 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoss Adapted Plasticity in Deep Neural Networks to Learn from Data with Unreliable Sources
Dec 06, 2022



When data is streaming from multiple sources, conventional training methods update model weights often assuming the same level of reliability for each source; that is: a model does not consider data quality of each source during training. In many applications, sources can have varied levels of noise or corruption that has negative effects on the learning of a robust deep learning model. A key issue is that the quality of data or labels for individual sources is often not available during training and could vary over time. Our solution to this problem is to consider the mistakes made while training on data originating from sources and utilise this to create a perceived data quality for each source. This paper demonstrates a straight-forward and novel technique that can be applied to any gradient descent optimiser: Update model weights as a function of the perceived reliability of data sources within a wider data set. The algorithm controls the plasticity of a given model to weight updates based on the history of losses from individual data sources. We show that applying this technique can significantly improve model performance when trained on a mixture of reliable and unreliable data sources, and maintain performance when models are trained on data sources that are all considered reliable. All code to reproduce this work's experiments and implement the algorithm in the reader's own models is made available.
Using Entropy Measures for Monitoring the Evolution of Activity Patterns
Oct 05, 2022
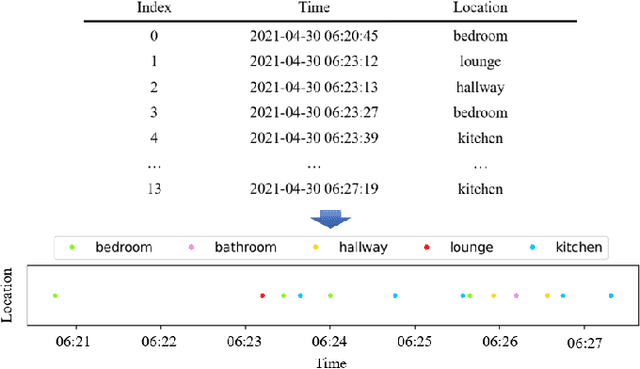
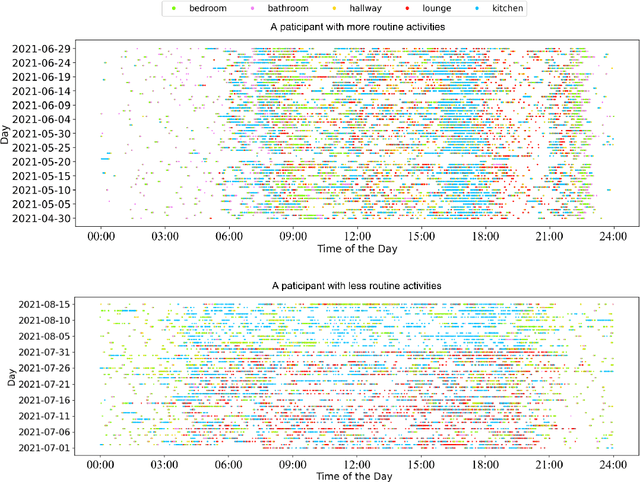
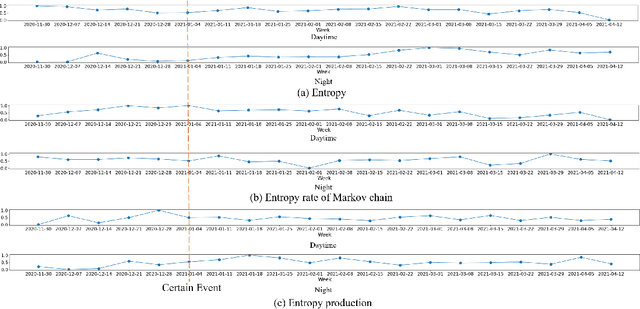
In this work, we apply information theory inspired methods to quantify changes in daily activity patterns. We use in-home movement monitoring data and show how they can help indicate the occurrence of healthcare-related events. Three different types of entropy measures namely Shannon's entropy, entropy rates for Markov chains, and entropy production rate have been utilised. The measures are evaluated on a large-scale in-home monitoring dataset that has been collected within our dementia care clinical study. The study uses Internet of Things (IoT) enabled solutions for continuous monitoring of in-home activity, sleep, and physiology to develop care and early intervention solutions to support people living with dementia (PLWD) in their own homes. Our main goal is to show the applicability of the entropy measures to time-series activity data analysis and to use the extracted measures as new engineered features that can be fed into inference and analysis models. The results of our experiments show that in most cases the combination of these measures can indicate the occurrence of healthcare-related events. We also find that different participants with the same events may have different measures based on one entropy measure. So using a combination of these measures in an inference model will be more effective than any of the single measures.
