 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeISINet: An Instance-Based Approach for Surgical Instrument Segmentation
Jul 10, 2020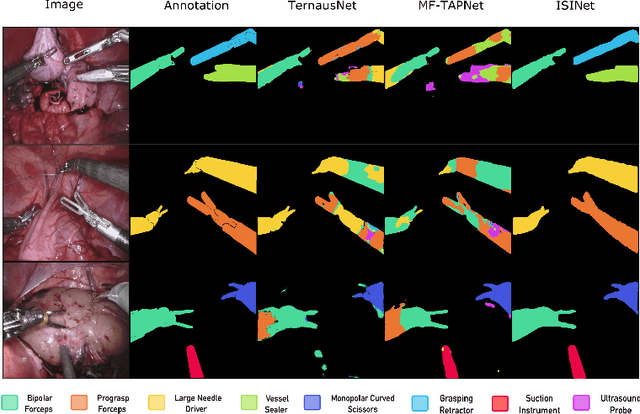
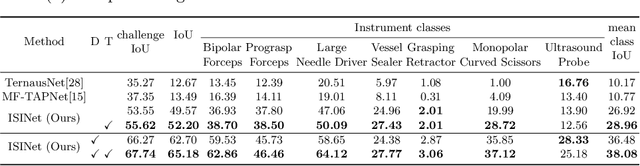
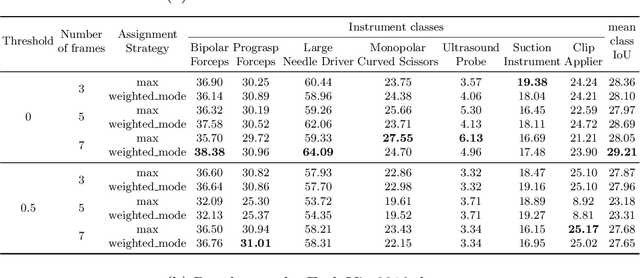
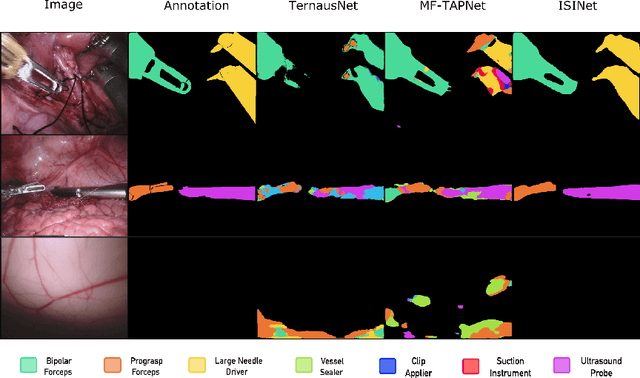
We study the task of semantic segmentation of surgical instruments in robotic-assisted surgery scenes. We propose the Instance-based Surgical Instrument Segmentation Network (ISINet), a method that addresses this task from an instance-based segmentation perspective. Our method includes a temporal consistency module that takes into account the previously overlooked and inherent temporal information of the problem. We validate our approach on the existing benchmark for the task, the Endoscopic Vision 2017 Robotic Instrument Segmentation Dataset, and on the 2018 version of the dataset, whose annotations we extended for the fine-grained version of instrument segmentation. Our results show that ISINet significantly outperforms state-of-the-art methods, with our baseline version duplicating the Intersection over Union (IoU) of previous methods and our complete model triplicating the IoU.
