 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSiam R-CNN: Visual Tracking by Re-Detection
Nov 28, 2019
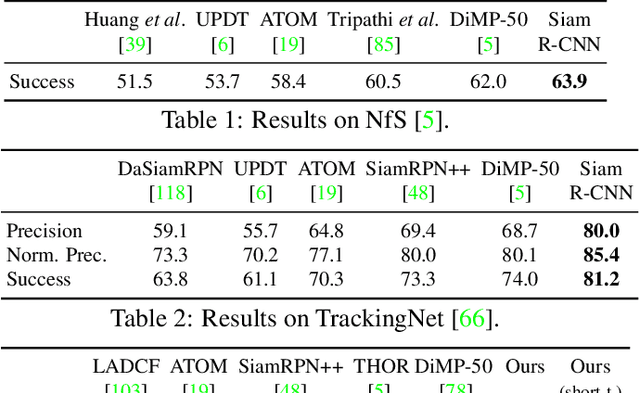
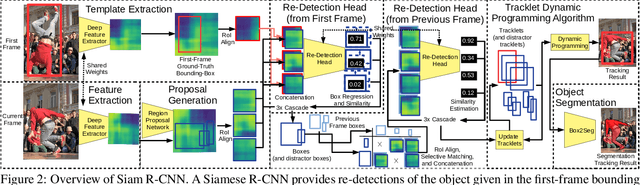
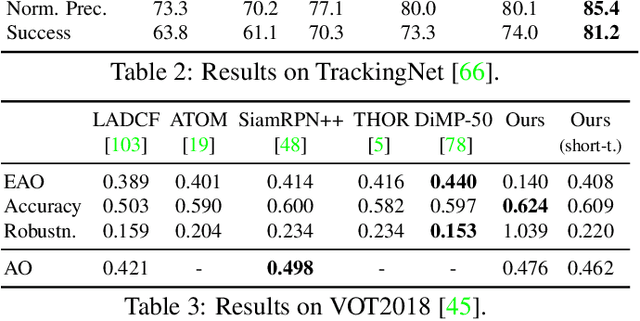
We present Siam R-CNN, a Siamese re-detection architecture which unleashes the full power of two-stage object detection approaches for visual object tracking. We combine this with a novel tracklet-based dynamic programming algorithm, which takes advantage of re-detections of both the first-frame template and previous-frame predictions, to model the full history of both the object to be tracked and potential distractor objects. This enables our approach to make better tracking decisions, as well as to re-detect tracked objects after long occlusion. Finally, we propose a novel hard example mining strategy to improve Siam R-CNN's robustness to similar looking objects. The proposed tracker achieves the current best performance on ten tracking benchmarks, with especially strong results for long-term tracking.
BoLTVOS: Box-Level Tracking for Video Object Segmentation
Apr 09, 2019
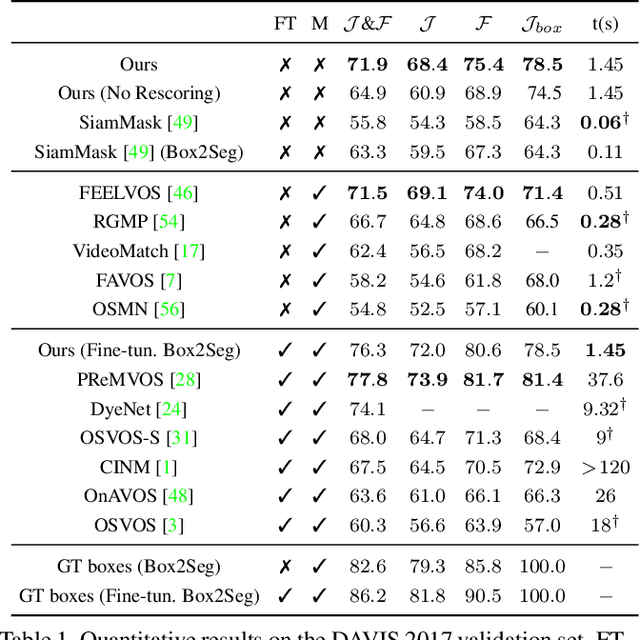
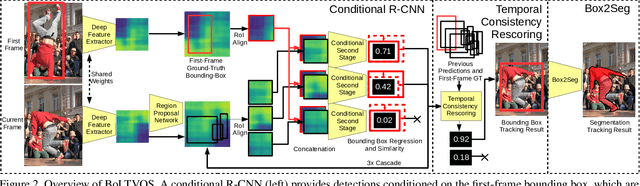
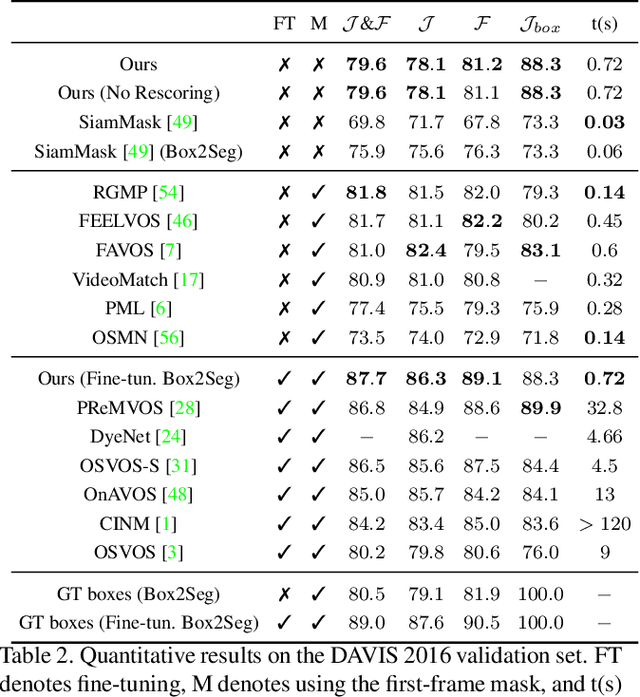
We approach video object segmentation (VOS) by splitting the task into two sub-tasks: bounding box level tracking, followed by bounding box segmentation. Following this paradigm, we present BoLTVOS (Box-Level Tracking for VOS), which consists of an R-CNN detector conditioned on the first-frame bounding box to detect the object of interest, a temporal consistency rescoring algorithm, and a Box2Seg network that converts bounding boxes to segmentation masks. BoLTVOS performs VOS using only the firstframe