Designing A Clinically Applicable Deep Recurrent Model to Identify Neuropsychiatric Symptoms in People Living with Dementia Using In-Home Monitoring Data
Oct 19, 2021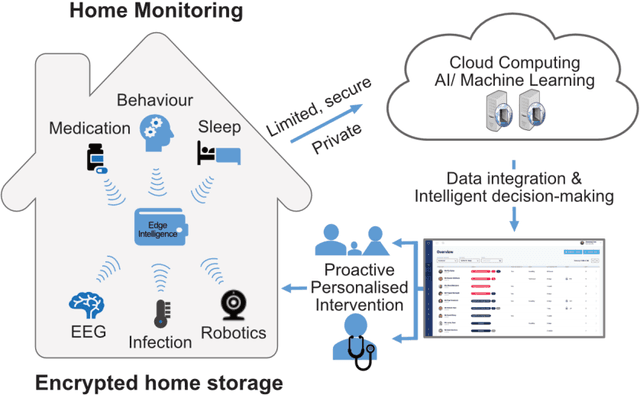
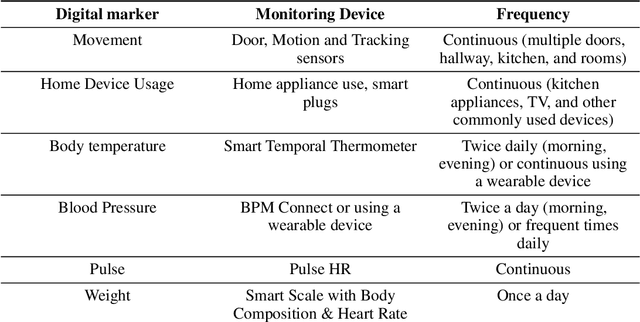

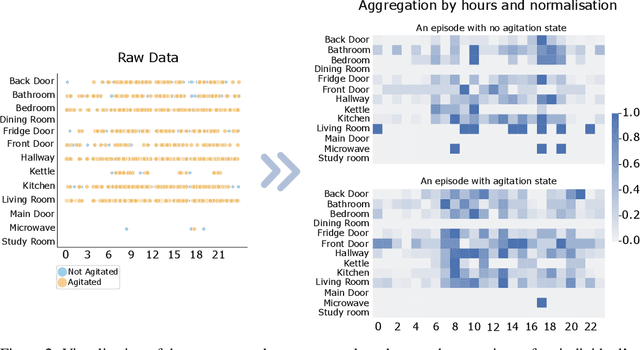
Agitation is one of the neuropsychiatric symptoms with high prevalence in dementia which can negatively impact the Activities of Daily Living (ADL) and the independence of individuals. Detecting agitation episodes can assist in providing People Living with Dementia (PLWD) with early and timely interventions. Analysing agitation episodes will also help identify modifiable factors such as ambient temperature and sleep as possible components causing agitation in an individual. This preliminary study presents a supervised learning model to analyse the risk of agitation in PLWD using in-home monitoring data. The in-home monitoring data includes motion sensors, physiological measurements, and the use of kitchen appliances from 46 homes of PLWD between April 2019-June 2021. We apply a recurrent deep learning model to identify agitation episodes validated and recorded by a clinical monitoring team. We present the experiments to assess the efficacy of the proposed model. The proposed model achieves an average of 79.78% recall, 27.66% precision and 37.64% F1 scores when employing the optimal parameters, suggesting a good ability to recognise agitation events. We also discuss using machine learning models for analysing the behavioural patterns using continuous monitoring data and explore clinical applicability and the choices between sensitivity and specificity in-home monitoring applications.
