 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOasisSimp: An Open-source Asian-English Sentence Simplification Dataset
Mar 14, 2026Sentence simplification aims to make complex text more accessible by reducing linguistic complexity while preserving the original meaning. However, progress in this area remains limited for mid-resource and low-resource languages due to the scarcity of high-quality data. To address this gap, we introduce the OasisSimp dataset, a multilingual dataset for sentence-level simplification covering five languages: English, Sinhala, Tamil, Pashto, and Thai. Among these, no prior sentence simplification datasets exist for Thai, Pashto, and Tamil, while limited data is available for Sinhala. Each language simplification dataset was created by trained annotators who followed detailed guidelines to simplify sentences while maintaining meaning, fluency, and grammatical correctness. We evaluate eight open-weight multilingual Large Language Models (LLMs) on the OasisSimp dataset and observe substantial performance disparities between high-resource and low-resource languages, highlighting the simplification challenges in multilingual settings. The OasisSimp dataset thus provides both a valuable multilingual resource and a challenging benchmark, revealing the limitations of current LLM-based simplification methods and paving the way for future research in low-resource sentence simplification. The dataset is available at https://OasisSimpDataset.github.io/.
Adapting Multimodal Foundation Models for Few-Shot Learning: A Comprehensive Study on Contrastive Captioners
Dec 14, 2025Large-scale multimodal foundation models, particularly Contrastive Captioners (CoCa), have achieved state-of-the-art results by unifying contrastive alignment with generative captioning. While zero-shot transfer capabilities are well-documented, the adaptation of these generative-contrastive hybrids to downstream tasks with extreme data scarcity (few-shot learning) remains under-explored. Existing literature predominantly focuses on dual-encoder architectures like CLIP, leaving a gap in understanding how CoCa's distinct latent space responds to parameter-efficient fine-tuning (PEFT). This paper presents a comprehensive empirical study on adapting the CoCa visual backbone for few-shot image classification. We systematically evaluate a hierarchy of strategies, ranging from training-free hybrid prototyping to deep parameter adaptation via Low-Rank Adaptation (LoRA). First, we identify an "augmentation divergence": while strong data augmentation degrades the performance of linear probing in low-shot settings, it is essential for stabilizing LoRA fine-tuning. We also demonstrate that hybrid objectives incorporating Supervised Contrastive (SupCon) loss yield consistent performance improvements over standard Cross-Entropy across varying shot counts. Crucially, we characterize the sensitivity of training configurations to data scarcity, providing empirical reference settings for scaling regularization, rank, and sampling strategies to facilitate the efficient adaptation of generative-contrastive foundation models.
Team-Aware Football Player Tracking with SAM: An Appearance-Based Approach to Occlusion Recovery
Dec 09, 2025Football player tracking is challenged by frequent occlusions, similar appearances, and rapid motion in crowded scenes. This paper presents a lightweight SAM-based tracking method combining the Segment Anything Model (SAM) with CSRT trackers and jersey color-based appearance models. We propose a team-aware tracking system that uses SAM for precise initialization and HSV histogram-based re-identification to improve occlusion recovery. Our evaluation measures three dimensions: processing speed (FPS and memory), tracking accuracy (success rate and box stability), and robustness (occlusion recovery and identity consistency). Experiments on football video sequences show that the approach achieves 7.6-7.7 FPS with stable memory usage (~1880 MB), maintaining 100 percent tracking success in light occlusions and 90 percent in crowded penalty-box scenarios with 5 or more players. Appearance-based re-identification recovers 50 percent of heavy occlusions, demonstrating the value of domain-specific cues. Analysis reveals key trade-offs: the SAM + CSRT combination provides consistent performance across crowd densities but struggles with long-term occlusions where players leave the frame, achieving only 8.66 percent re-acquisition success. These results offer practical guidelines for deploying football tracking systems under resource constraints, showing that classical tracker-based methods work well with continuous visibility but require stronger re-identification mechanisms for extended absences.