bounding box without the mask. We evaluate our approach on DAVIS 2017 and YouTube-VOS, and show that it outperforms all methods that do not perform first-frame fine-tuning. We further present BoLTVOS-ft, which learns to segment the object in question using the first-frame mask while it is being tracked, without increasing the runtime. BoLTVOS-ft outperforms PReMVOS, the previously best performing VOS method on DAVIS 2016 and YouTube-VOS, while running up to 45 times faster. Our bounding box tracker also outperforms all previous short-term and longterm trackers on the bounding box level tracking datasets OTB 2015 and LTB35.
MOTS: Multi-Object Tracking and Segmentation
Apr 08, 2019
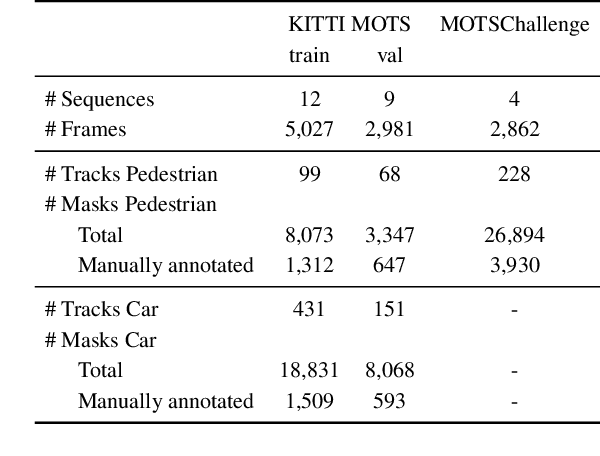

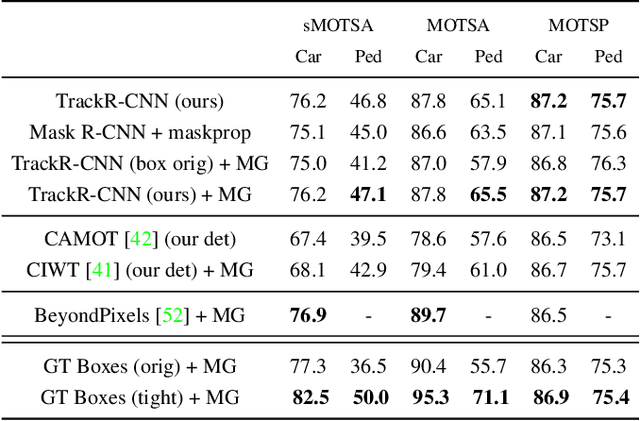
This paper extends the popular task of multi-object tracking to multi-object tracking and segmentation (MOTS). Towards this goal, we create dense pixel-level annotations for two existing tracking datasets using a semi-automatic annotation procedure. Our new annotations comprise 65,213 pixel masks for 977 distinct objects (cars and pedestrians) in 10,870 video frames. For evaluation, we extend existing multi-object tracking metrics to this new task. Moreover, we propose a new baseline method which jointly addresses detection, tracking, and segmentation with a single convolutional network. We demonstrate the value of our datasets by achieving improvements in performance when training on MOTS annotations. We believe that our datasets, metrics and baseline will become a valuable resource towards developing multi-object tracking approaches that go beyond 2D bounding boxes. We make our annotations, code, and models available at https://www.vision.rwth-aachen.de/page/mots.
