 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistant Vehicle Detection Using Radar and Vision
Jan 30, 2019
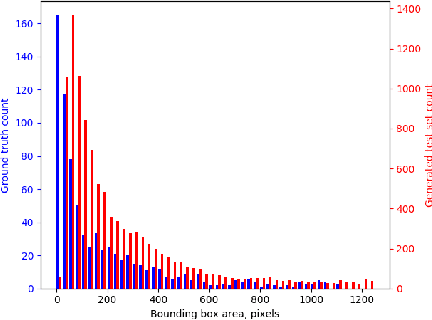

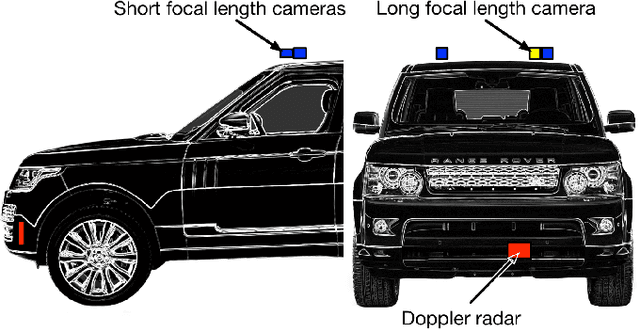
For autonomous vehicles to be able to operate successfully they need to be aware of other vehicles with sufficient time to make safe, stable plans. Given the possible closing speeds between two vehicles, this necessitates the ability to accurately detect distant vehicles. Many current image-based object detectors using convolutional neural networks exhibit excellent performance on existing datasets such as KITTI. However, the performance of these networks falls when detecting small (distant) objects. We demonstrate that incorporating radar data can boost performance in these difficult situations. We also introduce an efficient automated method for training data generation using cameras of different focal lengths.
Imminent Collision Mitigation with Reinforcement Learning and Vision
Jan 03, 2019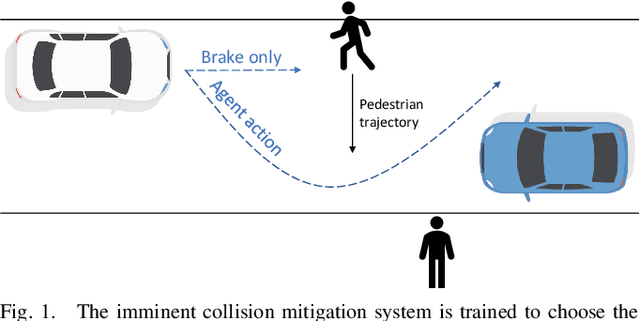


This work examines the role of reinforcement learning in reducing the severity of on-road collisions by controlling velocity and steering in situations in which contact is imminent. We construct a model, given camera images as input, that is capable of learning and predicting the dynamics of obstacles, cars and pedestrians, and train our policy using this model. Two policies that control both braking and steering are compared against a baseline where the only action taken is (conventional) braking in a straight line. The two policies are trained using two distinct reward structures, one where any and all collisions incur a fixed penalty, and a second one where the penalty is calculated based on already established delta-v models of injury severity. The results show that both policies exceed the performance of the baseline, with the policy trained using injury models having the highest performance.