Multimodal Federated Learning
Sep 10, 2021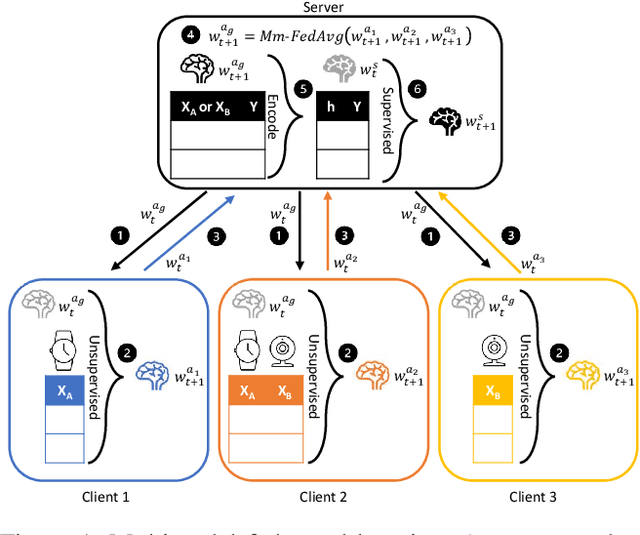
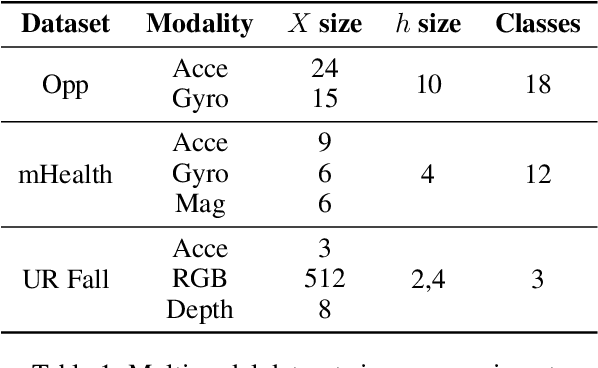
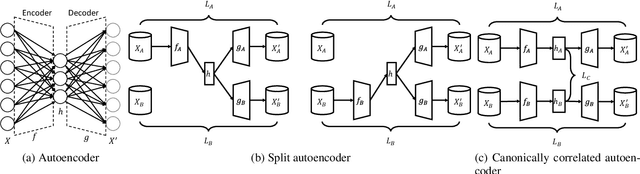
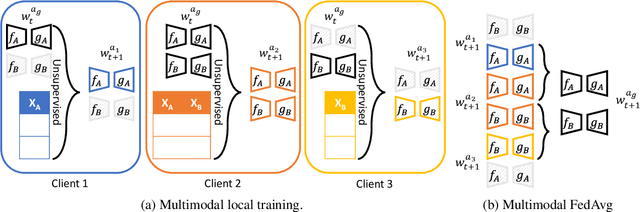
Federated learning is proposed as an alternative to centralized machine learning since its client-server structure provides better privacy protection and scalability in real-world applications. In many applications, such as smart homes with IoT devices, local data on clients are generated from different modalities such as sensory, visual, and audio data. Existing federated learning systems only work on local data from a single modality, which limits the scalability of the systems. In this paper, we propose a multimodal and semi-supervised federated learning framework that trains autoencoders to extract shared or correlated representations from different local data modalities on clients. In addition, we propose a multimodal FedAvg algorithm to aggregate local autoencoders trained on different data modalities. We use the learned global autoencoder for a downstream classification task with the help of auxiliary labelled data on the server. We empirically evaluate our framework on different modalities including sensory data, depth camera videos, and RGB camera videos. Our experimental results demonstrate that introducing data from multiple modalities into federated learning can improve its accuracy. In addition, we can use labelled data from only one modality for supervised learning on the server and apply the learned model to testing data from other modalities to achieve decent accuracy (e.g., approximately 70% as the best performance), especially when combining contributions from both unimodal clients and multimodal clients.
