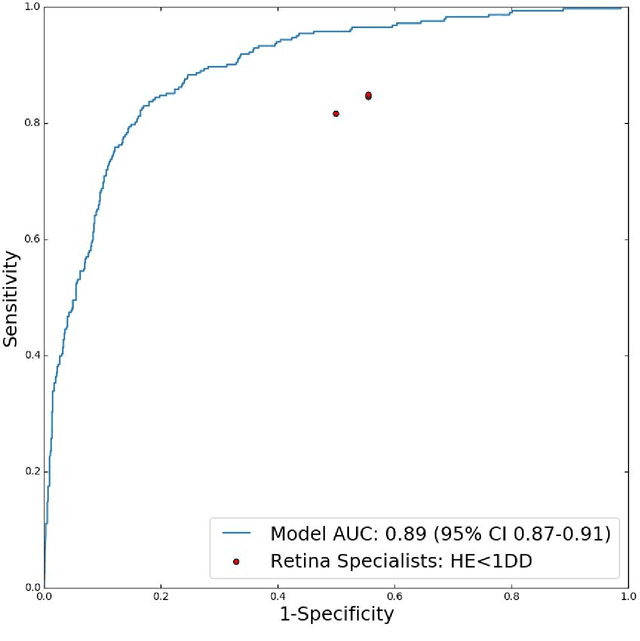
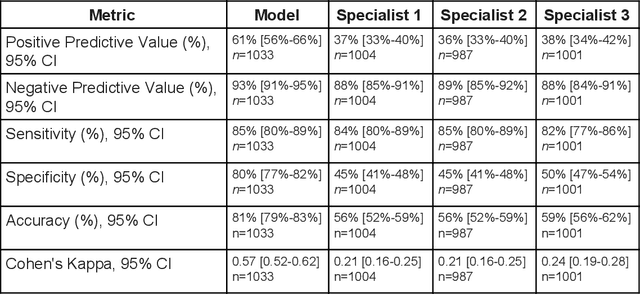
Diabetic eye disease is one of the fastest growing causes of preventable blindness. With the advent of anti-VEGF (vascular endothelial growth factor) therapies, it has become increasingly important to detect center-involved diabetic macular edema. However, center-involved diabetic macular edema is diagnosed using optical coherence tomography (OCT), which is not generally available at screening sites because of cost and workflow constraints. Instead, screening programs rely on the detection of hard exudates as a proxy for DME on color fundus photographs, often resulting in high false positive or false negative calls. To improve the accuracy of DME screening, we trained a deep learning model to use color fundus photographs to predict DME grades derived from OCT exams. Our "OCT-DME" model had an AUC of 0.89 (95% CI: 0.87-0.91), which corresponds to a sensitivity of 85% at a specificity of 80%. In comparison, three retinal specialists had similar sensitivities (82-85%), but only half the specificity (45-50%, p<0.001 for each comparison with model). The positive predictive value (PPV) of the OCT-DME model was 61% (95% CI: 56-66%), approximately double the 36-38% by the retina specialists. In addition, we used saliency and other techniques to examine how the model is making its prediction. The ability of deep learning algorithms to make clinically relevant predictions that generally require sophisticated 3D-imaging equipment from simple 2D images has broad relevance to many other applications in medical imaging.