FlowChroma -- A Deep Recurrent Neural Network for Video Colorization
May 23, 2023We develop an automated video colorization framework that minimizes the flickering of colors across frames. If we apply image colorization techniques to successive frames of a video, they treat each frame as a separate colorization task. Thus, they do not necessarily maintain the colors of a scene consistently across subsequent frames. The proposed solution includes a novel deep recurrent encoder-decoder architecture which is capable of maintaining temporal and contextual coherence between consecutive frames of a video. We use a high-level semantic feature extractor to automatically identify the context of a scenario including objects, with a custom fusion layer that combines the spatial and temporal features of a frame sequence. We demonstrate experimental results, qualitatively showing that recurrent neural networks can be successfully used to improve color consistency in video colorization.
Improving English to Sinhala Neural Machine Translation using Part-of-Speech Tag
Feb 17, 2022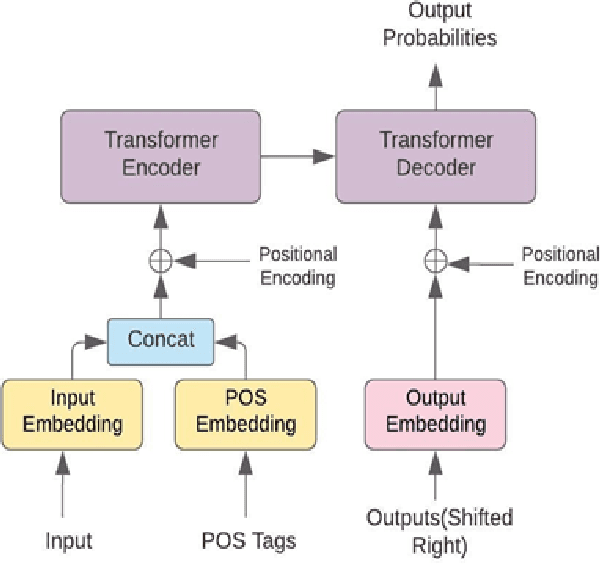
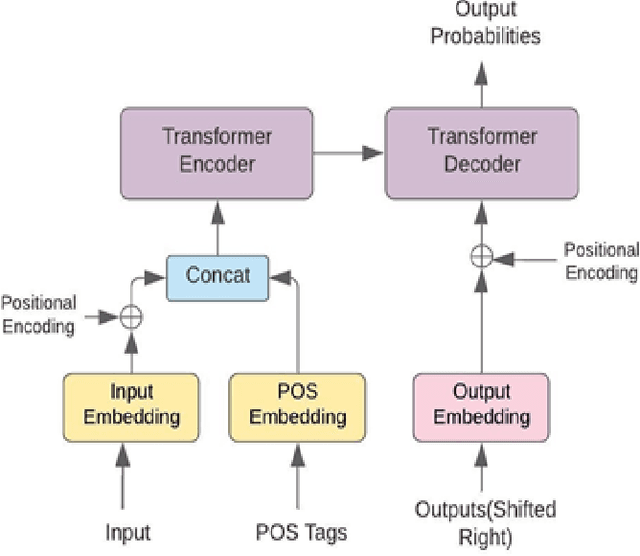
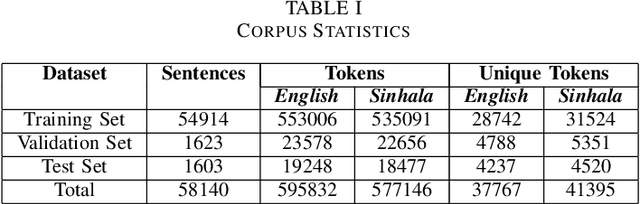
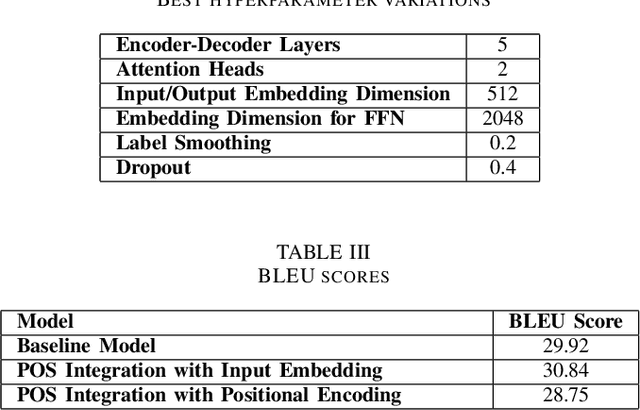
The performance of Neural Machine Translation (NMT) depends significantly on the size of the available parallel corpus. Due to this fact, low resource language pairs demonstrate low translation performance compared to high resource language pairs. The translation quality further degrades when NMT is performed for morphologically rich languages. Even though the web contains a large amount of information, most people in Sri Lanka are unable to read and understand English properly. Therefore, there is a huge requirement of translating English content to local languages to share information among locals. Sinhala