Semi-supervised Learning for Identifying the Likelihood of Agitation in People with Dementia
May 14, 2021
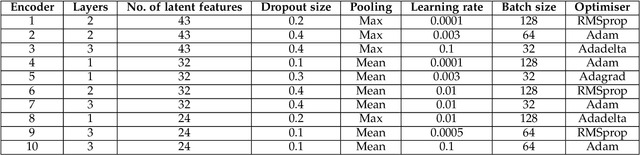
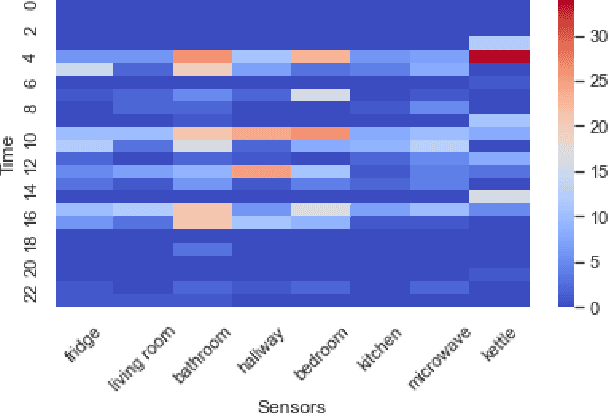
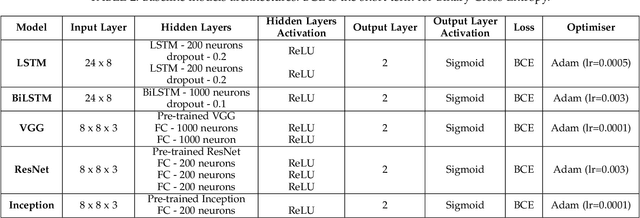
Interpreting the environmental, behavioural and psychological data from in-home sensory observations and measurements can provide valuable insights into the health and well-being of individuals. Presents of neuropsychiatric and psychological symptoms in people with dementia have a significant impact on their well-being and disease prognosis. Agitation in people with dementia can be due to many reasons such as pain or discomfort, medical reasons such as side effects of a medicine, communication problems and environment. This paper discusses a model for analysing the risk of agitation in people with dementia and how in-home monitoring data can support them. We proposed a semi-supervised model which combines a self-supervised learning model and a Bayesian ensemble classification. We train and test the proposed model on a dataset from a clinical study. The dataset was collected from sensors deployed in 96 homes of patients with dementia. The proposed model outperforms the state-of-the-art models in recall and f1-score values by 20%. The model also indicates better generalisability compared to the baseline models.
An Intelligent Bed Sensor System for Non-Contact Respiratory Rate Monitoring
Mar 25, 2021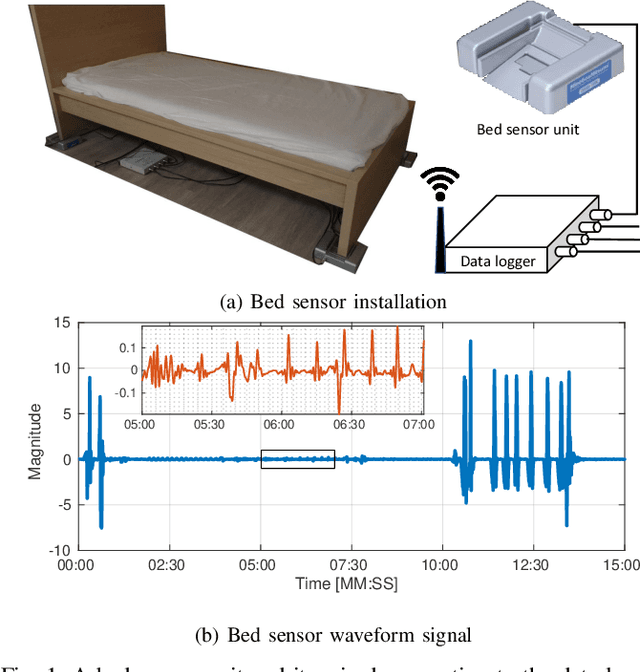
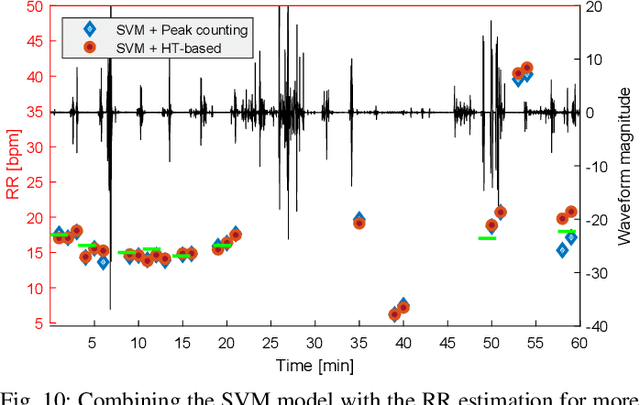
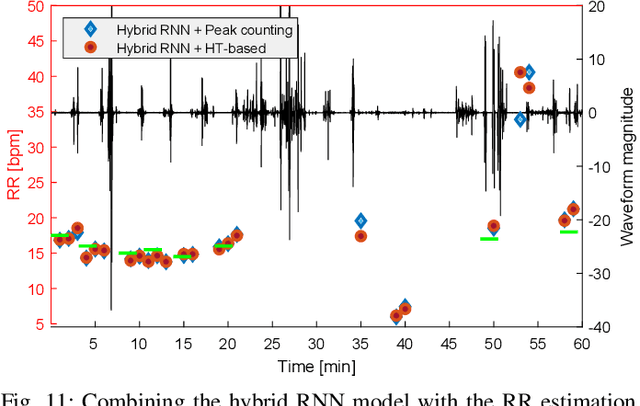
We present an IoT-based intelligent bed sensor system that collects and analyses respiration-associated signals for unobtrusive monitoring in the home, hospitals and care units. A contactless device is used, which contains four load sensors mounted under the bed and one data processing unit (data logger). Various machine learning methods are applied to the data streamed from the data logger to detect the Respiratory Rate (RR). We have implemented Support Vector Machine (SVM) and also Neural Network (NN)-based