 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Generative Approach for Financial Causality Extraction
Apr 12, 2022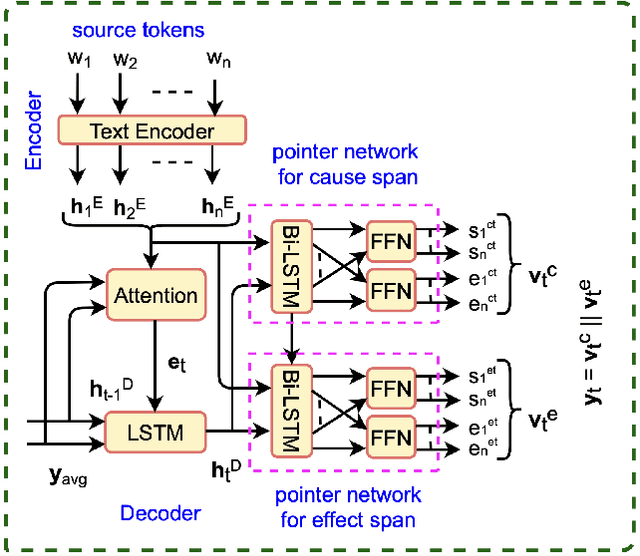
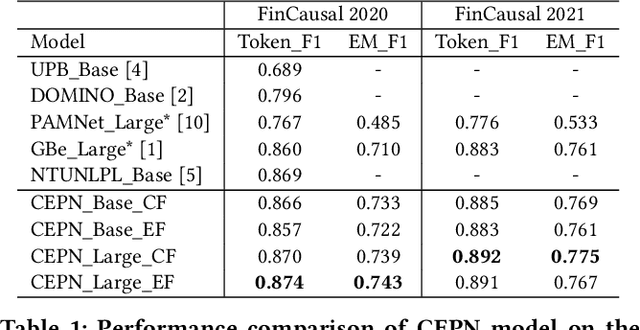
Causality represents the foremost relation between events in financial documents such as financial news articles, financial reports. Each financial causality contains a cause span and an effect span. Previous works proposed sequence labeling approaches to solve this task. But sequence labeling models find it difficult to extract multiple causalities and overlapping causalities from the text segments. In this paper, we explore a generative approach for causality extraction using the encoder-decoder framework and pointer networks. We use a causality dataset from the financial domain, \textit{FinCausal}, for our experiments and our proposed framework achieves very competitive performance on this dataset.
Prabhupadavani: A Code-mixed Speech Translation Data for 25 Languages
Jan 27, 2022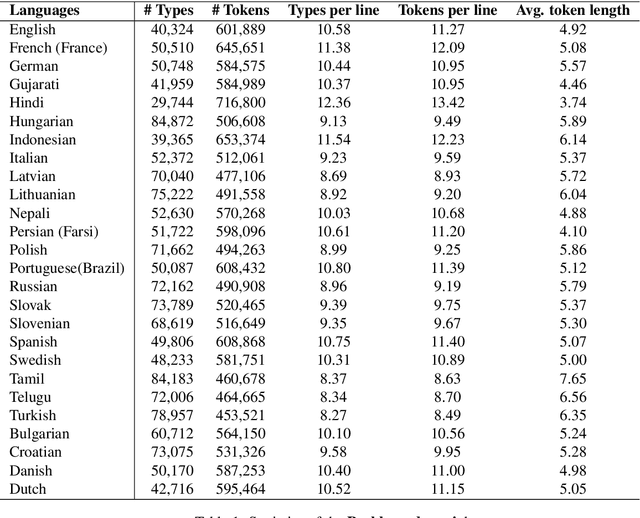


Nowadays, code-mixing has become ubiquitous in Natural Language Processing (NLP); however, no efforts have been made to address this phenomenon for Speech Translation (ST) task. This can be solely attributed to the lack of code-mixed ST task labelled data. Thus, we introduce Prabhupadavani, a multilingual code-mixed ST dataset for 25 languages, covering ten language families, containing 94 hours of speech by 130+ speakers, manually aligned with corresponding text in the target language. Prabhupadvani is the first code-mixed ST dataset available in the ST literature to the best of our knowledge. This data also can be used for a code-mixed machine translation task. All the dataset and code can be accessed at: \url{https://github.com/frozentoad9/CMST}
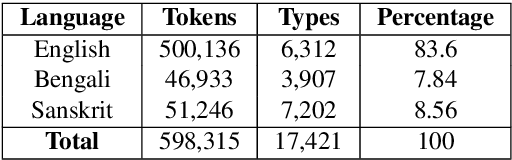
Systematic Investigation of Strategies Tailored for Low-Resource Settings for Sanskrit Dependency Parsing