language is the primary language in Sri Lanka and building an NMT system that can produce quality English to Sinhala translations is difficult due to the syntactic divergence between these two languages under low resource constraints. Thus, in this research, we explore effective methods of incorporating Part of Speech (POS) tags to the Transformer input embedding and positional encoding to further enhance the performance of the baseline English to Sinhala neural machine translation model.
Tamizhi-Net OCR: Creating A Quality Large Scale Tamil-Sinhala-English Parallel Corpus Using Deep Learning Based Printed Character Recognition
Sep 13, 2021
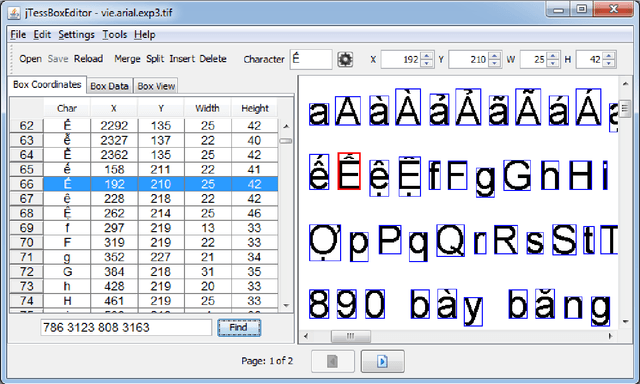

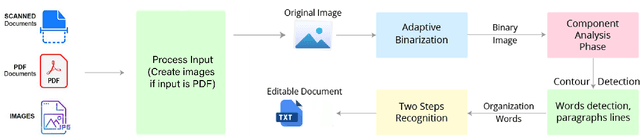
Most of the low resource languages do not have the necessary resources to create even a substantial monolingual corpus. These languages may often be found in government proceedings but mostly in the form of Portable Document Formats (PDFs) that contains legacy fonts. Extracting text from these documents to create a monolingual corpus is challenging due to legacy font usage and printer-friendly encoding which are not optimized for text extraction. Therefore, we propose a simple, automatic, and novel idea that can scale for Tamil, Sinhala, and English languages and many documents. For this purpose, we enhanced the performance of Tesseract 4.1.1 by employing LSTM-based training on many legacy fonts to recognize printed characters in the above languages. Especially, our model detects code-mix text, numbers, and special characters from the printed document. It is shown that this approach can boost the character-level accuracy of Tesseract 4.1.1 from 85.5 to 98.2 for Tamil (+12.9% relative change) and 91.8 to 94.8 for Sinhala (+3.26% relative change) on a dataset that is considered as challenging by its authors.