* CVPR 2019 camera-ready version
FEELVOS: Fast End-to-End Embedding Learning for Video Object Segmentation
Apr 08, 2019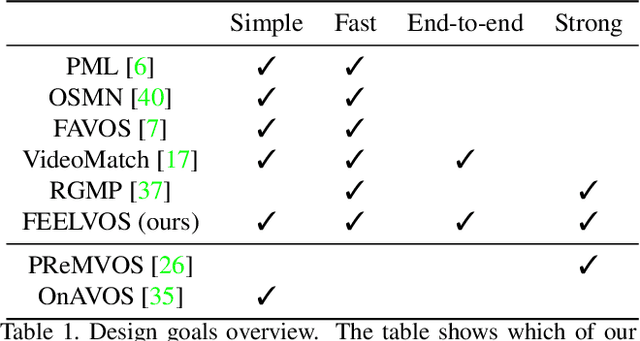
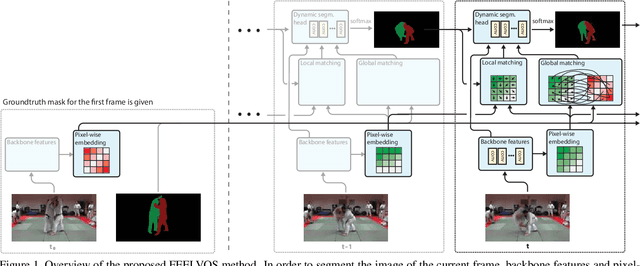
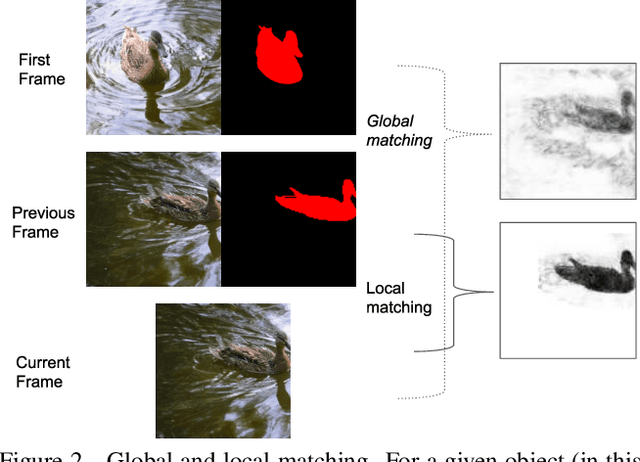
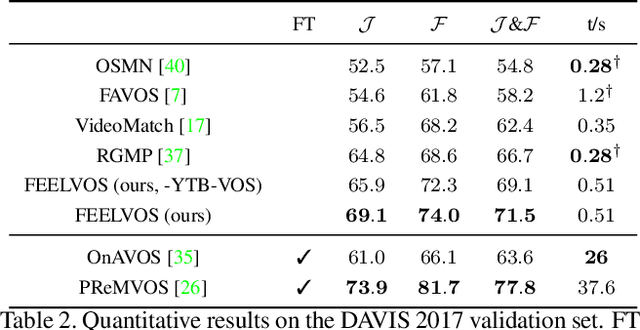
Many of the recent successful methods for video object segmentation (VOS) are overly complicated, heavily rely on fine-tuning on the first frame, and/or are slow, and are hence of limited practical use. In this work, we propose FEELVOS as a simple and fast method which does not rely on fine-tuning. In order to segment a video, for each frame FEELVOS uses a semantic pixel-wise embedding together with a global and a local matching mechanism to transfer information from the first frame and from the previous frame of the video to the current frame. In contrast to previous work, our embedding is only used as an internal guidance of a convolutional network. Our novel dynamic segmentation head allows us to train the network, including the embedding, end-to-end for the multiple object segmentation task with a cross entropy loss. We achieve a new state of the art in video object segmentation without fine-tuning with a J&F measure of 71.5% on the DAVIS 2017 validation set. We make our code and models available at https://github.com/tensorflow/models/tree/master/research/feelvos.