pattern recognition methods, which are combined with either peak detection or Hilbert transform for robust RR calculation. Experimental results show that our methods could effectively extract RR using the data collected by contactless bed sensors. The proposed methods are robust to outliers and noise, which are caused by body movements. The monitoring system provides a flexible and scalable way for continuous and remote monitoring of sleep, movement and weight using the embedded sensors.
A Hamiltonian Monte Carlo Model for Imputation and Augmentation of Healthcare Data
Mar 03, 2021
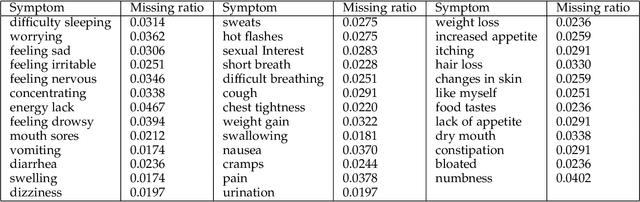
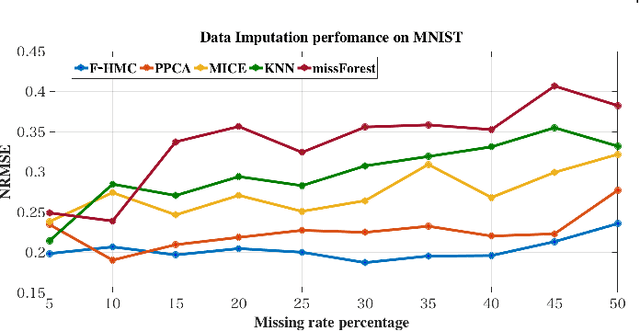
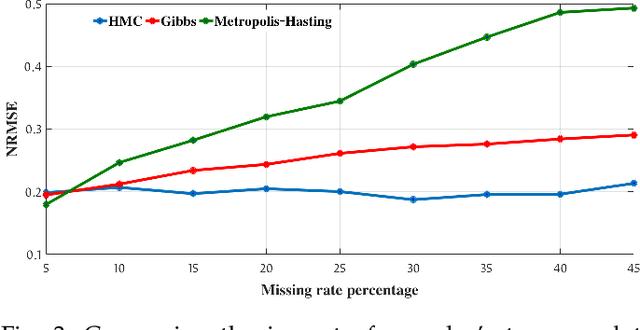
Missing values exist in nearly all clinical studies because data for a variable or question are not collected or not available. Inadequate handling of missing values can lead to biased results and loss of statistical power in analysis. Existing models usually do not consider privacy concerns or do not utilise the inherent correlations across multiple features to impute the missing values. In healthcare applications, we are usually confronted with high dimensional and sometimes small sample size datasets that need more effective augmentation or imputation techniques. Besides, imputation and augmentation processes are traditionally conducted individually. However, imputing missing values and augmenting data can significantly improve generalisation and avoid bias in machine learning models. A Bayesian approach to impute missing values and creating augmented samples in high dimensional healthcare data is proposed in this work. We propose folded Hamiltonian Monte Carlo (F-HMC) with Bayesian inference as a more practical approach to process the cross-dimensional relations by applying a random walk and Hamiltonian dynamics to adapt posterior distribution and generate large-scale samples. The proposed method is applied to a cancer symptom assessment dataset and confirmed to enrich the quality of data in precision, accuracy, recall, F1 score, and propensity metric.
