 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToxic language detection: a systematic survey of Arabic datasets
Dec 12, 2023This paper offers a comprehensive survey of Arabic datasets focused on online toxic language. We systematically gathered a total of 49 available datasets and their corresponding papers and conducted a thorough analysis, considering 16 criteria across three primary dimensions: content, annotation process, and reusability. This analysis enabled us to identify existing gaps and make recommendations for future research works.
Vicinal Risk Minimization for Few-Shot Cross-lingual Transfer in Abusive Language Detection
Nov 03, 2023Cross-lingual transfer learning from high-resource to medium and low-resource languages has shown encouraging results. However, the scarcity of resources in target languages remains a challenge. In this work, we resort to data augmentation and continual pre-training for domain adaptation to improve cross-lingual abusive language detection. For data augmentation, we analyze two existing techniques based on vicinal risk minimization and propose MIXAG, a novel data augmentation method which interpolates pairs of instances based on the angle of their representations. Our experiments involve seven languages typologically distinct from English and three different domains. The results reveal that the data augmentation strategies can enhance few-shot cross-lingual abusive language detection. Specifically, we observe that consistently in all target languages, MIXAG improves significantly in multidomain and multilingual environments. Finally, we show through an error analysis how the domain adaptation can favour the class of abusive texts (reducing false negatives), but at the same time, declines the precision of the abusive language detection model.
Overview of AuTexTification at IberLEF 2023: Detection and Attribution of Machine-Generated Text in Multiple Domains
Sep 20, 2023This paper presents the overview of the AuTexTification shared task as part of the IberLEF 2023 Workshop in Iberian Languages Evaluation Forum, within the framework of the SEPLN 2023 conference. AuTexTification consists of two subtasks: for Subtask 1, participants had to determine whether a text is human-authored or has been generated by a large language model. For Subtask 2, participants had to attribute a machine-generated text to one of six different text generation models. Our AuTexTification 2023 dataset contains more than 160.000 texts across two languages (English and Spanish) and five domains (tweets, reviews, news, legal, and how-to articles). A total of 114 teams signed up to participate, of which 36 sent 175 runs, and 20 of them sent their working notes. In this overview, we present the AuTexTification dataset and task, the submitted participating systems, and the results.
Mitigating Negative Transfer with Task Awareness for Sexism, Hate Speech, and Toxic Language Detection
Jul 07, 2023This paper proposes a novelty approach to mitigate the negative transfer problem. In the field of machine learning, the common strategy is to apply the Single-Task Learning approach in order to train a supervised model to solve a specific task. Training a robust model requires a lot of data and a significant amount of computational resources, making this solution unfeasible in cases where data are unavailable or expensive to gather. Therefore another solution, based on the sharing of information between tasks, has been developed: Multi-Task Learning (MTL). Despite the recent developments regarding MTL, the problem of negative transfer has still to be solved. Negative transfer is a phenomenon that occurs when noisy information is shared between tasks, resulting in a drop in performance. This paper proposes a new approach to mitigate the negative transfer problem based on the task awareness concept. The proposed approach results in diminishing the negative transfer together with an improvement of performance over classic MTL solution. Moreover, the proposed approach has been implemented in two unified architectures to detect Sexism, Hate Speech, and Toxic Language in text comments. The proposed architectures set a new state-of-the-art both in EXIST-2021 and HatEval-2019 benchmarks.
Transformers and Ensemble methods: A solution for Hate Speech Detection in Arabic languages
Mar 17, 2023


This paper describes our participation in the shared task of hate speech detection, which is one of the subtasks of the CERIST NLP Challenge 2022. Our experiments evaluate the performance of six transformer models and their combination using 2 ensemble approaches. The best results on the training set, in a five-fold cross validation scenario, were obtained by using the ensemble approach based on the majority vote. The evaluation of this approach on the test set resulted in an F1-score of 0.60 and an Accuracy of 0.86.
It's Just a Matter of Time: Detecting Depression with Time-Enriched Multimodal Transformers
Jan 13, 2023Depression detection from user-generated content on the internet has been a long-lasting topic of interest in the research community, providing valuable screening tools for psychologists. The ubiquitous use of social media platforms lays out the perfect avenue for exploring mental health manifestations in posts and interactions with other users. Current methods for depression detection from social media mainly focus on text processing, and only a few also utilize images posted by users. In this work, we propose a flexible time-enriched multimodal transformer architecture for detecting depression from social media posts, using pretrained models for extracting image and text embeddings. Our model operates directly at the user-level, and we enrich it with the relative time between posts by using time2vec positional embeddings. Moreover, we propose another model variant, which can operate on randomly sampled and unordered sets of posts to be more robust to dataset noise. We show that our method, using EmoBERTa and CLIP embeddings, surpasses other methods on two multimodal datasets, obtaining state-of-the-art results of 0.931 F1 score on a popular multimodal Twitter dataset, and 0.902 F1 score on the only multimodal Reddit dataset.
