 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio Editing with Non-Rigid Text Prompts
Oct 19, 2023In this paper, we explore audio-editing with non-rigid text edits. We show that the proposed editing pipeline is able to create audio edits that remain faithful to the input audio. We explore text prompts that perform addition, style transfer, and in-painting. We quantitatively and qualitatively show that the edits are able to obtain results which outperform Audio-LDM, a recently released text-prompted audio generation model. Qualitative inspection of the results points out that the edits given by our approach remain more faithful to the input audio in terms of keeping the original onsets and offsets of the audio events.
Mechatronic Generation of Datasets for Acoustics Research
Oct 01, 2023We address the challenge of making spatial audio datasets by proposing a shared mechanized recording space that can run custom acoustic experiments: a Mechatronic Acoustic Research System (MARS). To accommodate a wide variety of experiments, we implement an extensible architecture for wireless multi-robot coordination which enables synchronized robot motion for dynamic scenes with moving speakers and microphones. Using a virtual control interface, we can remotely design automated experiments to collect large-scale audio data. This data is shown to be similar across repeated runs, demonstrating the reliability of MARS. We discuss the potential for MARS to make audio data collection accessible for researchers without dedicated acoustic research spaces.
Noise-Robust DSP-Assisted Neural Pitch Estimation with Very Low Complexity
Sep 25, 2023Pitch estimation is an essential step of many speech processing algorithms, including speech coding, synthesis, and enhancement. Recently, pitch estimators based on deep neural networks (DNNs) have have been outperforming well-established DSP-based techniques. Unfortunately, these new estimators can be impractical to deploy in real-time systems, both because of their relatively high complexity, and the fact that some require significant lookahead. We show that a hybrid estimator using a small deep neural network (DNN) with traditional DSP-based features can match or exceed the performance of pure DNN-based models, with a complexity and algorithmic delay comparable to traditional DSP-based algorithms. We further demonstrate that this hybrid approach can provide benefits for a neural vocoding task.
Complete and separate: Conditional separation with missing target source attribute completion
Jul 27, 2023



Recent approaches in source separation leverage semantic information about their input mixtures and constituent sources that when used in conditional separation models can achieve impressive performance. Most approaches along these lines have focused on simple descriptions, which are not always useful for varying types of input mixtures. In this work, we present an approach in which a model, given an input mixture and partial semantic information about a target source, is trained to extract additional semantic data. We then leverage this pre-trained model to improve the separation performance of an uncoupled multi-conditional separation network. Our experiments demonstrate that the separation performance of this multi-conditional model is significantly improved, approaching the performance of an oracle model with complete semantic information. Furthermore, our approach achieves performance levels that are comparable to those of the best performing specialized single conditional models, thus providing an easier to use alternative.
Unsupervised Improvement of Audio-Text Cross-Modal Representations
May 05, 2023Recent advances in using language models to obtain cross-modal audio-text representations have overcome the limitations of conventional training approaches that use predefined labels. This has allowed the community to make progress in tasks like zero-shot classification, which would otherwise not be possible. However, learning such representations requires a large amount of human-annotated audio-text pairs. In this paper, we study unsupervised approaches to improve the learning framework of such representations with unpaired text and audio. We explore domain-unspecific and domain-specific curation methods to create audio-text pairs that we use to further improve the model. We also show that when domain-specific curation is used in conjunction with a soft-labeled contrastive loss, we are able to obtain significant improvement in terms of zero-shot classification performance on downstream sound event classification or acoustic scene classification tasks.
A Framework for Unified Real-time Personalized and Non-Personalized Speech Enhancement
Feb 23, 2023



In this study, we present an approach to train a single speech enhancement network that can perform both personalized and non-personalized speech enhancement. This is achieved by incorporating a frame-wise conditioning input that specifies the type of enhancement output. To improve the quality of the enhanced output and mitigate oversuppression, we experiment with re-weighting frames by the presence or absence of speech activity and applying augmentations to speaker embeddings. By training under a multi-task learning setting, we empirically show that the proposed unified model obtains promising results on both personalized and non-personalized speech enhancement benchmarks and reaches similar performance to models that are trained specialized for either task. The strong performance of the proposed method demonstrates that the unified model is a more economical alternative compared to keeping separate task-specific models during inference.
Framewise WaveGAN: High Speed Adversarial Vocoder in Time Domain with Very Low Computational Complexity
Dec 08, 2022GAN vocoders are currently one of the state-of-the-art methods for building high-quality neural waveform generative models. However, most of their architectures require dozens of billion floating-point operations per second (GFLOPS) to generate speech waveforms in samplewise manner. This makes GAN vocoders still challenging to run on normal CPUs without accelerators or parallel computers. In this work, we propose a new architecture for GAN vocoders that mainly depends on recurrent and fully-connected networks to directly generate the time domain signal in framewise manner. This results in considerable reduction of the computational cost and enables very fast generation on both GPUs and low-complexity CPUs. Experimental results show that our Framewise WaveGAN vocoder achieves significantly higher quality than auto-regressive maximum-likelihood vocoders such as LPCNet at a very low complexity of 1.2 GFLOPS. This makes GAN vocoders more practical on edge and low-power devices.
Latent Iterative Refinement for Modular Source Separation
Nov 22, 2022Traditional source separation approaches train deep neural network models end-to-end with all the data available at once by minimizing the empirical risk on the whole training set. On the inference side, after training the model, the user fetches a static computation graph and runs the full model on some specified observed mixture signal to get the estimated source signals. Additionally, many of those models consist of several basic processing blocks which are applied sequentially. We argue that we can significantly increase resource efficiency during both training and inference stages by reformulating a model's training and inference procedures as iterative mappings of latent signal representations. First, we can apply the same processing block more than once on its output to refine the input signal and consequently improve parameter efficiency. During training, we can follow a block-wise procedure which enables a reduction on memory requirements. Thus, one can train a very complicated network structure using significantly less computation compared to end-to-end training. During inference, we can dynamically adjust how many processing blocks and iterations of a specific block an input signal needs using a gating module.
Optimal Condition Training for Target Source Separation
Nov 11, 2022