I Can See Clearly Now : Image Restoration via De-Raining
Jan 03, 2019
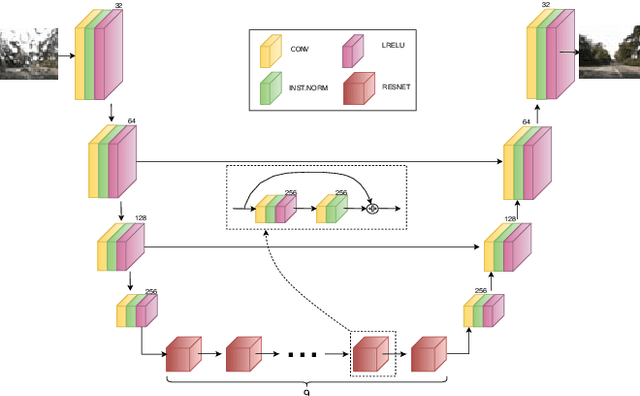
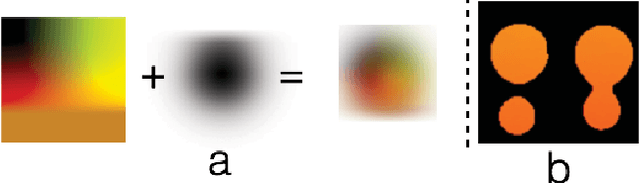

We present a method for improving segmentation tasks on images affected by adherent rain drops and streaks. We introduce a novel stereo dataset recorded using a system that allows one lens to be affected by real water droplets while keeping the other lens clear. We train a denoising generator using this dataset and show that it is effective at removing the effect of real water droplets, in the context of image reconstruction and road marking segmentation. To further test our de-noising approach, we describe a method of adding computer-generated adherent water droplets and streaks to any images, and use this technique as a proxy to demonstrate the effectiveness of our model in the context of general semantic segmentation. We benchmark our results using the CamVid road marking segmentation dataset, Cityscapes semantic segmentation datasets and our own real-rain dataset, and show significant improvement on all tasks.
The Right (Angled) Perspective: Improving the Understanding of Road Scenes using Boosted Inverse Perspective Mapping
Dec 03, 2018
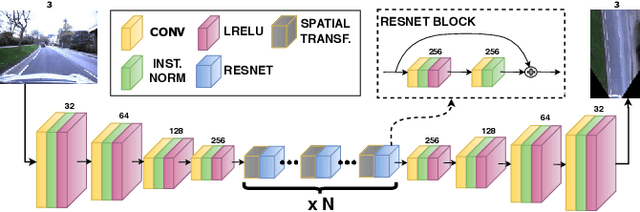


Many tasks performed by autonomous vehicles such as road marking detection, object tracking, and path planning are simpler in bird's-eye view. Hence, Inverse Perspective Mapping (IPM) is often applied to remove the perspective effect from a vehicle's front-facing camera and to remap its images into a 2D domain, resulting in a top-down view. Unfortunately, however, this leads to unnatural blurring and stretching of objects at further distance, due to the resolution of the camera, limiting applicability. In this paper, we present an adversarial learning approach for generating a significantly improved IPM from a single camera image in real time. The generated bird's-eye-view images contain sharper features (e.g. road markings) and a more homogeneous illumination, while (dynamic) objects are automatically removed from the scene, thus revealing the underlying road layout in an improved fashion. We demonstrate our framework using real-world data from the Oxford RobotCar Dataset and show that scene understanding tasks directly benefit from our boosted IPM approach.