Active Speakers in Context
May 20, 2020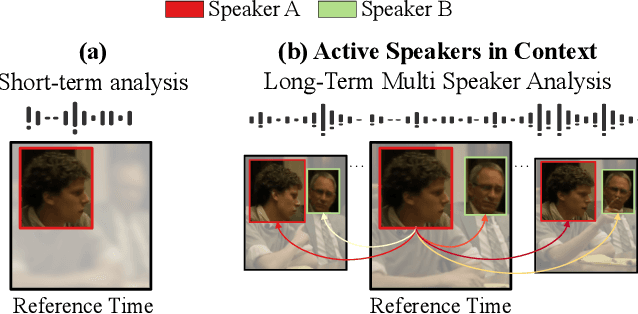
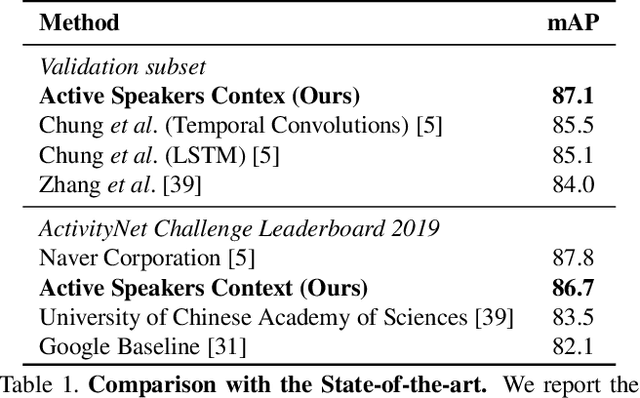
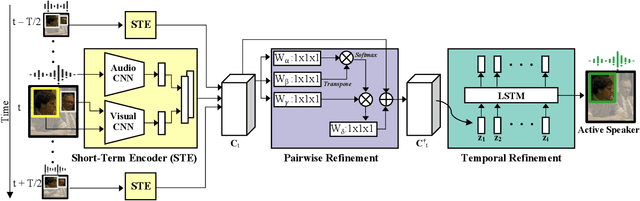

Current methods for active speak er detection focus on modeling short-term audiovisual information from a single speaker. Although this strategy can be enough for addressing single-speaker scenarios, it prevents accurate detection when the task is to identify who of many candidate speakers are talking. This paper introduces the Active Speaker Context, a novel representation that models relationships between multiple speakers over long time horizons. Our Active Speaker Context is designed to learn pairwise and temporal relations from an structured ensemble of audio-visual observations. Our experiments show that a structured feature ensemble already benefits the active speaker detection performance. Moreover, we find that the proposed Active Speaker Context improves the state-of-the-art on the AVA-ActiveSpeaker dataset achieving a mAP of 87.1%. We present ablation studies that verify that this result is a direct consequence of our long-term multi-speaker analysis.
MAIN: Multi-Attention Instance Network for Video Segmentation
Apr 11, 2019
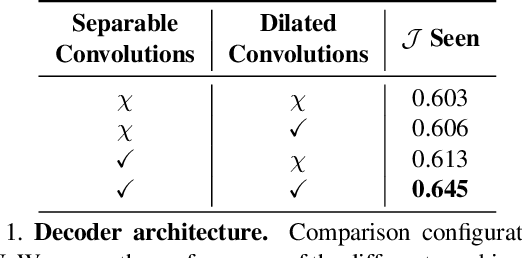
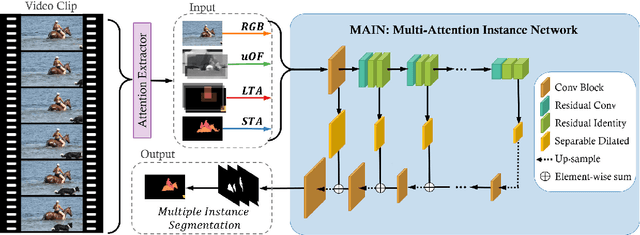

Instance-level video segmentation requires a solid integration of spatial and temporal information. However, current methods rely mostly on domain-specific information (online learning) to produce accurate instance-level segmentations. We propose a novel approach that relies exclusively on the integration of generic spatio-temporal attention cues. Our strategy, named Multi-Attention Instance Network (MAIN), overcomes challenging segmentation scenarios over arbitrary videos without modelling sequence- or instance-specific knowledge. We design MAIN to segment multiple instances in a single forward pass, and optimize it with a novel loss function that favors class agnostic predictions and assigns instance-specific penalties. We achieve state-of-the-art performance on the challenging Youtube-VOS dataset and benchmark, improving the unseen Jaccard and F-Metric by 6.8% and 12.7% respectively, while operating at real-time (30.3 FPS).