Towards Offensive Language Identification for Tamil Code-Mixed YouTube Comments and Posts
Aug 26, 2021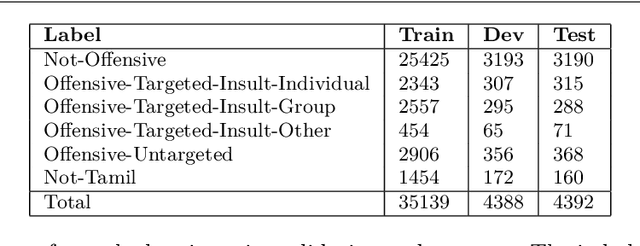
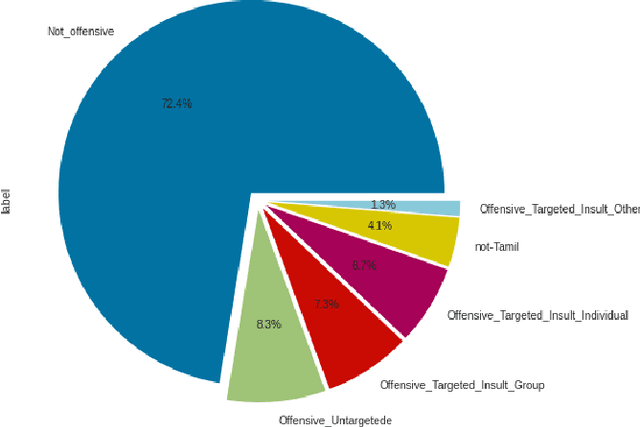
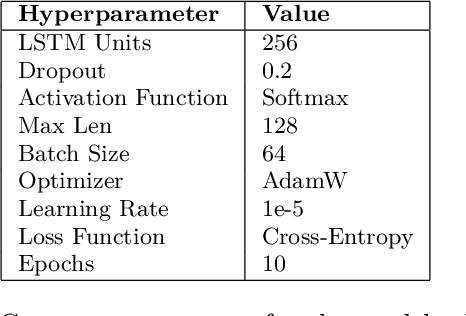
Offensive Language detection in social media platforms has been an active field of research over the past years. In non-native English spoken countries, social media users mostly use a code-mixed form of text in their posts/comments. This poses several challenges in the offensive content identification tasks, and considering the low resources available for Tamil, the task becomes much harder. The current study presents extensive experiments using multiple deep learning, and transfer learning models to detect offensive content on YouTube. We propose a novel and flexible approach of selective translation and transliteration techniques to reap better results from fine-tuning and ensembling multilingual transformer networks like BERT, Distil- BERT, and XLM-RoBERTa. The experimental results showed that ULMFiT is the best model for this task. The best performing models were ULMFiT and mBERTBiLSTM for this Tamil code-mix dataset instead of more popular transfer learning models such as Distil- BERT and XLM-RoBERTa and hybrid deep learning models. The proposed model ULMFiT and mBERTBiLSTM yielded good results and are promising for effective offensive speech identification in low-resourced languages.