Probably Unknown: Deep Inverse Sensor Modelling In Radar
Oct 18, 2018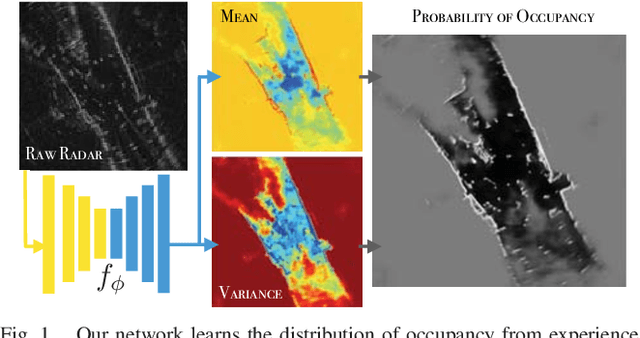

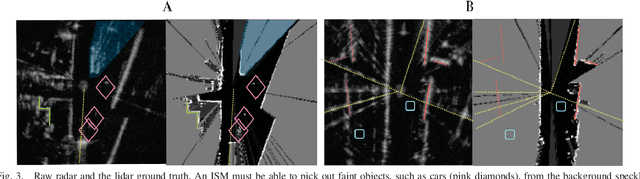
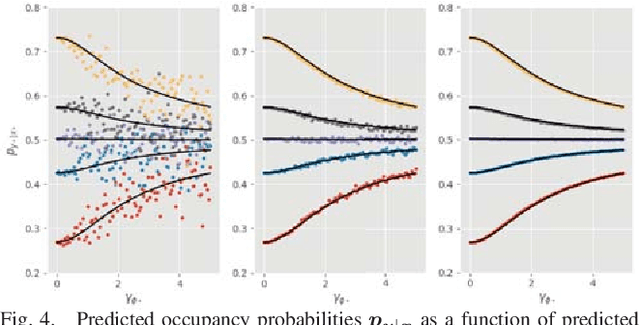
Radar presents a promising alternative to lidar and vision in autonomous vehicle applications, being able to detect objects at long range under a variety of weather conditions. However, distinguishing between occupied and free space from a raw radar scan is notoriously difficult. We consider the challenge of learning an Inverse Sensor Model (ISM) mapping a raw radar observation to occupancy probabilities in a discretised space. We frame this problem as a segmentation task, utilising a deep neural network that is able to learn an inherently probabilistic ISM from raw sensor data considers scene context. In doing so our approach explicitly accounts for the heteroscedastic aleatoric uncertainty for radar that arises due to complex interactions between occlusion and sensor noise. Our network is trained using only partial occupancy labels generated from lidar and able to successfully distinguish between occupied and free space. We evaluate our approach on five hours of data recorded in a dynamic urban environment and show that it significantly outperforms classical constant false-alarm rate (CFAR) filtering approaches in light of challenging noise artefacts whilst identifying space that is inherently uncertain because of occlusion.
Listening for Sirens: Locating and Classifying Acoustic Alarms in City Scenes
Oct 11, 2018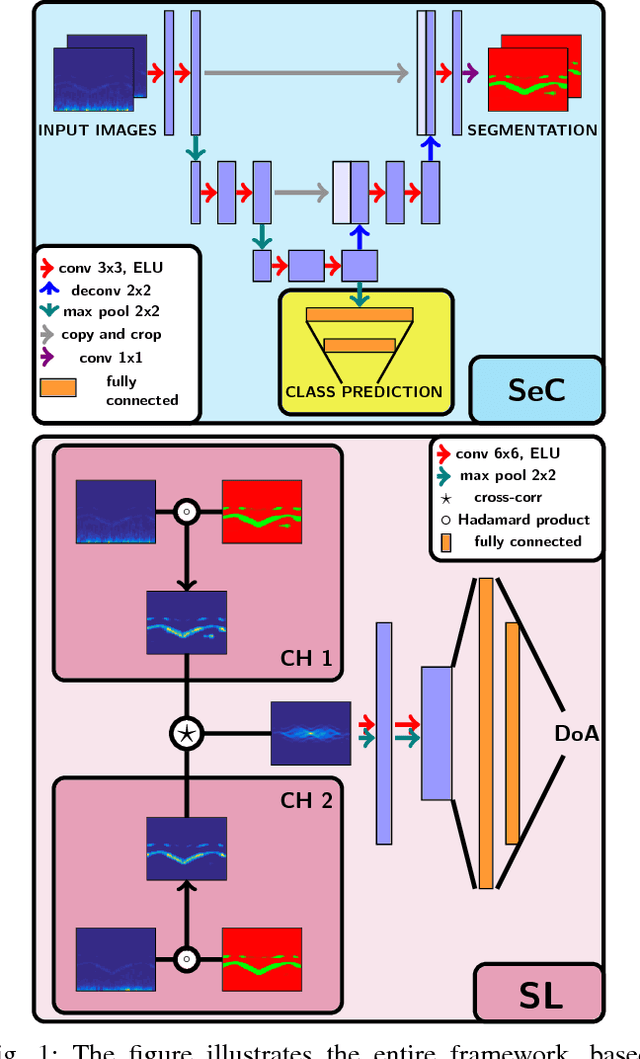

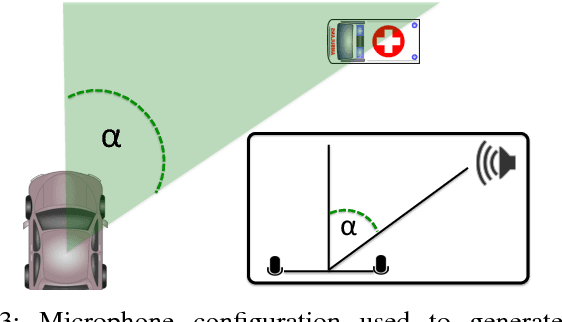
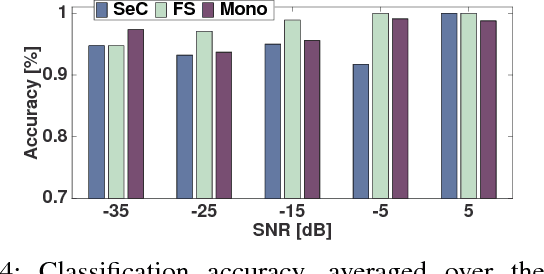
This paper is about alerting acoustic event detection and sound source localisation in an urban scenario. Specifically, we are interested in spotting the presence of horns, and sirens of emergency vehicles. In order to obtain a reliable system able to operate robustly despite the presence of traffic noise, which can be copious, unstructured and unpredictable, we propose to treat the