An attention model to analyse the risk of agitation and urinary tract infections in people with dementia
Jan 18, 2021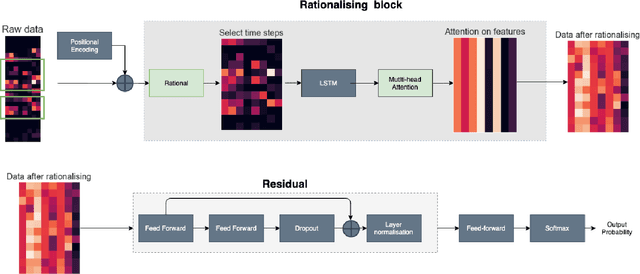
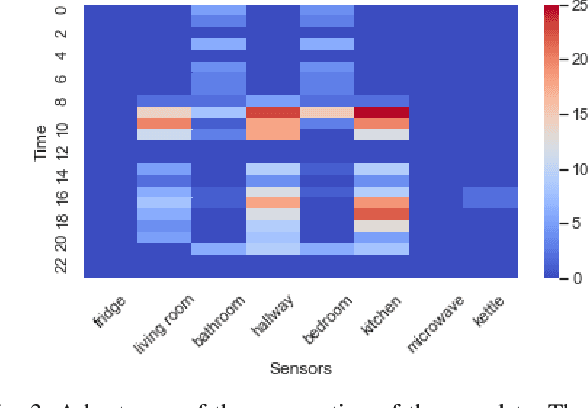
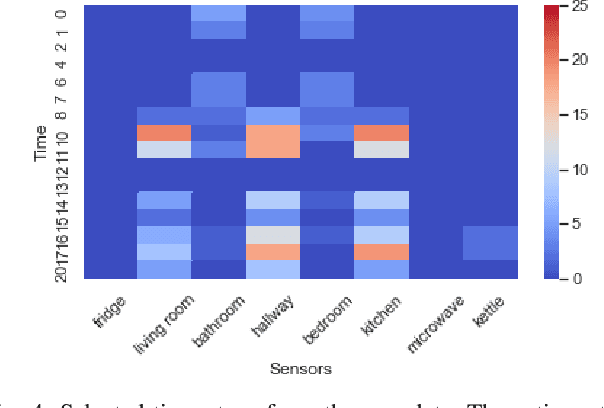
Behavioural symptoms and urinary tract infections (UTI) are among the most common problems faced by people with dementia. One of the key challenges in the management of these conditions is early detection and timely intervention in order to reduce distress and avoid unplanned hospital admissions. Using in-home sensing technologies and machine learning models for sensor data integration and analysis provides opportunities to detect and predict clinically significant events and changes in health status. We have developed an integrated platform to collect in-home sensor data and performed an observational study to apply machine learning models for agitation and UTI risk analysis. We collected a large dataset from 88 participants with a mean age of 82 and a standard deviation of 6.5 (47 females and 41 males) to evaluate a new deep learning model that utilises attention and rational mechanism. The proposed solution can process a large volume of data over a period of time and extract significant patterns in a time-series data (i.e. attention) and use the extracted features and patterns to train risk analysis models (i.e. rational). The proposed model can explain the predictions by indicating which time-steps and features are used in a long series of time-series data. The model provides a recall of 91\% and precision of 83\% in detecting the risk of agitation and UTIs. This model can be used for early detection of conditions such as UTIs and managing of neuropsychiatric symptoms such as agitation in association with initial treatment and early intervention approaches. In our study we have developed a set of clinical pathways for early interventions using the alerts generated by the proposed model and a clinical monitoring team has been set up to use the platform and respond to the alerts according to the created intervention plans.
