 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Scene Graph Anticipation
Mar 07, 2024Spatio-temporal scene graphs represent interactions in a video by decomposing scenes into individual objects and their pair-wise temporal relationships. Long-term anticipation of the fine-grained pair-wise relationships between objects is a challenging problem. To this end, we introduce the task of Scene Graph Anticipation (SGA). We adapt state-of-the-art scene graph generation methods as baselines to anticipate future pair-wise relationships between objects and propose a novel approach SceneSayer. In SceneSayer, we leverage object-centric representations of relationships to reason about the observed video frames and model the evolution of relationships between objects. We take a continuous time perspective and model the latent dynamics of the evolution of object interactions using concepts of NeuralODE and NeuralSDE, respectively. We infer representations of future relationships by solving an Ordinary Differential Equation and a Stochastic Differential Equation, respectively. Extensive experimentation on the Action Genome dataset validates the efficacy of the proposed methods.
PuzzleBench: Can LLMs Solve Challenging First-Order Combinatorial Reasoning Problems?
Feb 04, 2024



Recent works have explored the use of LLMs for reasoning tasks focussing on relatively simple problems, such as logical question answering. In our work, we wish to tackle more complicated problems, significantly expanding the capabilities of these models. Particularly, we explore whether LLMs can solve challenging first-order combinatorial reasoning problems, an example being the popular puzzle Sudoku. These problems have an underlying first-order structure described by a general description in natural language and can be instantiated to instances of varying sizes. Moreover these problems are computationally intensive requiring several reasoning steps to reach the solution. We present PuzzleBench a dataset of 31 such challenging puzzles. We observe that LLMs even when aided by symbolic solvers perform rather poorly on our benchmark. In response we propose a new approach, Puzzle-LM which combines LLMs with both symbolic solvers and program interpreters enabling them to reason about such challenging problems. We also show how feedback from smaller solved instances can help improve this reasoning ability.
Ensembling Textual and Structure-Based Models for Knowledge Graph Completion
Nov 07, 2023



We consider two popular approaches to Knowledge Graph Completion (KGC): textual models that rely on textual entity descriptions, and structure-based models that exploit the connectivity structure of the Knowledge Graph (KG). Preliminary experiments show that these approaches have complementary strengths: structure-based models perform well when the gold answer is easily reachable from the query head in the KG, while textual models exploit descriptions to give good performance even when the gold answer is not reachable. In response, we explore ensembling as a way of combining the best of both approaches. We propose a novel method for learning query-dependent ensemble weights by using the distributions of scores assigned by individual models to all candidate entities. Our ensemble baseline achieves state-of-the-art results on three standard KGC datasets, with up to 6.8 pt MRR and 8.3 pt Hits@1 gains over best individual models.
ZGUL: Zero-shot Generalization to Unseen Languages using Multi-source Ensembling of Language Adapters
Oct 25, 2023



We tackle the problem of zero-shot cross-lingual transfer in NLP tasks via the use of language adapters (LAs). Most of the earlier works have explored training with adapter of a single source (often English), and testing either using the target LA or LA of another related language. Training target LA requires unlabeled data, which may not be readily available for low resource unseen languages: those that are neither seen by the underlying multilingual language model (e.g., mBERT), nor do we have any (labeled or unlabeled) data for them. We posit that for more effective cross-lingual transfer, instead of just one source LA, we need to leverage LAs of multiple (linguistically or geographically related) source languages, both at train and test-time - which we investigate via our novel neural architecture, ZGUL. Extensive experimentation across four language groups, covering 15 unseen target languages, demonstrates improvements of up to 3.2 average F1 points over standard fine-tuning and other strong baselines on POS tagging and NER tasks. We also extend ZGUL to settings where either (1) some unlabeled data or (2) few-shot training examples are available for the target language. We find that ZGUL continues to outperform baselines in these settings too.
Towards Fair and Calibrated Models
Oct 16, 2023Recent literature has seen a significant focus on building machine learning models with specific properties such as fairness, i.e., being non-biased with respect to a given set of attributes, calibration i.e., model confidence being aligned with its predictive accuracy, and explainability, i.e., ability to be understandable to humans. While there has been work focusing on each of these aspects individually, researchers have shied away from simultaneously addressing more than one of these dimensions. In this work, we address the problem of building models which are both fair and calibrated. We work with a specific definition of fairness, which closely matches [Biswas et. al. 2019], and has the nice property that Bayes optimal classifier has the maximum possible fairness under our definition. We show that an existing negative result towards achieving a fair and calibrated model [Kleinberg et. al. 2017] does not hold for our definition of fairness. Further, we show that ensuring group-wise calibration with respect to the sensitive attributes automatically results in a fair model under our definition. Using this result, we provide a first cut approach for achieving fair and calibrated models, via a simple post-processing technique based on temperature scaling. We then propose modifications of existing calibration losses to perform group-wise calibration, as a way of achieving fair and calibrated models in a variety of settings. Finally, we perform extensive experimentation of these techniques on a diverse benchmark of datasets, and present insights on the pareto-optimality of the resulting solutions.
Fill in the Blank: Exploring and Enhancing LLM Capabilities for Backward Reasoning in Math Word Problems
Oct 03, 2023