Jan 27, 2022Existing state of the art approaches for Sanskrit Dependency Parsing (SDP), are hybrid in nature, and rely on a lexicon-driven shallow parser for linguistically motivated feature engineering. However, these methods fail to handle out of vocabulary (OOV) words, which limits their applicability in realistic scenarios. On the other hand, purely data-driven approaches do not match the performance of hybrid approaches due to the labelled data sparsity. Thus, in this work, we investigate the following question: How far can we push a purely data-driven approach using recently proposed strategies for low-resource settings? We experiment with five strategies, namely, data augmentation, sequential transfer learning, cross-lingual/mono-lingual pretraining, multi-task learning and self-training. Our proposed ensembled system outperforms the purely data-driven state of the art system by 2.8/3.9 points (Unlabelled Attachment Score (UAS)/Labelled Attachment Score (LAS)) absolute gain. Interestingly, it also supersedes the performance of the state of the art hybrid system by 1.2 points (UAS) absolute gain and shows comparable performance in terms of LAS. Code and data will be publicly available at: \url{https://github.com/Jivnesh/SanDP}.
LeSICiN: A Heterogeneous Graph-based Approach for Automatic Legal Statute Identification from Indian Legal Documents
Dec 29, 2021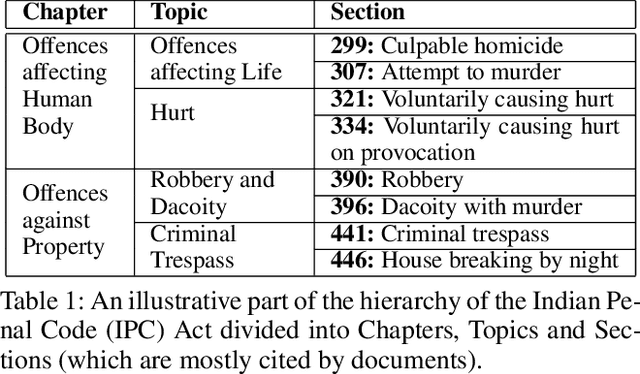
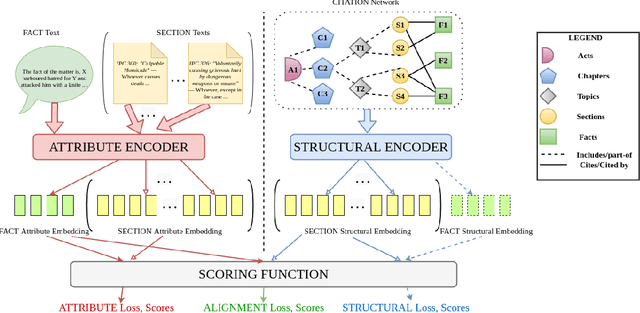
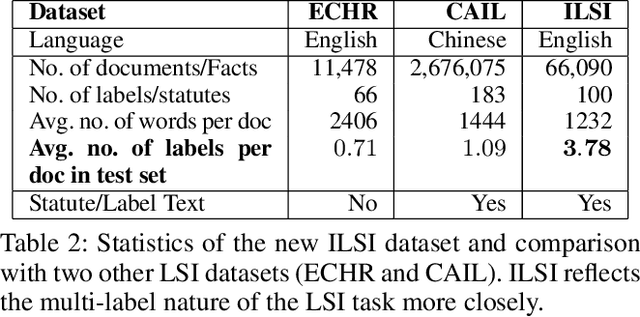
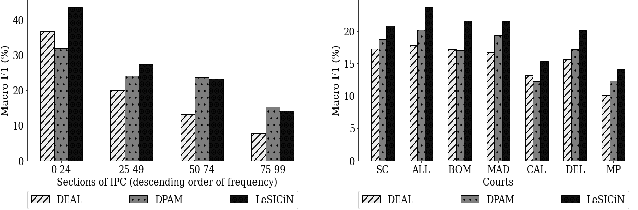
The task of Legal Statute Identification (LSI) aims to identify the legal statutes that are relevant to a given description of Facts or evidence of a legal case. Existing methods only utilize the textual content of Facts and legal articles to guide such a task. However, the citation network among case documents and legal statutes is a rich source of additional information, which is not considered by existing models. In this work, we take the first step towards utilising both the text and the legal citation network for the