* CVPR 2019 camera-ready version
Large-Scale Object Mining for Object Discovery from Unlabeled Video
Feb 28, 2019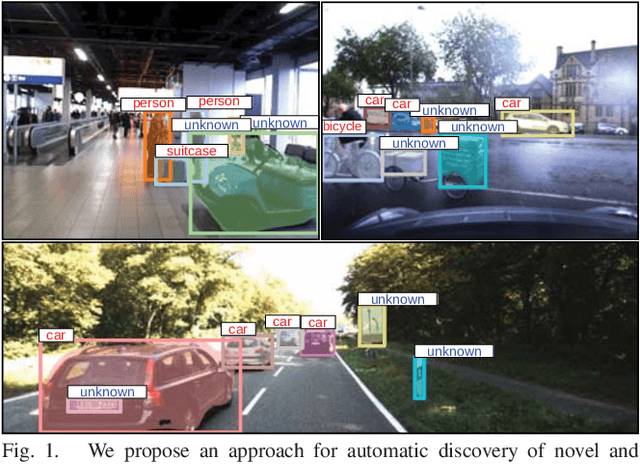
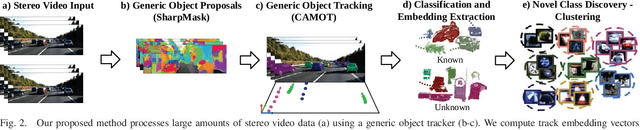
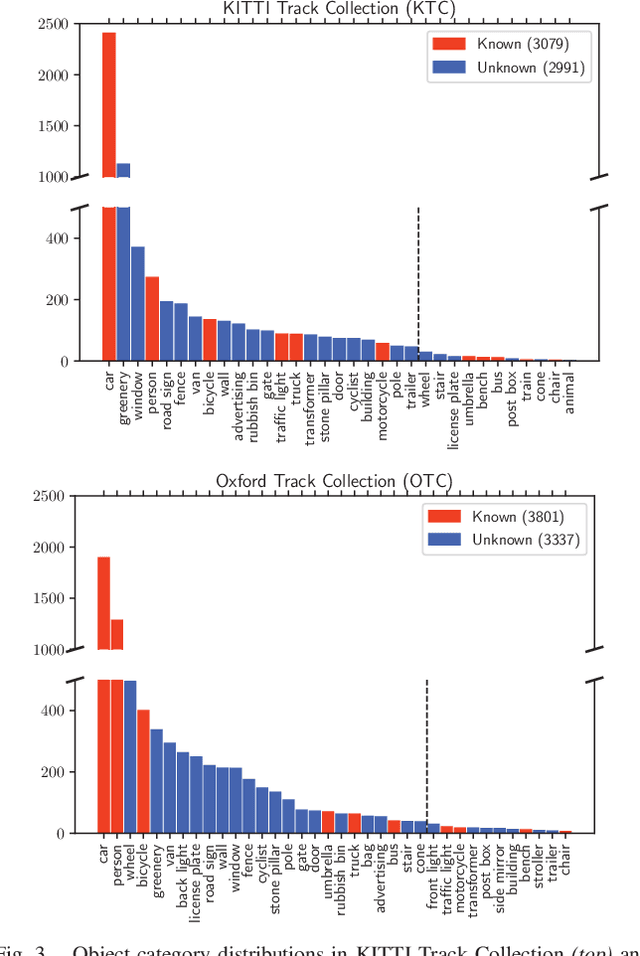
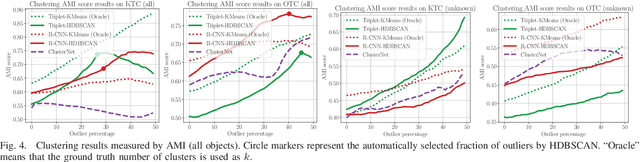
This paper addresses the problem of object discovery from unlabeled driving videos captured in a realistic automotive setting. Identifying recurring object categories in such raw video streams is a very challenging problem. Not only do object candidates first have to be localized in the input images, but many interesting object categories occur relatively infrequently. Object discovery will therefore have to deal with the difficulties of operating in the long tail of the object distribution. We demonstrate the feasibility of performing fully automatic object discovery in such a setting by mining object tracks using a generic object tracker. In order to facilitate further research in object discovery, we release a collection of more than 360,000 automatically mined object tracks from 10+ hours of video data (560,000 frames). We use this dataset to evaluate the suitability of different feature representations and clustering strategies for object discovery.