Recent research has shown remarkable performance in leveraging multiple extraneous conditional and non-mutually exclusive semantic concepts for sound source separation, allowing the flexibility to extract a given target source based on multiple different queries. In this work, we propose a new optimal condition training (OCT) method for single-channel target source separation, based on greedy parameter updates using the highest performing condition among equivalent conditions associated with a given target source. Our experiments show that the complementary information carried by the diverse semantic concepts significantly helps to disentangle and isolate sources of interest much more efficiently compared to single-conditioned models. Moreover, we propose a variation of OCT with condition refinement, in which an initial conditional vector is adapted to the given mixture and transformed to a more amenable representation for target source extraction. We showcase the effectiveness of OCT on diverse source separation experiments where it improves upon permutation invariant models with oracle assignment and obtains state-of-the-art performance in the more challenging task of text-based source separation, outperforming even dedicated text-only conditioned models.
Meta-Learning for Adaptive Filters with Higher-Order Frequency Dependencies
Sep 20, 2022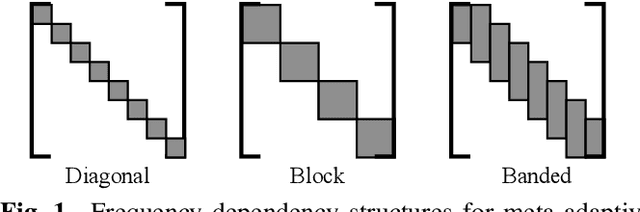
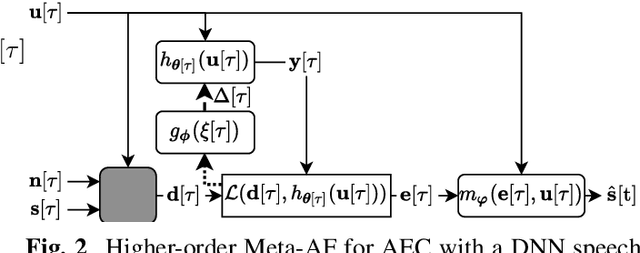
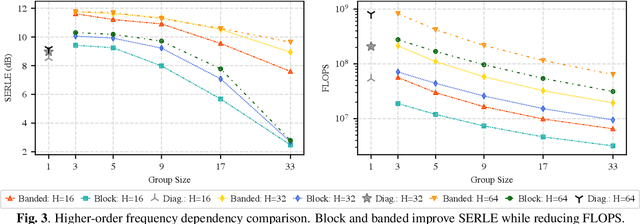
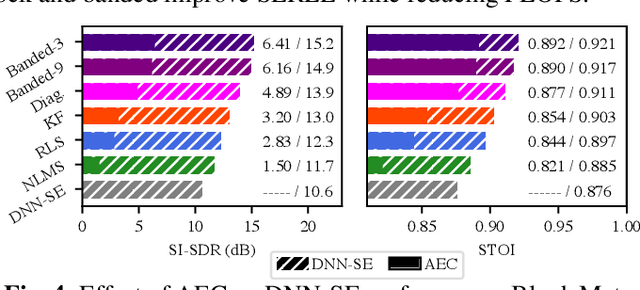
Adaptive filters are applicable to many signal processing tasks including acoustic echo cancellation, beamforming, and more. Adaptive filters are typically controlled using algorithms such as least-mean squares(LMS), recursive least squares(RLS), or Kalman filter updates. Such models are often applied in the frequency domain, assume frequency independent processing, and do not exploit higher-order frequency dependencies, for simplicity. Recent work on meta-adaptive filters, however, has shown that we can control filter adaptation using neural networks without manual derivation, motivating new work to exploit such information. In this work, we present higher-order meta-adaptive filters, a key improvement to meta-adaptive filters that incorporates higher-order frequency dependencies. We demonstrate our approach on acoustic echo cancellation and develop a family of filters that yield multi-dB improvements over competitive baselines, and are at least an order-of-magnitude less complex. Moreover, we show our improvements hold with or without a downstream speech enhancer.