 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSource Verification for Speech Deepfakes
May 20, 2025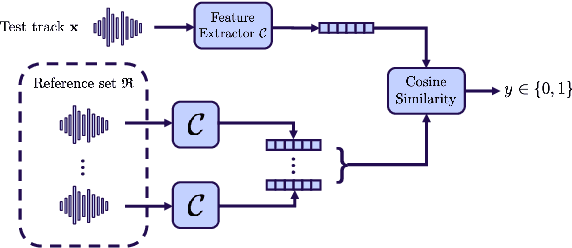
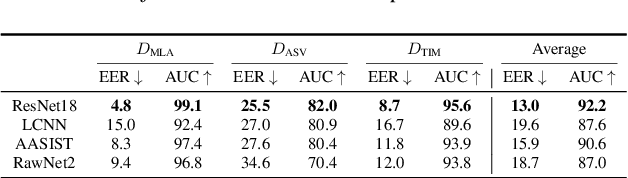
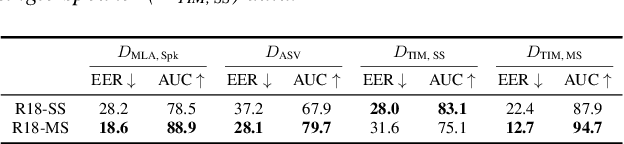
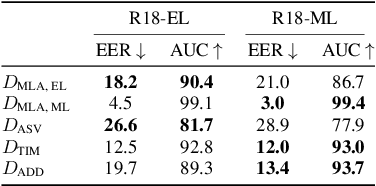
With the proliferation of speech deepfake generators, it becomes crucial not only to assess the authenticity of synthetic audio but also to trace its origin. While source attribution models attempt to address this challenge, they often struggle in open-set conditions against unseen generators. In this paper, we introduce the source verification task, which, inspired by speaker verification, determines whether a test track was produced using the same model as a set of reference signals. Our approach leverages embeddings from a classifier trained for source attribution, computing distance scores between tracks to assess whether they originate from the same source. We evaluate multiple models across diverse scenarios, analyzing the impact of speaker diversity, language mismatch, and post-processing operations. This work provides the first exploration of source verification, highlighting its potential and vulnerabilities, and offers insights for real-world forensic applications.
Comparative Analysis of ASR Methods for Speech Deepfake Detection
Nov 26, 2024



Recent techniques for speech deepfake detection often rely on pre-trained self-supervised models. These systems, initially developed for Automatic Speech Recognition (ASR), have proved their ability to offer a meaningful representation of speech signals, which can benefit various tasks, including deepfake detection. In this context, pre-trained models serve as feature extractors and are used to extract embeddings from input speech, which are then fed to a binary speech deepfake detector. The remarkable accuracy achieved through this approach underscores a potential relationship between ASR and speech deepfake detection. However, this connection is not yet entirely clear, and we do not know whether improved performance in ASR corresponds to higher speech deepfake detection capabilities. In this paper, we address this question through a systematic analysis. We consider two different pre-trained self-supervised ASR models, Whisper and Wav2Vec 2.0, and adapt them for the speech deepfake detection task. These models have been released in multiple versions, with increasing number of parameters and enhanced ASR performance. We investigate whether performance improvements in ASR correlate with improvements in speech deepfake detection. Our results provide insights into the relationship between these two tasks and offer valuable guidance for the development of more effective speech deepfake detectors.
POLIPHONE: A Dataset for Smartphone Model Identification from Audio Recordings
Oct 08, 2024When dealing with multimedia data, source attribution is a key challenge from a forensic perspective. This task aims to determine how a given content was captured, providing valuable insights for various applications, including legal proceedings and integrity investigations. The source attribution problem has been addressed in different domains, from identifying the camera model used to capture specific photographs to detecting the synthetic speech generator or microphone model used to create or record given audio tracks. Recent advancements in this area rely heavily on machine learning and data-driven techniques, which often outperform traditional signal processing-based methods. However, a drawback of these systems is their need for large volumes of training data, which must reflect the latest technological trends to produce accurate and reliable predictions. This presents a significant challenge, as the rapid pace of technological progress makes it difficult to maintain datasets that are up-to-date with real-world conditions. For instance, in the task of smartphone model identification from audio recordings, the available datasets are often outdated or acquired inconsistently, making it difficult to develop solutions that are valid beyond a research environment. In this paper we present POLIPHONE, a dataset for smartphone model identification from audio recordings. It includes data from 20 recent smartphones recorded in a controlled environment to ensure reproducibility and scalability for future research. The released tracks contain audio data from various domains (i.e., speech, music, environmental sounds), making the corpus versatile and applicable to a wide range of use cases. We also present numerous experiments to benchmark the proposed dataset using a state-of-the-art classifier for smartphone model identification from audio recordings.
Freeze and Learn: Continual Learning with Selective Freezing for Speech Deepfake Detection
Sep 26, 2024