spectrograms of incoming stereo signals as images, and apply semantic segmentation, based on a Unet architecture, to extract the target sound from the background noise. In a multi-task learning scheme, together with signal denoising, we perform acoustic event classification to identify the nature of the alerting sound. Lastly, we use the denoised signals to localise the acoustic source on the horizon plane, by regressing the direction of arrival of the sound through a CNN architecture. Our experimental evaluation shows an average classification rate of 94%, and a median absolute error on the localisation of 7.5{\deg} when operating on audio frames of 0.5s, and of 2.5{\deg} when operating on frames of 2.5s. The system offers excellent performance in particularly challenging scenarios, where the noise level is remarkably high.
Multimotion Visual Odometry (MVO): Simultaneous Estimation of Camera and Third-Party Motions
Aug 14, 2018
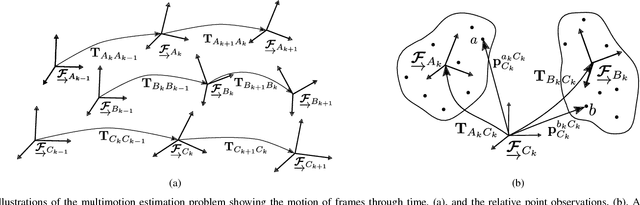

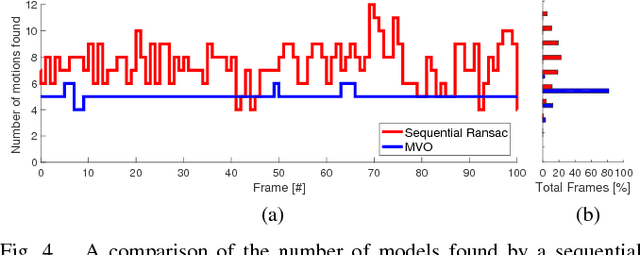
Estimating motion from images is a well-studied problem in computer vision and robotics. Previous work has developed techniques to estimate the motion of a moving camera in a largely static environment (e.g., visual odometry) and to segment or track motions in a dynamic scene using known camera motions (e.g., multiple object tracking). It is more challenging to estimate the unknown motion of the camera and the dynamic scene simultaneously. Most previous work requires a priori object models (e.g., tracking-by-detection), motion constraints (e.g., planar motion), or fails to estimate the full SE(3) motions of the scene (e.g., scene flow). While these approaches work well in specific application domains, they are not generalizable to unconstrained motions. This paper extends the traditional visual odometry (VO) pipeline to estimate the full SE(3) motion of both a stereo/RGB-D camera and the dynamic scene. This multimotion visual odometry (MVO) pipeline requires no a priori knowledge of the environment or the dynamic objects. Its performance is evaluated on a real-world dynamic dataset with ground truth for all motions from a motion capture system.
