 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Synthetic Doctor-Patient Conversations for Long-form Audio Summarization
Apr 07, 2026Long-context audio reasoning is underserved in both training data and evaluation. Existing benchmarks target short-context tasks, and the open-ended generation tasks most relevant to long-context reasoning pose well-known challenges for automatic evaluation. We propose a synthetic data generation pipeline designed to serve both as a training resource and as a controlled evaluation environment, and instantiate it for first-visit doctor-patient conversations with SOAP note generation as the task. The pipeline has three stages, persona-driven dialogue generation, multi-speaker audio synthesis with overlap/pause modeling, room acoustics, and sound events, and LLM-based reference SOAP note production, built entirely on open-weight models. We release 8,800 synthetic conversations with 1.3k hours of corresponding audio and reference notes. Evaluating current open-weight systems, we find that cascaded approaches still substantially outperform end-to-end models.
SDialog: A Python Toolkit for End-to-End Agent Building, User Simulation, Dialog Generation, and Evaluation
Dec 12, 2025We present SDialog, an MIT-licensed open-source Python toolkit that unifies dialog generation, evaluation and mechanistic interpretability into a single end-to-end framework for building and analyzing LLM-based conversational agents. Built around a standardized \texttt{Dialog} representation, SDialog provides: (1) persona-driven multi-agent simulation with composable orchestration for controlled, synthetic dialog generation, (2) comprehensive evaluation combining linguistic metrics, LLM-as-a-judge and functional correctness validators, (3) mechanistic interpretability tools for activation inspection and steering via feature ablation and induction, and (4) audio generation with full acoustic simulation including 3D room modeling and microphone effects. The toolkit integrates with all major LLM backends, enabling mixed-backend experiments under a unified API. By coupling generation, evaluation, and interpretability in a dialog-centric architecture, SDialog enables researchers to build, benchmark and understand conversational systems more systematically.
Speaker Diarization using Deep Recurrent Convolutional Neural Networks for Speaker Embeddings
Sep 15, 2017
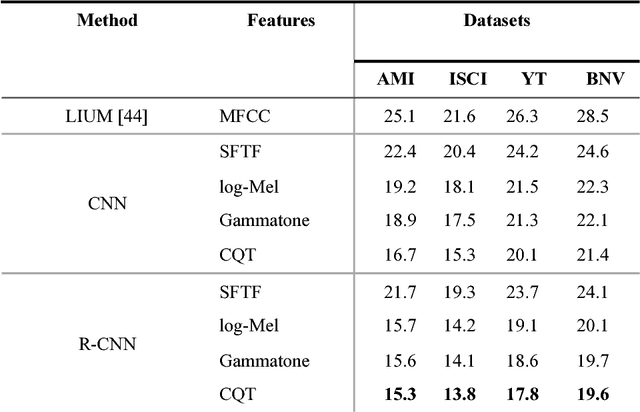
In this paper we propose a new method of speaker diarization that employs a deep learning architecture to learn speaker embeddings. In contrast to the traditional approaches that build their speaker embeddings using manually hand-crafted spectral features, we propose to train for this purpose a recurrent convolutional neural network applied directly on magnitude spectrograms. To compare our approach with the state of the art, we collect and release for the public an additional dataset of over 6 hours of fully annotated broadcast material. The results of our evaluation on the new dataset and three other benchmark datasets show that our proposed method significantly outperforms the competitors and reduces diarization error rate by a large margin of over 30% with respect to the baseline.