LSI task. We curate a large novel dataset for this task, including Facts of cases from several major Indian Courts of Law, and statutes from the Indian Penal Code (IPC). Modeling the statutes and training documents as a heterogeneous graph, our proposed model LeSICiN can learn rich textual and graphical features, and can also tune itself to correlate these features. Thereafter, the model can be used to inductively predict links between test documents (new nodes whose graphical features are not available to the model) and statutes (existing nodes). Extensive experiments on the dataset show that our model comfortably outperforms several state-of-the-art baselines, by exploiting the graphical structure along with textual features. The dataset and our codes are available at https://github.com/Law-AI/LeSICiN.
MTLTS: A Multi-Task Framework To Obtain Trustworthy Summaries From Crisis-Related Microblogs
Dec 10, 2021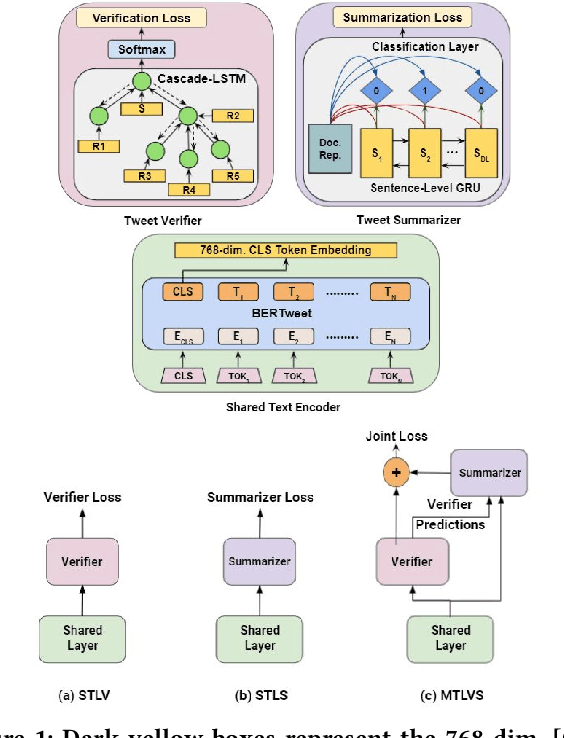
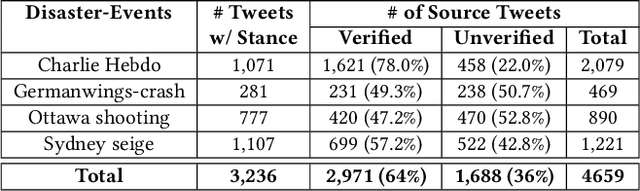
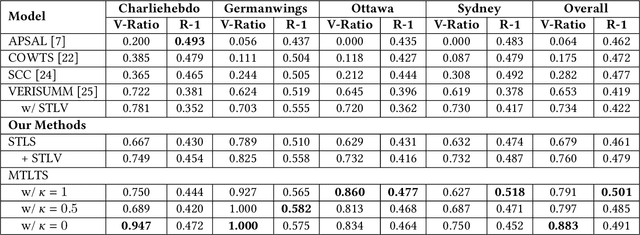
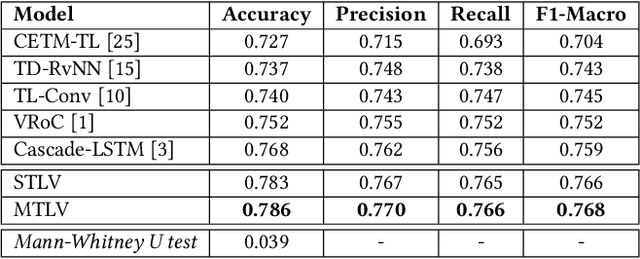
Occurrences of catastrophes such as natural or man-made disasters trigger the spread of rumours over social media at a rapid pace. Presenting a trustworthy and summarized account of the unfolding event in near real-time to the consumers of such potentially unreliable information thus becomes an important task. In this work, we propose MTLTS, the first end-to-end solution for the task that jointly determines the credibility and summary-worthiness of tweets. Our credibility verifier is designed to recursively learn the structural properties of a Twitter conversation cascade, along with the stances of replies towards the source tweet. We then take a hierarchical multi-task learning approach, where the verifier is trained at a lower layer, and the summarizer is trained at a deeper layer where it utilizes the verifier predictions to determine the salience of a tweet. Different from existing disaster-specific summarizers, we