4D Generic Video Object Proposals
Jan 26, 2019
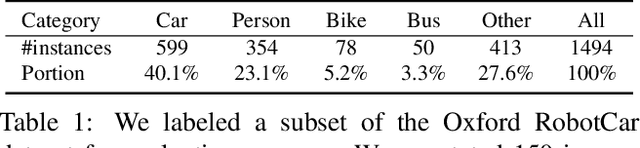
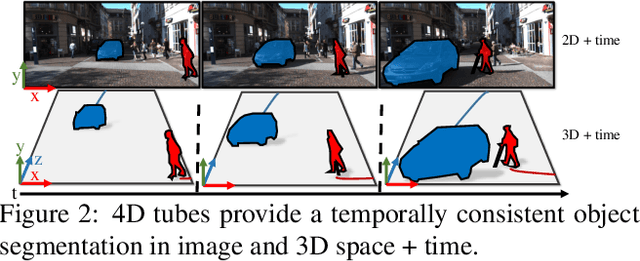
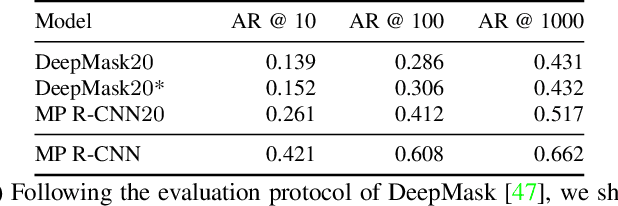
Many high-level video understanding methods require input in the form of object proposals. Currently, such proposals are predominantly generated with the help of networks that were trained for detecting and segmenting a set of known object classes, which limits their applicability to cases where all objects of interest are represented in the training set. This is a restriction for automotive scenarios, where unknown objects can frequently occur. We propose an approach that can reliably extract spatio-temporal object proposals for both known and unknown object categories from stereo video. Our 4D Generic Video Tubes (4D-GVT) method leverages motion cues, stereo data, and object instance segmentation to compute a compact set of video-object proposals that precisely localizes object candidates and their contours in 3D space and time. We show that given only a small amount of labeled data, our 4D-GVT proposal generator generalizes well to real-world scenarios, in which unknown categories appear. It outperforms other approaches that try to detect as many objects as possible by increasing the number of classes in the training set to several thousand.