While forward reasoning (i.e. find the answer given the question) has been explored extensively in the recent literature, backward reasoning is relatively unexplored. We examine the backward reasoning capabilities of LLMs on Math Word Problems (MWPs): given a mathematical question and its answer, with some details omitted from the question, can LLMs effectively retrieve the missing information? In this paper, we formally define the backward reasoning task on math word problems and modify three datasets to evaluate this task: GSM8k, SVAMP and MultiArith. Our findings show a significant drop in the accuracy of models on backward reasoning compared to forward reasoning across four SOTA LLMs (GPT4, GPT3.5, PaLM-2, and LLaMa-2). Utilizing the specific format of this task, we propose three novel techniques that improve performance: Rephrase reformulates the given problem into a forward reasoning problem, PAL-Tools combines the idea of Program-Aided LLMs to produce a set of equations that can be solved by an external solver, and Check your Work exploits the availability of natural verifier of high accuracy in the forward direction, interleaving solving and verification steps. Finally, realizing that each of our base methods correctly solves a different set of problems, we propose a novel Bayesian formulation for creating an ensemble over these base methods aided by a verifier to further boost the accuracy by a significant margin. Extensive experimentation demonstrates that our techniques successively improve the performance of LLMs on the backward reasoning task, with the final ensemble-based method resulting in a substantial performance gain compared to the raw LLMs with standard prompting techniques such as chain-of-thought.
Image Manipulation via Multi-Hop Instructions -- A New Dataset and Weakly-Supervised Neuro-Symbolic Approach
May 23, 2023



We are interested in image manipulation via natural language text -- a task that is useful for multiple AI applications but requires complex reasoning over multi-modal spaces. We extend recently proposed Neuro Symbolic Concept Learning (NSCL), which has been quite effective for the task of Visual Question Answering (VQA), for the task of image manipulation. Our system referred to as NeuroSIM can perform complex multi-hop reasoning over multi-object scenes and only requires weak supervision in the form of annotated data for VQA. NeuroSIM parses an instruction into a symbolic program, based on a Domain Specific Language (DSL) comprising of object attributes and manipulation operations, that guides its execution. We create a new dataset for the task, and extensive experiments demonstrate that NeuroSIM is highly competitive with or beats SOTA baselines that make use of supervised data for manipulation.
Learning Neuro-symbolic Programs for Language Guided Robot Manipulation
Nov 12, 2022



Given a natural language instruction, and an input and an output scene, our goal is to train a neuro-symbolic model which can output a manipulation program that can be executed by the robot on the input scene resulting in the desired output scene. Prior approaches for this task possess one of the following limitations: (i) rely on hand-coded symbols for concepts limiting generalization beyond those seen during training [1] (ii) infer action sequences from instructions but require dense sub-goal supervision [2] or (iii) lack semantics required for deeper object-centric reasoning inherent in interpreting complex instructions [3]. In contrast, our approach is neuro-symbolic and can handle linguistic as well as perceptual variations, is end-to-end differentiable requiring no intermediate supervision, and makes use of symbolic reasoning constructs which operate on a latent neural object-centric representation, allowing for deeper reasoning over the input scene. Central to our approach is a modular structure, consisting of a hierarchical instruction parser, and a manipulation module to learn disentangled action representations, both trained via RL. Our experiments on a simulated environment with a 7-DOF manipulator, consisting of instructions with varying number of steps, as well as scenes with different number of objects, and objects with unseen attribute combinations, demonstrate that our model is robust to such variations, and significantly outperforms existing baselines, particularly in generalization settings.
A Solver-Free Framework for Scalable Learning in Neural ILP Architectures
Oct 17, 2022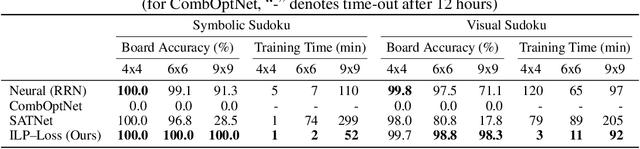
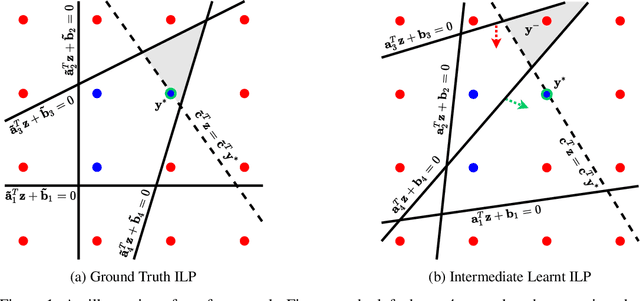
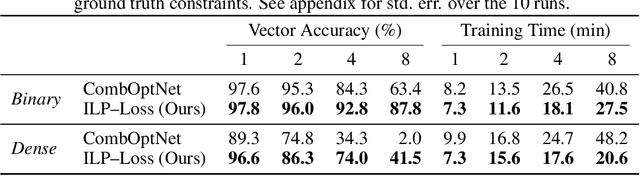