model tweet summarization as a supervised task. Such an approach can automatically learn summary-worthy features, and can therefore generalize well across domains. When trained on the PHEME dataset [29], not only do we outperform the strongest baselines for the auxiliary task of verification/rumour detection, we also achieve 21 - 35% gains in the verified ratio of summary tweets, and 16 - 20% gains in ROUGE1-F1 scores over the existing state-of-the-art solutions for the primary task of trustworthy summarization.
Representation Learning for Conversational Data using Discourse Mutual Information Maximization
Dec 04, 2021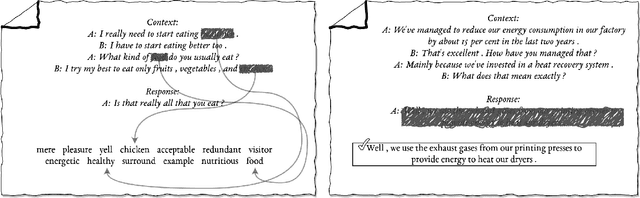
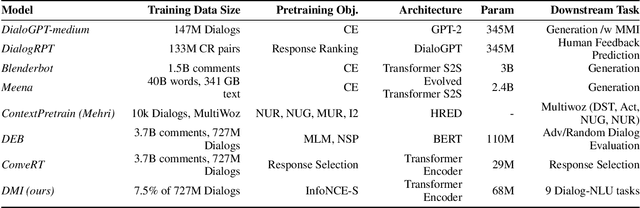
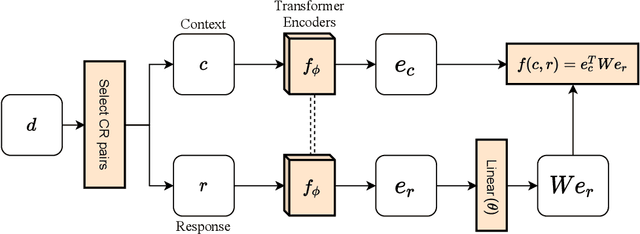

Although many pretrained models exist for text or images, there have been relatively fewer attempts to train representations specifically for dialog understanding. Prior works usually relied on finetuned representations based on generic text representation models like BERT or GPT-2. But, existing pretraining objectives do not take the structural information of text into consideration. Although generative dialog models can learn structural features too, we argue that the structure-unaware word-by-word generation is not suitable for effective conversation modeling. We empirically demonstrate that such representations do not perform consistently across various dialog understanding tasks. Hence, we propose a structure-aware Mutual Information based loss-function DMI (Discourse Mutual Information) for training dialog-representation models, that additionally captures the inherent uncertainty in response prediction. Extensive evaluation on nine diverse dialog modeling tasks shows that our proposed DMI-based models outperform strong baselines by significant margins, even with small-scale pretraining. Our models show the most promising performance on the dialog evaluation task DailyDialog++, in both random and adversarial negative scenarios.