PReMVOS: Proposal-generation, Refinement and Merging for Video Object Segmentation
Nov 03, 2018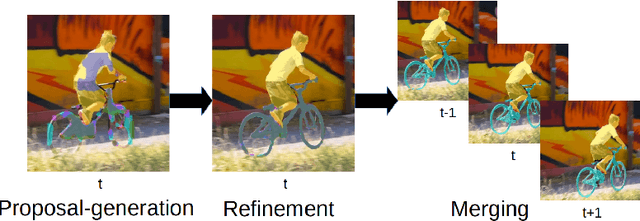
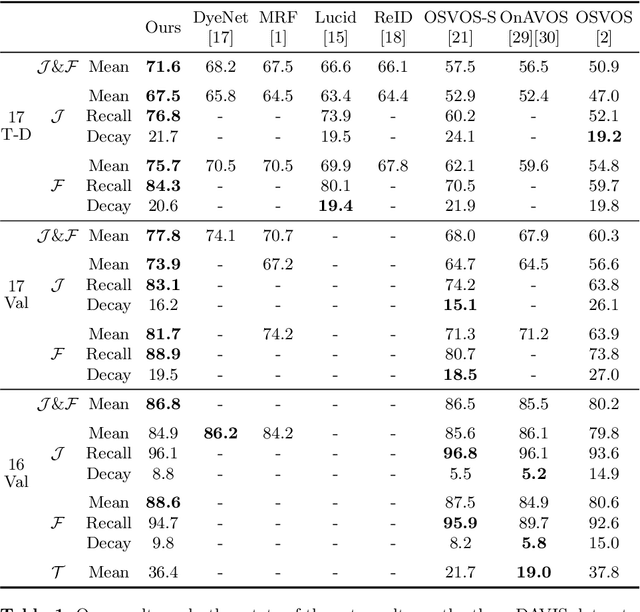
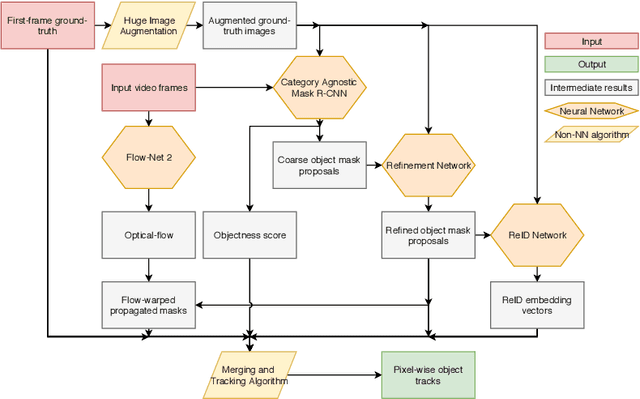
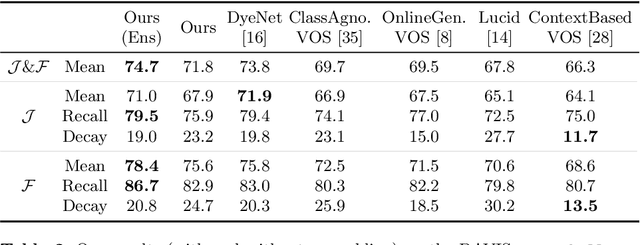
We address semi-supervised video object segmentation, the task of automatically generating accurate and consistent pixel masks for objects in a video sequence, given the first-frame ground truth annotations. Towards this goal, we present the PReMVOS algorithm (Proposal-generation, Refinement and Merging for Video Object Segmentation). Our method separates this problem into two steps, first generating a set of accurate object segmentation mask proposals for each video frame and then selecting and merging these proposals into accurate and temporally consistent pixel-wise object tracks over a video sequence in a way which is designed to specifically tackle the difficult challenges involved with segmenting multiple objects across a video sequence. Our approach surpasses all previous state-of-the-art results on the DAVIS 2017 video object segmentation benchmark with a J & F mean score of 71.6 on the test-dev dataset, and achieves first place in both the DAVIS 2018 Video Object Segmentation Challenge and the YouTube-VOS 1st Large-scale Video Object Segmentation Challenge.
Towards Large-Scale Video Video Object Mining
Sep 19, 2018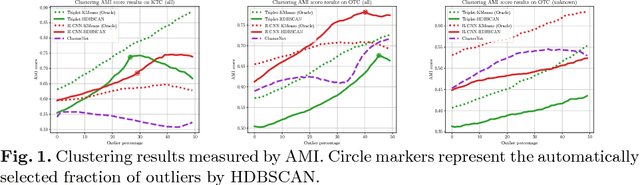

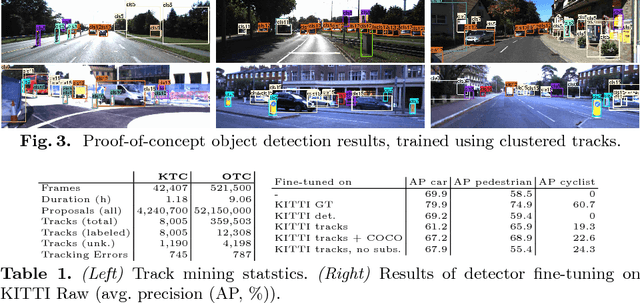
We propose to leverage a generic object tracker in order to perform object mining in large-scale unlabeled videos, captured in a realistic automotive setting. We present a dataset of more than 360'000 automatically mined object tracks from 10+ hours of video data (560'000 frames) and propose a method for automated novel category discovery and detector learning. In addition, we show preliminary results on using the mined tracks for object detector adaptation.