In speech deepfake detection, one of the critical aspects is developing detectors able to generalize on unseen data and distinguish fake signals across different datasets. Common approaches to this challenge involve incorporating diverse data into the training process or fine-tuning models on unseen datasets. However, these solutions can be computationally demanding and may lead to the loss of knowledge acquired from previously learned data. Continual learning techniques offer a potential solution to this problem, allowing the models to learn from unseen data without losing what they have already learned. Still, the optimal way to apply these algorithms for speech deepfake detection remains unclear, and we do not know which is the best way to apply these algorithms to the developed models. In this paper we address this aspect and investigate whether, when retraining a speech deepfake detector, it is more effective to apply continual learning across the entire model or to update only some of its layers while freezing others. Our findings, validated across multiple models, indicate that the most effective approach among the analyzed ones is to update only the weights of the initial layers, which are responsible for processing the input features of the detector.
Leveraging Mixture of Experts for Improved Speech Deepfake Detection
Sep 24, 2024
Speech deepfakes pose a significant threat to personal security and content authenticity. Several detectors have been proposed in the literature, and one of the primary challenges these systems have to face is the generalization over unseen data to identify fake signals across a wide range of datasets. In this paper, we introduce a novel approach for enhancing speech deepfake detection performance using a Mixture of Experts architecture. The Mixture of Experts framework is well-suited for the speech deepfake detection task due to its ability to specialize in different input types and handle data variability efficiently. This approach offers superior generalization and adaptability to unseen data compared to traditional single models or ensemble methods. Additionally, its modular structure supports scalable updates, making it more flexible in managing the evolving complexity of deepfake techniques while maintaining high detection accuracy. We propose an efficient, lightweight gating mechanism to dynamically assign expert weights for each input, optimizing detection performance. Experimental results across multiple datasets demonstrate the effectiveness and potential of our proposed approach.
Analyzing the Impact of Splicing Artifacts in Partially Fake Speech Signals
Aug 25, 2024



Speech deepfake detection has recently gained significant attention within the multimedia forensics community. Related issues have also been explored, such as the identification of partially fake signals, i.e., tracks that include both real and fake speech segments. However, generating high-quality spliced audio is not as straightforward as it may appear. Spliced signals are typically created through basic signal concatenation. This process could introduce noticeable artifacts that can make the generated data easier to detect. We analyze spliced audio tracks resulting from signal concatenation, investigate their artifacts and assess whether such artifacts introduce any bias in existing datasets. Our findings reveal that by analyzing splicing artifacts, we can achieve a detection EER of 6.16% and 7.36% on PartialSpoof and HAD datasets, respectively, without needing to train any detector. These results underscore the complexities of generating reliable spliced audio data and lead to discussions that can help improve future research in this area.
Deepfake Media Forensics: State of the Art and Challenges Ahead
Aug 01, 2024AI-generated synthetic media, also called Deepfakes, have significantly influenced so many domains, from entertainment to cybersecurity. Generative Adversarial Networks (GANs) and Diffusion Models (DMs) are the main frameworks used to create Deepfakes, producing highly realistic yet fabricated content. While these technologies open up new creative possibilities, they also bring substantial ethical and security risks due to their potential misuse. The rise of such advanced media has led to the development of a cognitive bias known as Impostor Bias, where individuals doubt the authenticity of multimedia due to the awareness of AI's capabilities. As a result, Deepfake detection has become a vital area of research, focusing on identifying subtle inconsistencies and artifacts with machine learning techniques, especially Convolutional Neural Networks (CNNs). Research in forensic Deepfake technology encompasses five main areas: detection, attribution and recognition, passive authentication, detection in realistic scenarios, and active authentication. Each area tackles specific challenges, from tracing the origins of synthetic media and examining its inherent characteristics for authenticity. This paper reviews the primary algorithms that address these challenges, examining their advantages, limitations, and future prospects.
FairSSD: Understanding Bias in Synthetic Speech Detectors
Apr 17, 2024



Methods that can generate synthetic speech which is perceptually indistinguishable from speech recorded by a human speaker, are easily available. Several incidents report misuse of synthetic speech generated from these methods to commit fraud. To counter such misuse, many methods have been proposed to detect synthetic speech. Some of these detectors are more interpretable, can generalize to detect synthetic speech in the wild and are robust to noise. However, limited work has been done on understanding bias in these detectors. In this work, we examine bias in existing synthetic speech detectors to determine if they will unfairly target a particular gender, age and accent group. We also inspect whether these detectors will have a higher misclassification rate for bona fide speech from speech-impaired speakers w.r.t fluent speakers. Extensive experiments on 6 existing synthetic speech detectors using more than 0.9 million speech signals demonstrate that most detectors are gender, age and accent biased, and future work is needed to ensure fairness. To support future research, we release our evaluation dataset, models used in our study and source code at https://gitlab.com/viper-purdue/fairssd.
Listening Between the Lines: Synthetic Speech Detection Disregarding Verbal Content
Feb 08, 2024



Recent advancements in synthetic speech generation have led to the creation of forged audio data that are almost indistinguishable from real speech. This phenomenon poses a new challenge for the multimedia forensics community, as the misuse of synthetic media can potentially cause adverse consequences. Several methods have been proposed in the literature to mitigate potential risks and detect synthetic speech, mainly focusing on the analysis of the speech itself. However, recent studies have revealed that the most crucial frequency bands for detection lie in the highest ranges (above 6000 Hz), which do not include any speech content. In this work, we extensively explore this aspect and investigate whether synthetic speech detection can be performed by focusing only on the background component of the signal while disregarding its verbal content. Our findings indicate that the speech component is not the predominant factor in performing synthetic speech detection. These insights provide valuable guidance for the development of new synthetic speech detectors and their interpretability, together with some considerations on the existing work in the audio forensics field.
All-for-One and One-For-All: Deep learning-based feature fusion for Synthetic Speech Detection
Jul 28, 2023



Recent advances in deep learning and computer vision have made the synthesis and counterfeiting of multimedia content more accessible than ever, leading to possible threats and dangers from malicious users. In the audio field, we are witnessing the growth of speech deepfake generation techniques, which solicit the development of synthetic speech detection algorithms to counter possible mischievous uses such as frauds or identity thefts. In this paper, we consider three different feature sets proposed in the literature for the synthetic speech detection task and present a model that fuses them, achieving overall better performances with respect to the state-of-the-art solutions. The system was tested on different scenarios and datasets to prove its robustness to anti-forensic attacks and its generalization capabilities.