Learning Low-Dimensional Quadratic-Embeddings of High-Fidelity Nonlinear Dynamics using Deep Learning
Nov 25, 2021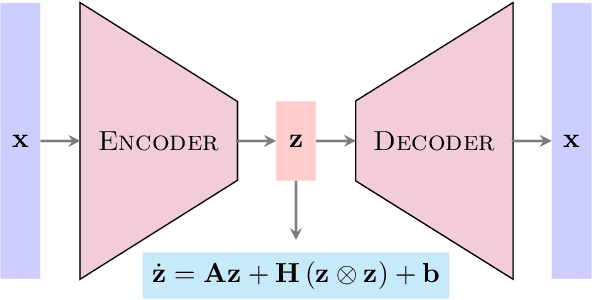
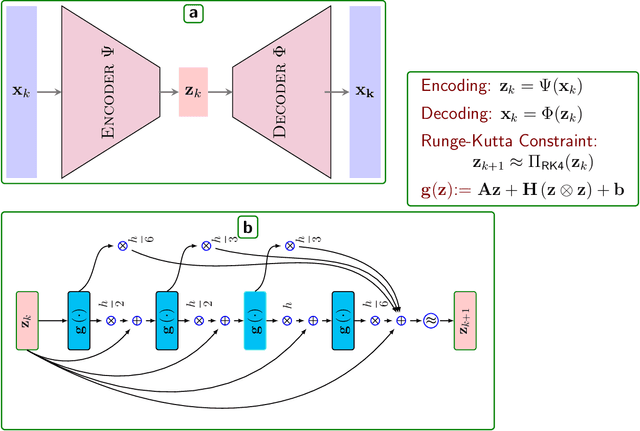
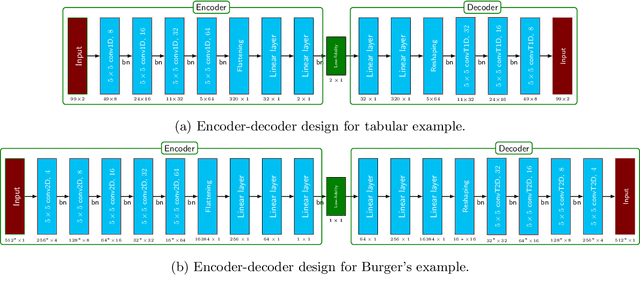
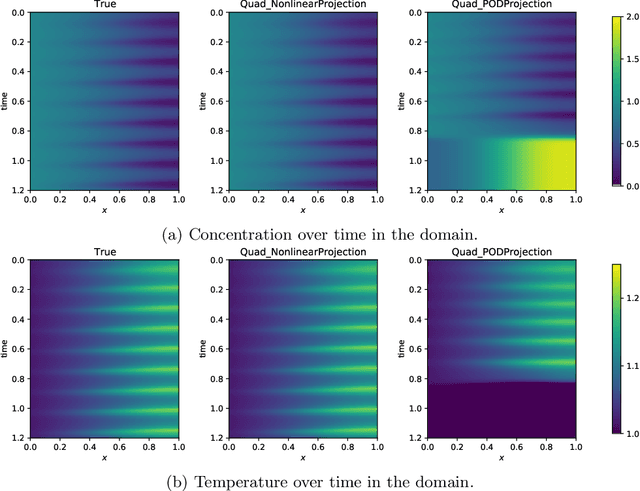
Learning dynamical models from data plays a vital role in engineering design, optimization, and predictions. Building models describing dynamics of complex processes (e.g., weather dynamics, or reactive flows) using empirical knowledge or first principles are onerous or infeasible. Moreover, these models are high-dimensional but spatially correlated. It is, however, observed that the dynamics of high-fidelity models often evolve in low-dimensional manifolds. Furthermore, it is also known that for sufficiently smooth vector fields defining the nonlinear dynamics, a quadratic model can describe it accurately in an appropriate coordinate system, conferring to the McCormick relaxation idea in nonconvex optimization. Here, we aim at finding a low-dimensional embedding of high-fidelity dynamical data, ensuring a simple quadratic model to explain its dynamics. To that aim, this work leverages deep learning to identify low-dimensional quadratic embeddings for high-fidelity dynamical systems. Precisely, we identify the embedding of data using an autoencoder to have the desired property of the embedding. We also embed a Runge-Kutta method to avoid the time-derivative computations, which is often a challenge. We illustrate the ability of the approach by a couple of examples, arising in describing flow dynamics and the oscillatory tubular reactor model.