Iteratively Trained Interactive Segmentation
May 11, 2018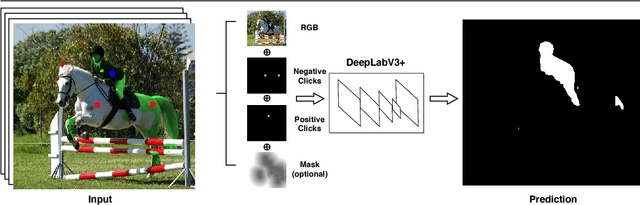
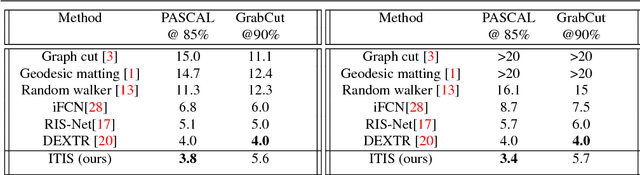

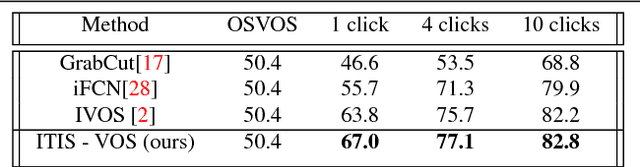
Deep learning requires large amounts of training data to be effective. For the task of object segmentation, manually labeling data is very expensive, and hence interactive methods are needed. Following recent approaches, we develop an interactive object segmentation system which uses user input in the form of clicks as the input to a convolutional network. While previous methods use heuristic click sampling strategies to emulate user clicks during training, we propose a new iterative training strategy. During training, we iteratively add clicks based on the errors of the currently predicted segmentation. We show that our iterative training strategy together with additional improvements to the network architecture results in improved results over the state-of-the-art.
Large-Scale Object Discovery and Detector Adaptation from Unlabeled Video
Dec 23, 2017
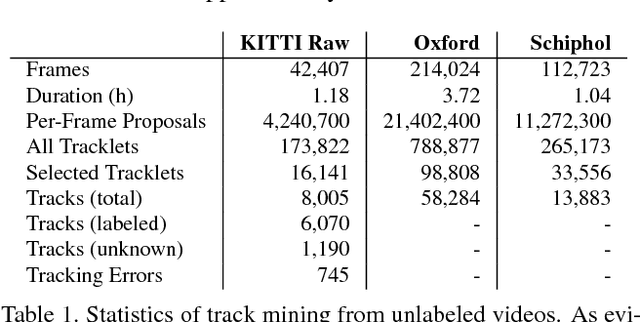
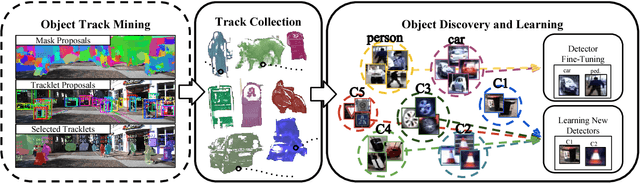

We explore object discovery and detector adaptation based on unlabeled video sequences captured from a mobile platform. We propose a fully automatic approach for object mining from video which builds upon a generic object tracking approach. By applying this method to three large video datasets from autonomous driving and mobile robotics scenarios, we demonstrate its robustness and generality. Based on the object mining results, we propose a novel approach for unsupervised object discovery by appearance-based clustering. We show that this approach successfully discovers interesting objects relevant to driving scenarios. In addition, we perform self-supervised detector adaptation in order to improve detection performance on the KITTI dataset for existing categories. Our approach has direct relevance for enabling large-scale object learning for autonomous driving.