 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Regularize or Not To Regularize? The Bias Variance Trade-off in Regularized AEs
Paper and Code
Jun 10, 2020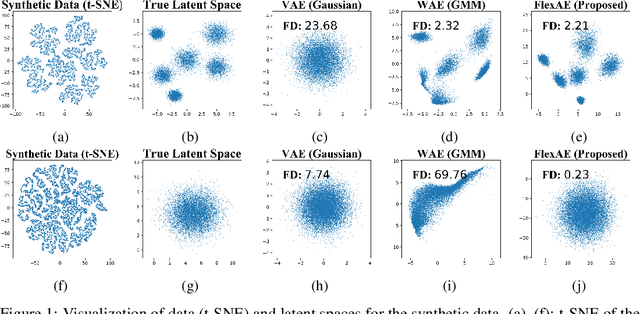
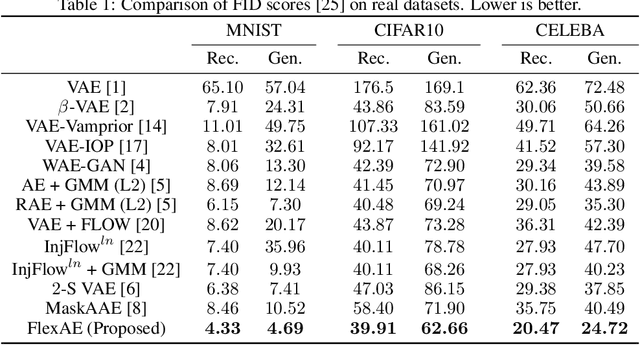
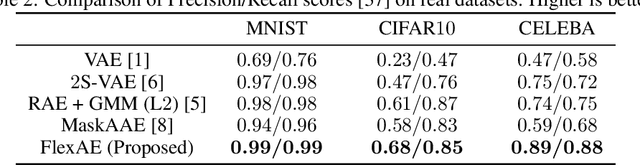

Regularized Auto-Encoders (AE) form a rich class of methods within the landscape of neural generative models. They effectively model the joint-distribution between the data and a latent space using an Encoder-Decoder combination, with regularization imposed in terms of a prior over the latent space. Despite their advantages such as stability in training, the performance of AE based models has not reached that of the other models such as GANs. While several reasons including the presence of conflicting terms in the objective, distributional choices imposed on the Encoder and the Decoder, and dimensionality of the latent space have been identified as possible causes for the suboptimal performance, the role of the regularization (prior distribution) imposed has not been studied systematically. Motivated by this, we examine the effect of the latent prior on the generation quality of the AE models in this paper. We show that there is no single fixed prior which is optimal for all data distributions, given a Gaussian Decoder. Further, with finite data, we show that there exists a bias-variance trade-off that comes with prior imposition. As a remedy, we optimize a generalized ELBO objective, with an additional state space over the latent prior. We implicitly learn this flexible prior jointly with the AE training using an adversarial learning technique, which facilitates operation on different points of the bias-variance curve. Our experiments on multiple datasets show that the proposed method is the new state-of-the-art for AE based generative models.