* This updated manuscript corrects the experimental results published in the proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS).. 8 Pages. 7 Figures. Video available at https://www.youtube.com/watch?v=84tXCJOlj00
Adversarial Training for Adverse Conditions: Robust Metric Localisation using Appearance Transfer
Mar 09, 2018

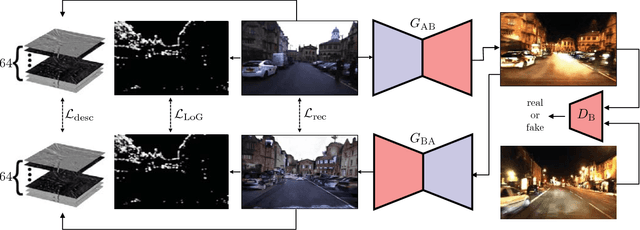

We present a method of improving visual place recognition and metric localisation under very strong appear- ance change. We learn an invertable generator that can trans- form the conditions of images, e.g. from day to night, summer to winter etc. This image transforming filter is explicitly designed to aid and abet feature-matching using a new loss based on SURF detector and dense descriptor maps. A network is trained to output synthetic images optimised for feature matching given only an input RGB image, and these generated images are used to localize the robot against a previously built map using traditional sparse matching approaches. We benchmark our results using multiple traversals of the Oxford RobotCar Dataset over a year-long period, using one traversal as a map and the other to localise. We show that this method significantly improves place recognition and localisation under changing and adverse conditions, while reducing the number of mapping runs needed to successfully achieve reliable localisation.
Surface Edge Explorer (SEE): Planning Next Best Views Directly from 3D Observations
Feb 23, 2018
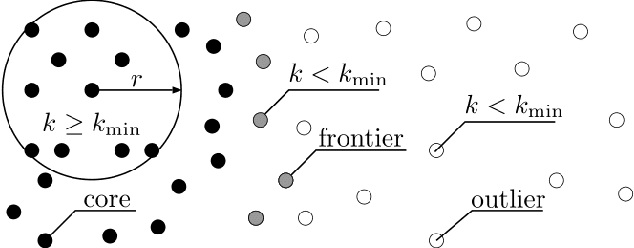
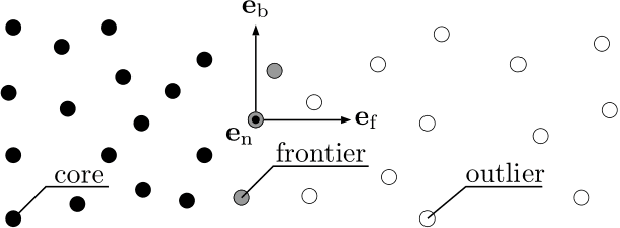
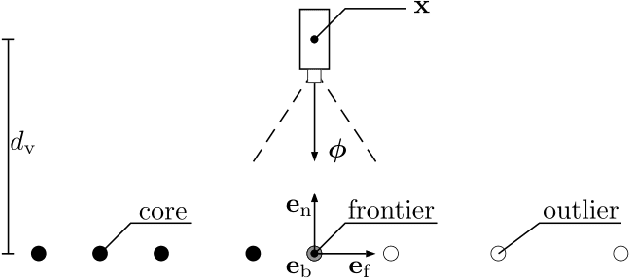
Surveying 3D scenes is a common task in robotics. Systems can do so autonomously by iteratively obtaining measurements. This process of planning observations to improve the model of a scene is called Next Best View (NBV) planning. NBV planning approaches often use either volumetric (e.g., voxel grids) or surface (e.g., triangulated meshes) representations. Volumetric approaches generalise well between scenes as they do not depend on surface geometry but do not scale to high-resolution models of large scenes. Surface representations can obtain high-resolution models at any scale but often require tuning of unintuitive parameters or multiple survey stages. This paper presents a scene-model-free NBV planning approach with a density representation. The Surface Edge Explorer (SEE) uses the density of current measurements to detect and explore observed surface boundaries. This approach is shown experimentally to provide better surface coverage in lower computation time than the evaluated state-of-the-art volumetric approaches while moving equivalent distances.