Multilingual Detection of Check-Worthy Claims using World Languages and Adapter Fusion
Jan 13, 2023Check-worthiness detection is the task of identifying claims, worthy to be investigated by fact-checkers. Resource scarcity for non-world languages and model learning costs remain major challenges for the creation of models supporting multilingual check-worthiness detection. This paper proposes cross-training adapters on a subset of world languages, combined by adapter fusion, to detect claims emerging globally in multiple languages. (1) With a vast number of annotators available for world languages and the storage-efficient adapter models, this approach is more cost efficient. Models can be updated more frequently and thus stay up-to-date. (2) Adapter fusion provides insights and allows for interpretation regarding the influence of each adapter model on a particular language. The proposed solution often outperformed the top multilingual approaches in our benchmark tasks.
Fake News and Hate Speech: Language in Common
Dec 05, 2022In this paper we raise the research question of whether fake news and hate speech spreaders share common patterns in language. We compute a novel index, the ingroup vs outgroup index, in three different datasets and we show that both phenomena share an "us vs them" narrative.
UrduFake@FIRE2020: Shared Track on Fake News Identification in Urdu
Jul 25, 2022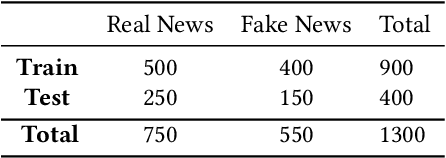

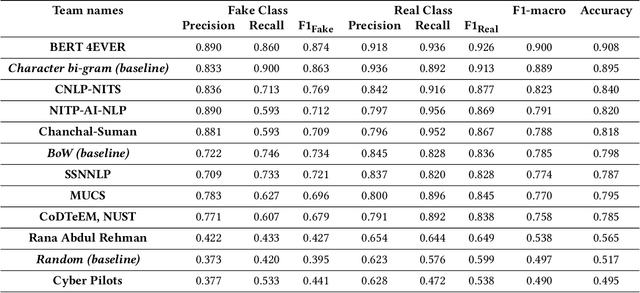
This paper gives the overview of the first shared task at FIRE 2020 on fake news detection in the Urdu language. This is a binary classification task in which the goal is to identify fake news using a dataset composed of 900 annotated news articles for training and 400 news articles for testing. The dataset contains news in five domains: (i) Health, (ii) Sports, (iii) Showbiz, (iv) Technology, and (v) Business. 42 teams from 6 different countries (India, China, Egypt, Germany, Pakistan, and the UK) registered for the task. 9 teams submitted their experimental results. The participants used various machine learning methods ranging from feature-based traditional machine learning to neural network techniques. The best performing system achieved an F-score value of 0.90, showing that the BERT-based approach outperforms other machine learning classifiers.
Overview of the Shared Task on Fake News Detection in Urdu at FIRE 2020
Jul 25, 2022
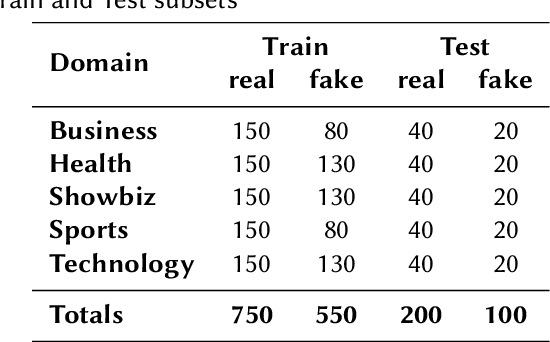
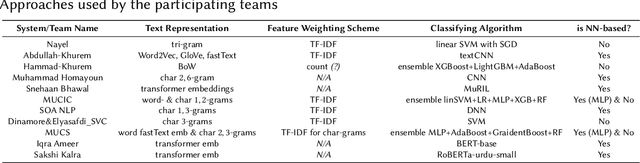
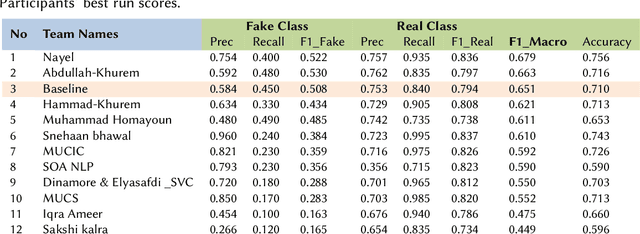
This overview paper describes the first shared task on fake news detection in Urdu language. The task was posed as a binary classification task, in which the goal is to differentiate between real and fake news. We provided a dataset divided into 900 annotated news articles for training and 400 news articles for testing. The dataset contained news in five domains: (i) Health, (ii) Sports, (iii) Showbiz, (iv) Technology, and (v) Business. 42 teams from 6 different countries (India, China, Egypt, Germany, Pakistan, and the UK) registered for the task. 9 teams submitted their experimental results. The participants used various machine learning methods ranging from feature-based traditional machine learning to neural networks techniques. The best performing system achieved an F-score value of 0.90, showing that the BERT-based approach outperforms other machine learning techniques