Data-Driven Simulation of Ride-Hailing Services using Imitation and Reinforcement Learning
Apr 06, 2021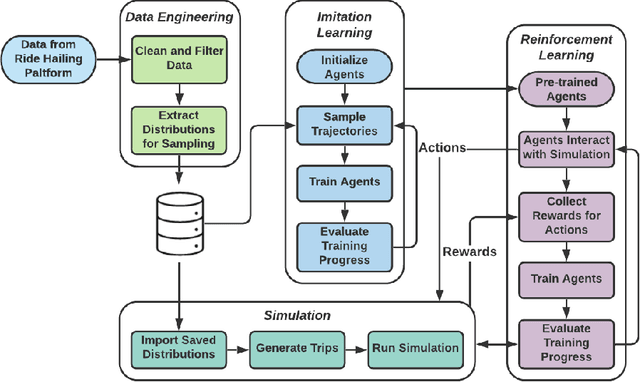
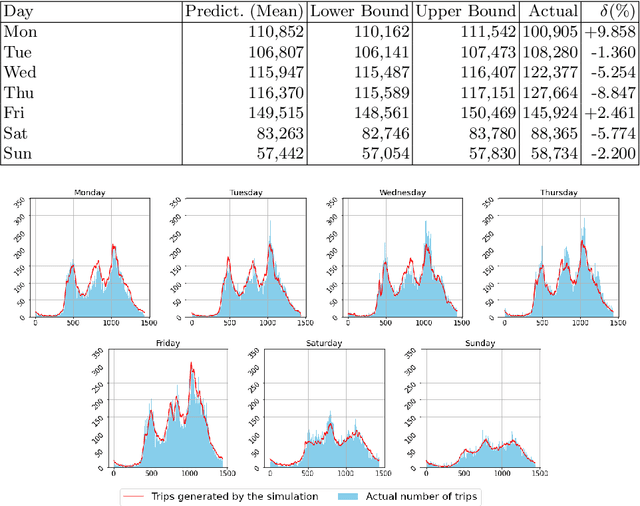
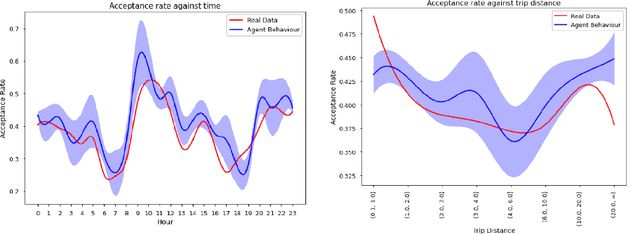
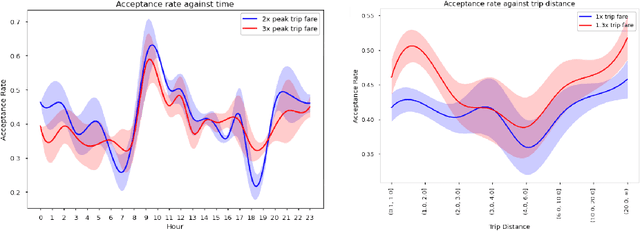
The rapid growth of ride-hailing platforms has created a highly competitive market where businesses struggle to make profits, demanding the need for better operational strategies. However, real-world experiments are risky and expensive for these platforms as they deal with millions of users daily. Thus, a need arises for a simulated environment where they can predict users' reactions to changes in the platform-specific parameters such as trip fares and incentives. Building such a simulation is challenging, as these platforms exist within dynamic environments where thousands of users regularly interact with one another. This paper presents a framework to mimic and predict user, specifically driver, behaviors in ride-hailing services. We use a data-driven hybrid reinforcement learning and imitation learning approach for this. First, the agent utilizes behavioral cloning to mimic driver behavior using a real-world data set. Next, reinforcement learning is applied on top of the pre-trained agents in a simulated environment, to allow them to adapt to changes in the platform. Our framework provides an ideal playground for ride-hailing platforms to experiment with platform-specific parameters to predict drivers' behavioral patterns.