PASTE: A Tagging-Free Decoding Framework Using Pointer Networks for Aspect Sentiment Triplet Extraction
Oct 10, 2021


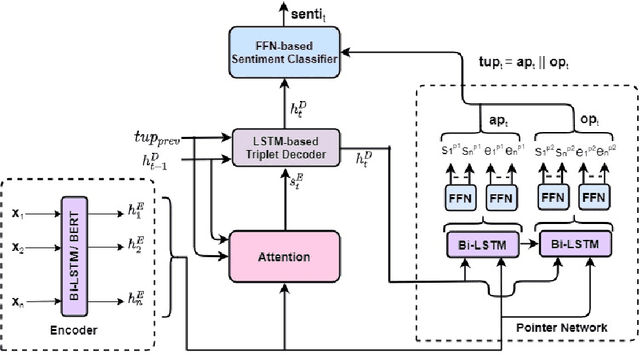
Aspect Sentiment Triplet Extraction (ASTE) deals with extracting opinion triplets, consisting of an opinion target or aspect, its associated sentiment, and the corresponding opinion term/span explaining the rationale behind the sentiment. Existing research efforts are majorly tagging-based. Among the methods taking a sequence tagging approach, some fail to capture the strong interdependence between the three opinion factors, whereas others fall short of identifying triplets with overlapping aspect/opinion spans. A recent grid tagging approach on the other hand fails to capture the span-level semantics while predicting the sentiment between an aspect-opinion pair. Different from these, we present a tagging-free solution for the task, while addressing the limitations of the existing works. We adapt an encoder-decoder architecture with a Pointer Network-based decoding framework that generates an entire opinion triplet at each time step thereby making our solution end-to-end. Interactions between the aspects and opinions are effectively captured by the decoder by considering their entire detected spans while predicting their connecting sentiment. Extensive experiments on several benchmark datasets establish the better efficacy of our proposed approach, especially in the recall, and in predicting multiple and aspect/opinion-overlapped triplets from the same review sentence. We report our results both with and without BERT and also demonstrate the utility of domain-specific BERT post-training for the task.
Learning Dynamics from Noisy Measurements using Deep Learning with a Runge-Kutta Constraint
Sep 23, 2021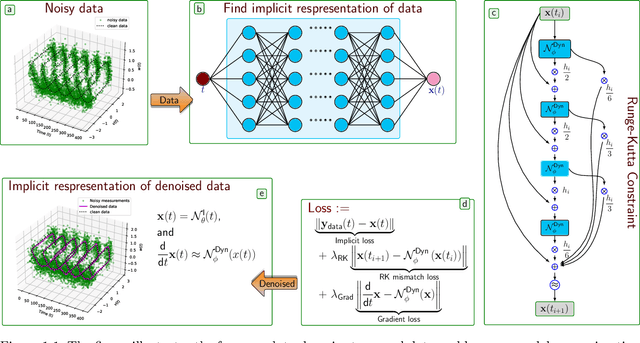
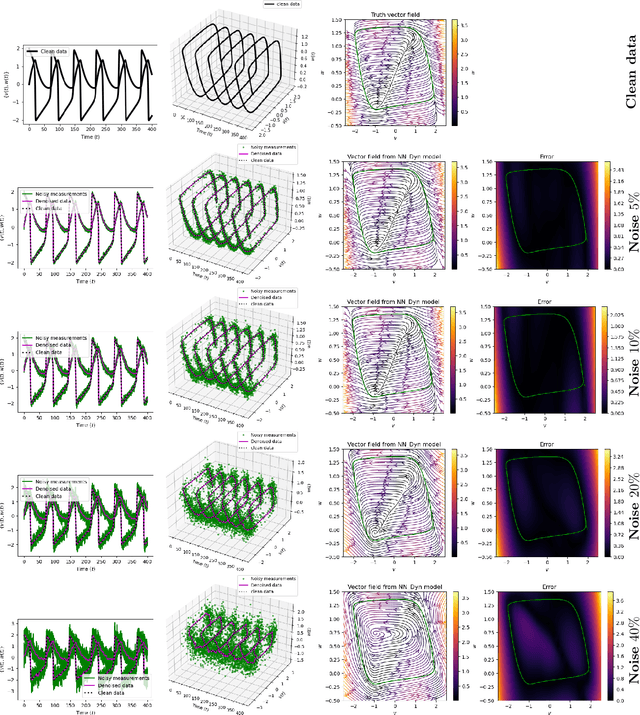
Measurement noise is an integral part while collecting data of a physical process. Thus, noise removal is a necessary step to draw conclusions from these data, and it often becomes quite essential to construct dynamical models using these data. We discuss a methodology to learn differential equation(s) using noisy and sparsely sampled measurements. In our methodology, the main innovation can be seen in of integration of deep neural networks with a classical numerical integration method. Precisely, we aim at learning a neural network that implicitly represents the data and an additional