Emotive Response to a Hybrid-Face Robot and Translation to Consumer Social Robots
Dec 08, 2020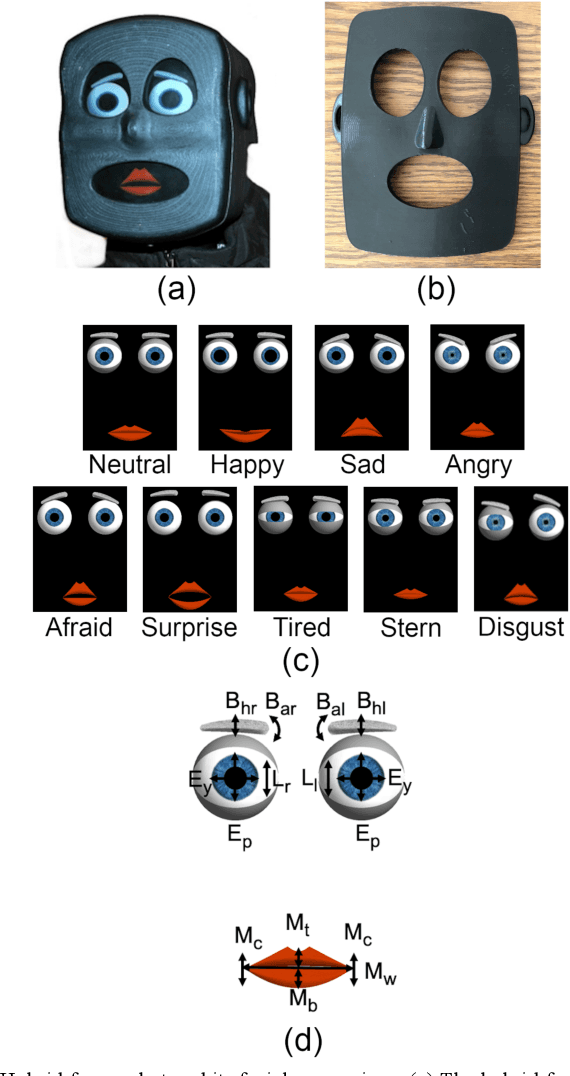
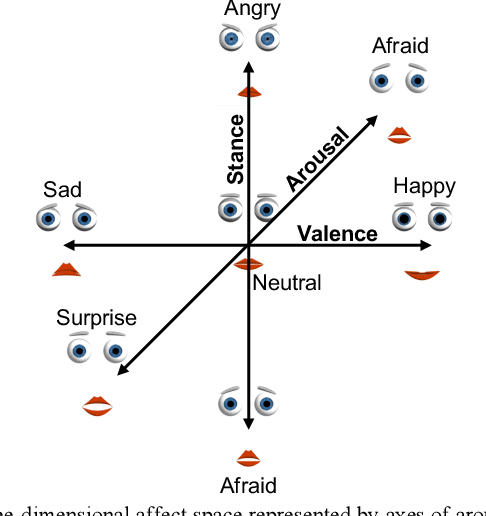

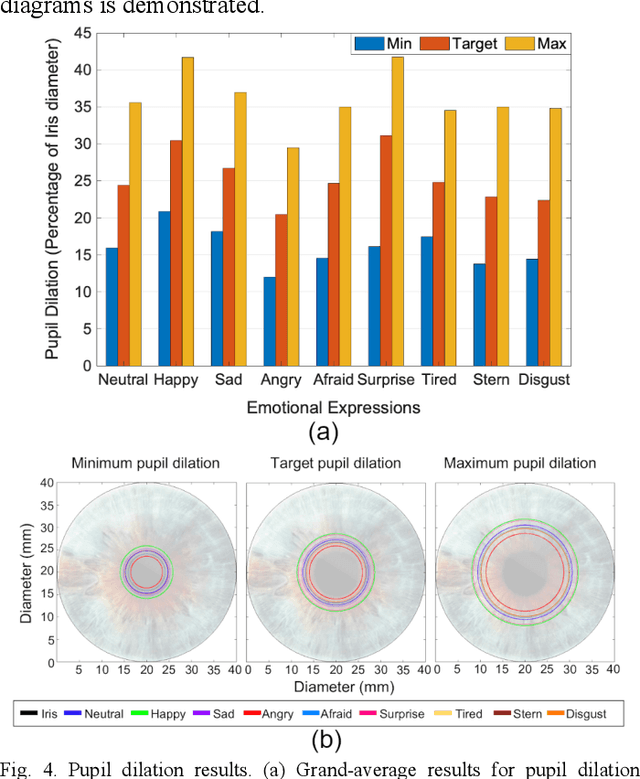
We introduce the conceptual formulation, design, fabrication, control and commercial translation with IoT connection of a hybrid-face social robot and validation of human emotional response to its affective interactions. The hybrid-face robot integrates a 3D printed faceplate and a digital display to simplify conveyance of complex facial movements while providing the impression of three-dimensional depth for natural interaction. We map the space of potential emotions of the robot to specific facial feature parameters and characterise the recognisability of the humanoid hybrid-face robot's archetypal facial expressions. We introduce pupil dilation as an additional degree of freedom for conveyance of emotive states. Human interaction experiments demonstrate the ability to effectively convey emotion from the hybrid-robot face to human observers by mapping their neurophysiological electroencephalography (EEG) response to perceived emotional information and through interviews. Results show main hybrid-face robotic expressions can be discriminated with recognition rates above 80% and invoke human emotive response similar to that of actual human faces as measured by the face-specific N170 event-related potentials in EEG. The hybrid-face robot concept has been modified, implemented, and released in the commercial IoT robotic platform Miko (My Companion), an affective robot with facial and conversational features currently in use for human-robot interaction in children by Emotix Inc. We demonstrate that human EEG responses to Miko emotions are comparative to neurophysiological responses for actual human facial recognition. Finally, interviews show above 90% expression recognition rates in our commercial robot. We conclude that simplified hybrid-face abstraction conveys emotions effectively and enhances human-robot interaction.