Exploring Deep Neural Networks and Transfer Learning for Analyzing Emotions in Tweets
Dec 10, 2020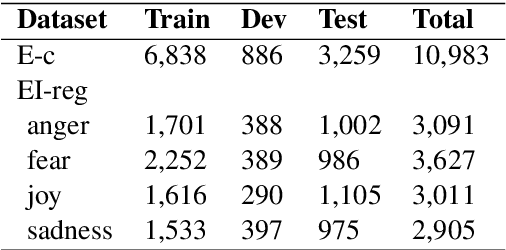
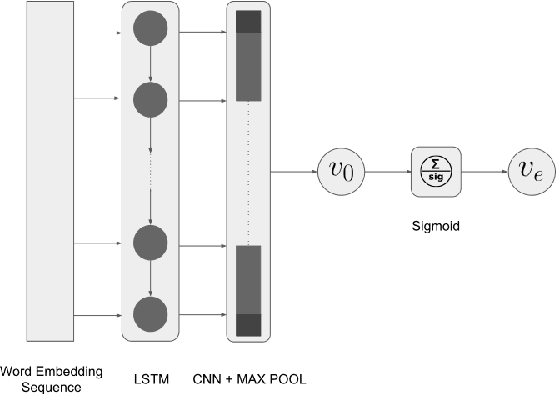
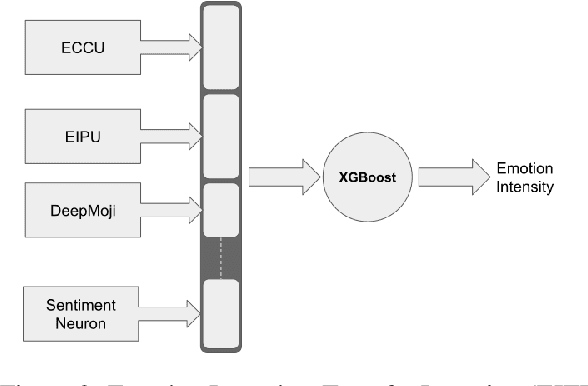
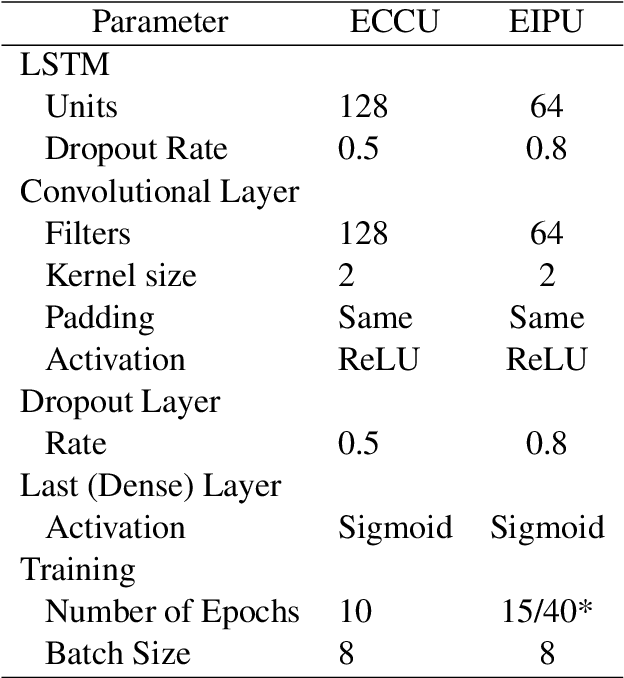
In this paper, we present an experiment on using deep learning and transfer learning techniques for emotion analysis in tweets and suggest a method to interpret our deep learning models. The proposed approach for emotion analysis combines a Long Short Term Memory (LSTM) network with a Convolutional Neural Network (CNN). Then we extend this approach for emotion intensity prediction using transfer learning technique. Furthermore, we propose a technique to visualize the importance of each word in a tweet to get a better understanding of the model. Experimentally, we show in our analysis that the proposed models outperform the state-of-the-art in emotion classification while maintaining competitive results in predicting emotion intensity.
Concept Discovery through Information Extraction in Restaurant Domain
Jun 12, 2019



Concept identification is a crucial step in understanding and building a knowledge base for any particular domain. However, it is not a simple task in very large domains such as restaurants and hotel. In this paper, a novel approach of identifying a concept hierarchy and classifying unseen words into identified concepts related to restaurant domain is presented. Sorting, identifying, classifying of domain-related words manually is tedious and therefore, the proposed process is automated to a great extent. Word embedding, hierarchical clustering, classification algorithms are effectively used to obtain concepts related to the restaurant domain. Further, this approach can also be extended to create a semi-automatic ontology on restaurant domain.