Meshed Up: Learnt Error Correction in 3D Reconstructions
Jan 27, 2018

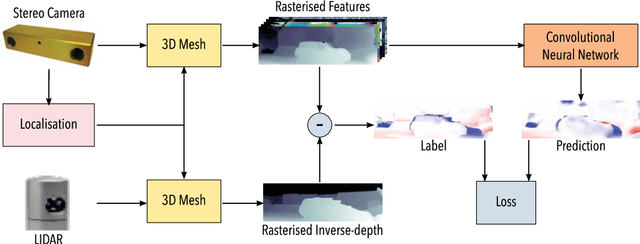
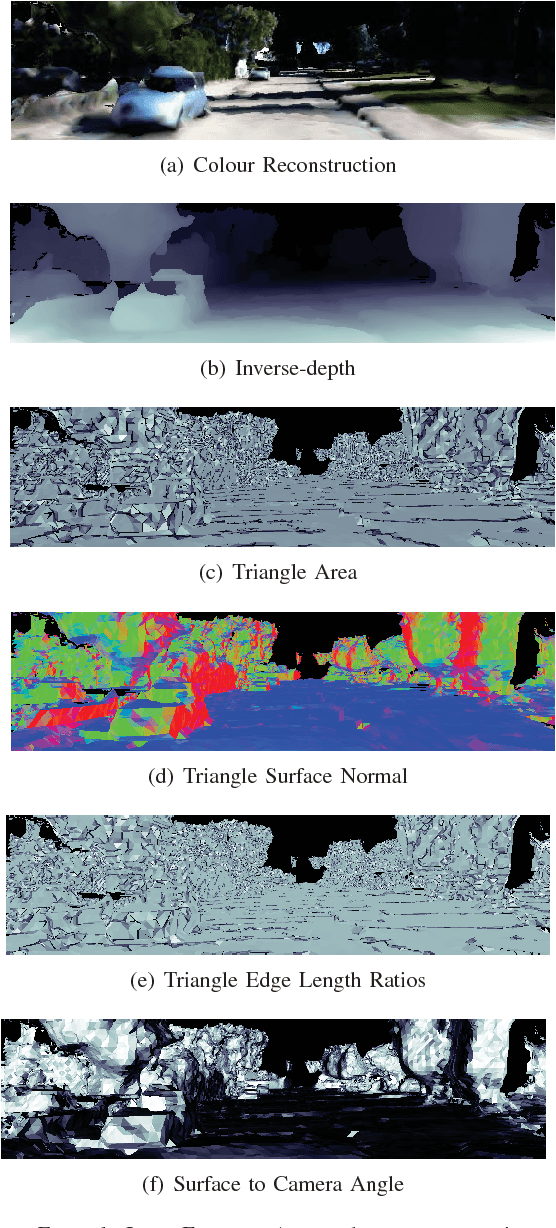
Dense reconstructions often contain errors that prior work has so far minimised using high quality sensors and regularising the output. Nevertheless, errors still persist. This paper proposes a machine learning technique to identify errors in three dimensional (3D) meshes. Beyond simply identifying errors, our method quantifies both the magnitude and the direction of depth estimate errors when viewing the scene. This enables us to improve the reconstruction accuracy. We train a suitably deep network architecture with two 3D meshes: a high-quality laser reconstruction, and a lower quality stereo image reconstruction. The network predicts the amount of error in the lower quality reconstruction with respect to the high-quality one, having only view the former through its input. We evaluate our approach by correcting two-dimensional (2D) inverse-depth images extracted from the 3D model, and show that our method improves the quality of these depth reconstructions by up to a relative 10% RMSE.