There is a recent focus on designing architectures that have an Integer Linear Programming (ILP) layer within a neural model (referred to as Neural ILP in this paper). Neural ILP architectures are suitable for pure reasoning tasks that require data-driven constraint learning or for tasks requiring both perception (neural) and reasoning (ILP). A recent SOTA approach for end-to-end training of Neural ILP explicitly defines gradients through the ILP black box (Paulus et al. 2021) - this trains extremely slowly, owing to a call to the underlying ILP solver for every training data point in a minibatch. In response, we present an alternative training strategy that is solver-free, i.e., does not call the ILP solver at all at training time. Neural ILP has a set of trainable hyperplanes (for cost and constraints in ILP), together representing a polyhedron. Our key idea is that the training loss should impose that the final polyhedron separates the positives (all constraints satisfied) from the negatives (at least one violated constraint or a suboptimal cost value), via a soft-margin formulation. While positive example(s) are provided as part of the training data, we devise novel techniques for generating negative samples. Our solution is flexible enough to handle equality as well as inequality constraints. Experiments on several problems, both perceptual as well as symbolic, which require learning the constraints of an ILP, show that our approach has superior performance and scales much better compared to purely neural baselines and other state-of-the-art models that require solver-based training. In particular, we are able to obtain excellent performance in 9 x 9 symbolic and visual sudoku, to which the other Neural ILP solver is not able to scale.
Neural Models for Output-Space Invariance in Combinatorial Problems
Feb 07, 2022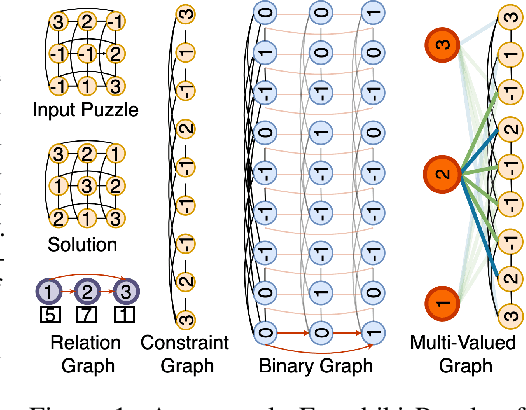
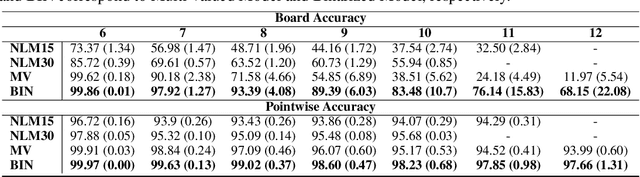
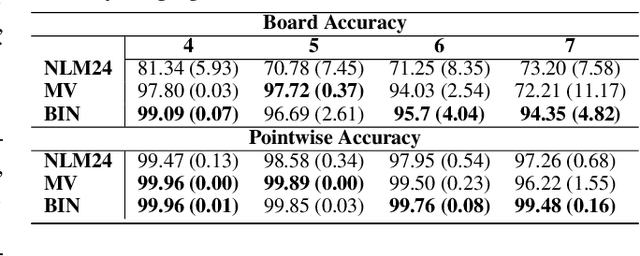
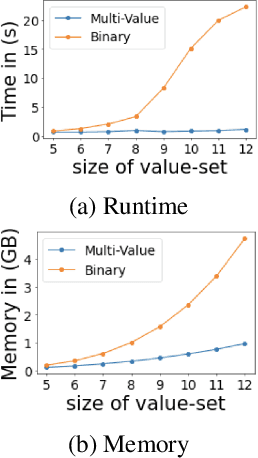
Recently many neural models have been proposed to solve combinatorial puzzles by implicitly learning underlying constraints using their solved instances, such as sudoku or graph coloring (GCP). One drawback of the proposed architectures, which are often based on Graph Neural Networks (GNN), is that they cannot generalize across the size of the output space from which variables are assigned a value, for example, set of colors in a GCP, or board-size in sudoku. We call the output space for the variables as 'value-set'. While many works have demonstrated generalization of GNNs across graph size, there has been no study on how to design a GNN for achieving value-set invariance for problems that come from the same domain. For example, learning to solve 16 x 16 sudoku after being trained on only 9 x 9 sudokus. In this work, we propose novel methods to extend GNN based architectures to achieve value-set invariance. Specifically, our model builds on recently proposed Recurrent Relational Networks. Our first approach exploits the graph-size invariance of GNNs by converting a multi-class node classification problem into a binary node classification problem. Our second approach works directly with multiple classes by adding multiple nodes corresponding to the values in the value-set, and then connecting variable nodes to value nodes depending on the problem initialization. Our experimental evaluation on three different combinatorial problems demonstrates that both our models perform well on our novel problem, compared to a generic neural reasoner. Between two of our models, we observe an inherent trade-off: while the binarized model gives better performance when trained on smaller value-sets, multi-valued model is much more memory efficient, resulting in improved performance when trained on larger value-sets, where binarized model fails to train.