neural network that models the vector fields of the dependent variables. We combine these two networks by enforcing the constraint that the data at the next time-steps can be given by following a numerical integration scheme such as the fourth-order Runge-Kutta scheme. The proposed framework to learn a model predicting the vector field is highly effective under noisy measurements. The approach can handle scenarios where dependent variables are not available at the same temporal grid. We demonstrate the effectiveness of the proposed method to learning models using data obtained from various differential equations. The proposed approach provides a promising methodology to learn dynamic models, where the first-principle understanding remains opaque.
Question Answering over Electronic Devices: A New Benchmark Dataset and a Multi-Task Learning based QA Framework
Sep 14, 2021
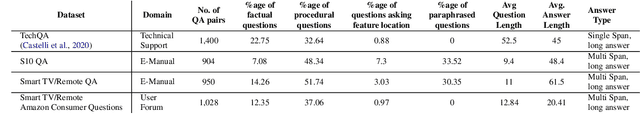
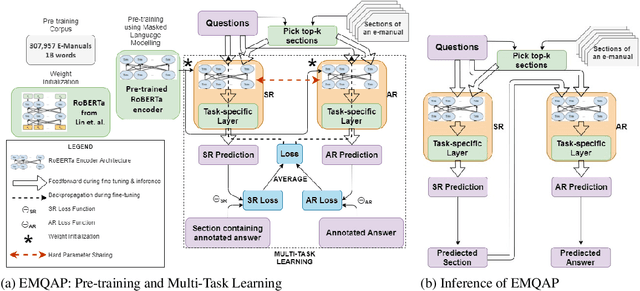
Answering questions asked from instructional corpora such as E-manuals, recipe books, etc., has been far less studied than open-domain factoid context-based question answering. This can be primarily attributed to the absence of standard benchmark datasets. In this paper we meticulously create a large amount of data connected with E-manuals and develop suitable algorithm to exploit it. We collect E-Manual Corpus, a huge corpus of 307,957 E-manuals and pretrain RoBERTa on this large corpus. We create various benchmark QA datasets which include question answer pairs curated by experts based upon two E-manuals, real user questions from Community Question Answering Forum pertaining to E-manuals etc. We introduce EMQAP (E-Manual Question Answering Pipeline) that answers questions pertaining to electronics devices. Built upon the pretrained RoBERTa, it harbors a supervised multi-task learning framework which efficiently performs the dual tasks of identifying the section in the E-manual where the answer can be found and the exact answer span within that section. For E-Manual annotated question-answer pairs, we show an improvement of about 40% in ROUGE-L F1 scores over the most competitive baseline. We perform a detailed ablation study and establish the versatility of EMQAP across different circumstances. The code and datasets are shared at https://github.com/abhi1nandy2/EMNLP-2021-Findings, and the corresponding project website is https://sites.google.com/view/emanualqa/home.