BAOD: Budget-Aware Object Detection
Apr 10, 2019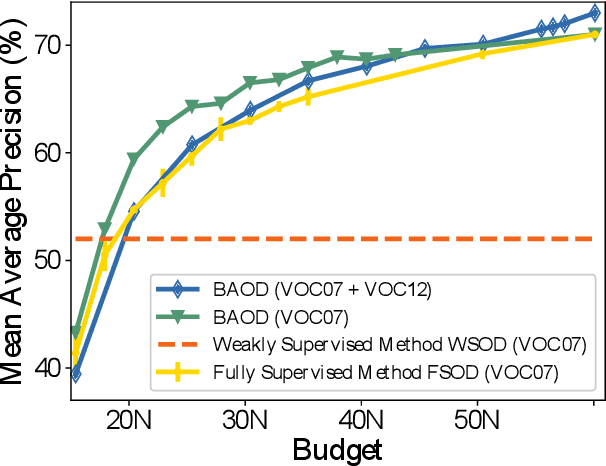
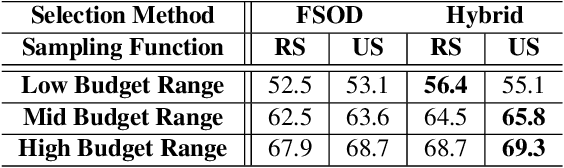
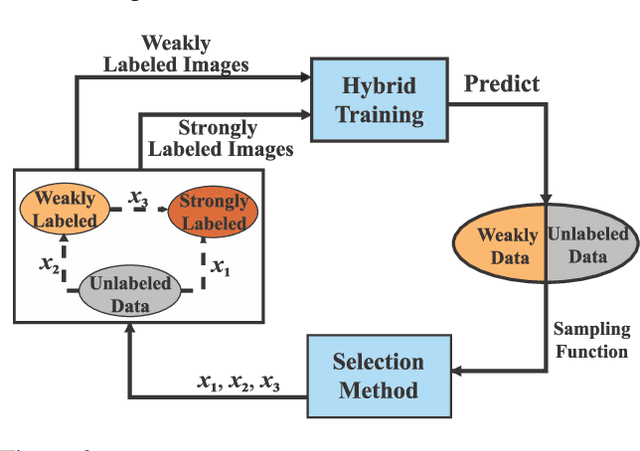
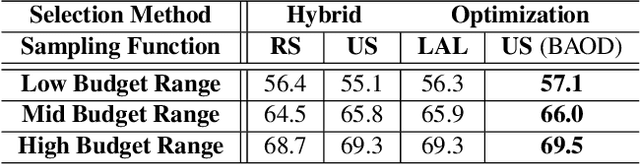
We study the problem of object detection from a novel perspective in which annotation budget constraints are taken into consideration, appropriately coined Budget Aware Object Detection (BAOD). When provided with a fixed budget, we propose a strategy for building a diverse and informative dataset that can be used to optimally train a robust detector. We investigate both optimization and learning-based methods to sample which images to annotate and what type of annotation (strongly or weakly supervised) to annotate them with. We adopt a hybrid supervised learning framework to train the object detector from both these types of annotation. We conduct a comprehensive empirical study showing that a handcrafted optimization method outperforms other selection techniques including random sampling, uncertainty sampling and active learning. By combining an optimal image/annotation selection scheme with hybrid supervised learning to solve the BAOD problem, we show that one can achieve the performance of a strongly supervised detector on PASCAL-VOC 2007 while saving 12.8% of its original annotation budget. Furthermore, when $100\%$ of the budget is used, it surpasses this performance by 2.0 mAP percentage points.
Multi-View Dynamic Facial Action Unit Detection
Aug 20, 2018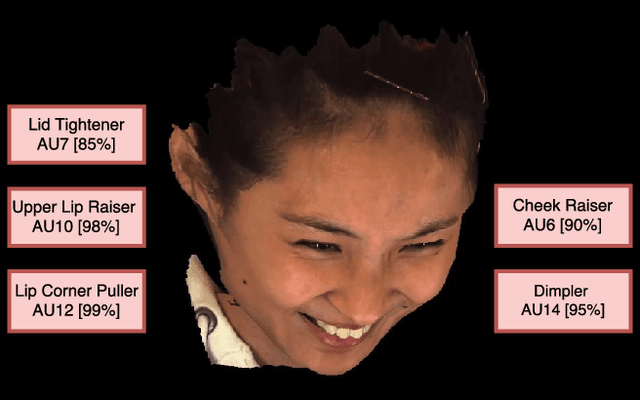
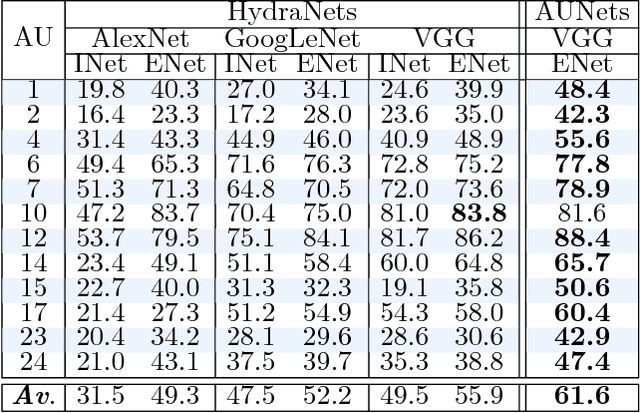
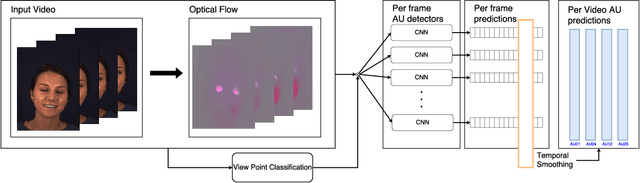
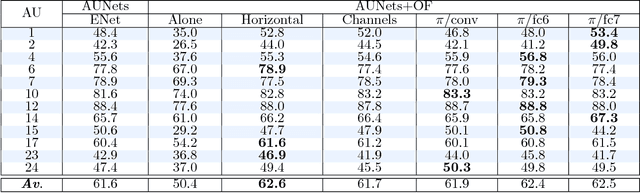
We propose a novel convolutional neural network approach to address the fine-grained recognition problem of multi-view dynamic facial action unit detection. We leverage recent gains in large-scale object recognition by formulating the task of predicting the presence or absence of a specific action unit in a still image of a human face as holistic classification. We then explore the design space of our approach by considering both shared and independent representations for separate action units, and also different CNN architectures for combining color and motion information. We then move to the novel setup of the FERA 2017 Challenge, in which we propose a multi-view extension of our approach that operates by first predicting the viewpoint from which the video was taken, and then evaluating an ensemble of action unit detectors that were trained for that specific viewpoint. Our approach is holistic, efficient, and modular, since new action units can be easily included in the overall system. Our approach significantly outperforms the baseline of the FERA 2017 Challenge, with an absolute improvement of 14% on the F1-metric. Additionally, it compares favorably against the winner of the FERA 2017 challenge. Code source is available at https://github.com/BCV-Uniandes/AUNets.