Machine learning for risk analysis of Urinary Tract Infection in people with dementia
Nov 27, 2020
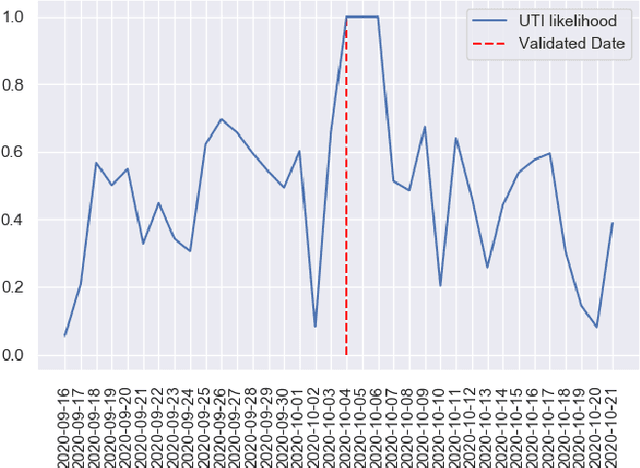
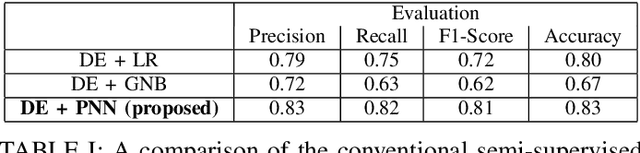
The Urinary Tract Infections (UTIs) are one of the top reasons for unplanned hospital admissions in people with dementia, and if detected early, they can be timely treated. However, the standard UTI diagnosis tests, e.g. urine tests, will be only taken if the patients are clinically suspected of having UTIs. This causes a delay in diagnosis and treatment of the conditions and in some cases like people with dementia, the symptoms can be difficult to observe. Delay in detection and treatment of dementia is one of the key reasons for unplanned hospital admissions in people with dementia. To address these issues, we have developed a technology-assisted monitoring system, which is a Class 1 medical device. The system uses off-the-shelf and low-cost in-home sensory devices to monitor environmental and physiological data of people with dementia within their own homes. We have designed a machine learning model to use the data and provide risk analysis for UTIs. We use a semi-supervised learning model which leverage the environmental data, i.e. the data collected from the motion sensors, smart plugs and network-connected body temperature monitoring devices in the home, to detect patterns that can show the risk of UTIs. Since the data is noisy and partially labelled, we combine the neural networks and probabilistic neural networks to train an auto-encoder, which is to extract the general representation of the data. We will demonstrate our smart home management by videos/online, and show how our model can pick up the UTI related patterns.