Multiscale Combinatorial Grouping for Image Segmentation and Object Proposal Generation
Mar 01, 2016
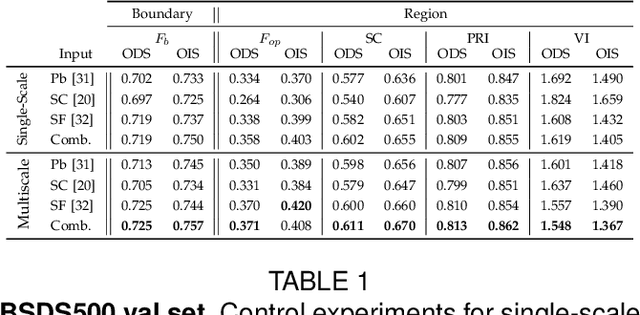
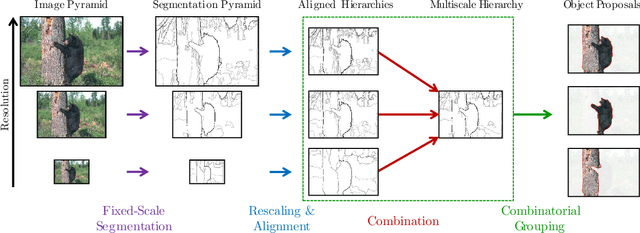
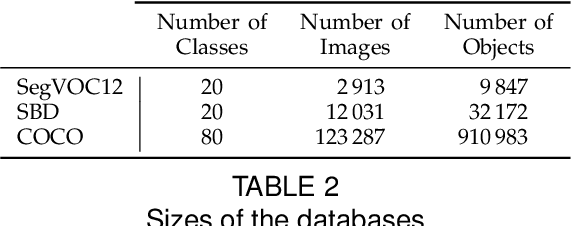
We propose a unified approach for bottom-up hierarchical image segmentation and object proposal generation for recognition, called Multiscale Combinatorial Grouping (MCG). For this purpose, we first develop a fast normalized cuts algorithm. We then propose a high-performance hierarchical segmenter that makes effective use of multiscale information. Finally, we propose a grouping strategy that combines our multiscale regions into highly-accurate object proposals by exploring efficiently their combinatorial space. We also present Single-scale Combinatorial Grouping (SCG), a faster version of MCG that produces competitive proposals in under five second per image. We conduct an extensive and comprehensive empirical validation on the BSDS500, SegVOC12, SBD, and COCO datasets, showing that MCG produces state-of-the-art contours, hierarchical regions, and object proposals.
Learning to Segment Moving Objects in Videos
May 08, 2015

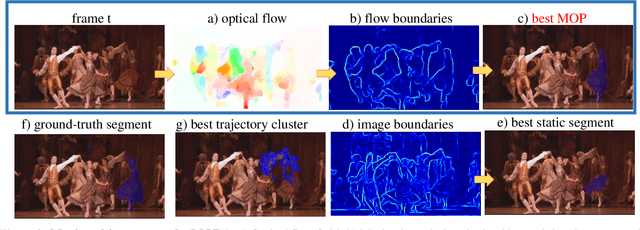
We segment moving objects in videos by ranking spatio-temporal segment proposals according to "moving objectness": how likely they are to contain a moving object. In each video frame, we compute segment proposals using multiple figure-ground segmentations on per frame motion boundaries. We rank them with a Moving Objectness Detector trained on image and motion fields to detect moving objects and discard over/under segmentations or background parts of the scene. We extend the top ranked segments into spatio-temporal tubes using random walkers on motion affinities of dense point trajectories. Our final tube ranking consistently outperforms previous segmentation methods in the two largest video segmentation benchmarks currently available, for any number of proposals. Further, our per frame moving object proposals increase the detection rate up to 7\% over previous state-of-the-art static proposal methods.