 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparison of Deep Learning and Established Methods for Calf Behaviour Monitoring
Aug 23, 2024



In recent years, there has been considerable progress in research on human activity recognition using data from wearable sensors. This technology also has potential in the context of animal welfare in livestock science. In this paper, we report on research on animal activity recognition in support of welfare monitoring. The data comes from collar-mounted accelerometer sensors worn by Holstein and Jersey calves, the objective being to detect changes in behaviour indicating sickness or stress. A key requirement in detecting changes in behaviour is to be able to classify activities into classes, such as drinking, running or walking. In Machine Learning terms, this is a time-series classification task, and in recent years, the Rocket family of methods have emerged as the state-of-the-art in this area. We have over 27 hours of labelled time-series data from 30 calves for our analysis. Using this data as a baseline, we present Rocket's performance on a 6-class classification task. Then, we compare this against the performance of 11 Deep Learning (DL) methods that have been proposed as promising methods for time-series classification. Given the success of DL in related areas, it is reasonable to expect that these methods will perform well here as well. Surprisingly, despite taking care to ensure that the DL methods are configured correctly, none of them match Rocket's performance. A possible explanation for the impressive success of Rocket is that it has the data encoding benefits of DL models in a much simpler classification framework.
Development of a digital tool for monitoring the behaviour of pre-weaned calves using accelerometer neck-collars
Jun 25, 2024



Automatic monitoring of calf behaviour is a promising way of assessing animal welfare from their first week on farms. This study aims to (i) develop machine learning models from accelerometer data to classify the main behaviours of pre-weaned calves and (ii) set up a digital tool for monitoring the behaviour of pre-weaned calves from the models' prediction. Thirty pre-weaned calves were equipped with a 3-D accelerometer attached to a neck-collar for two months and filmed simultaneously. The behaviours were annotated, resulting in 27.4 hours of observation aligned with the accelerometer data. The time-series were then split into 3 seconds windows. Two machine learning models were tuned using data from 80% of the calves: (i) a Random Forest model to classify between active and inactive behaviours using a set of 11 hand-craft features [model 1] and (ii) a RidgeClassifierCV model to classify between lying, running, drinking milk and other behaviours using ROCKET features [model 2]. The performance of the models was tested using data from the remaining 20% of the calves. Model 1 achieved a balanced accuracy of 0.92. Model 2 achieved a balanced accuracy of 0.84. Behavioural metrics such as daily activity ratio and episodes of running, lying, drinking milk, and other behaviours expressed over time were deduced from the predictions. All the development was finally embedded into a Python dashboard so that the individual calf metrics could be displayed directly from the raw accelerometer files.
Introducing a Family of Synthetic Datasets for Research on Bias in Machine Learning
Aug 03, 2021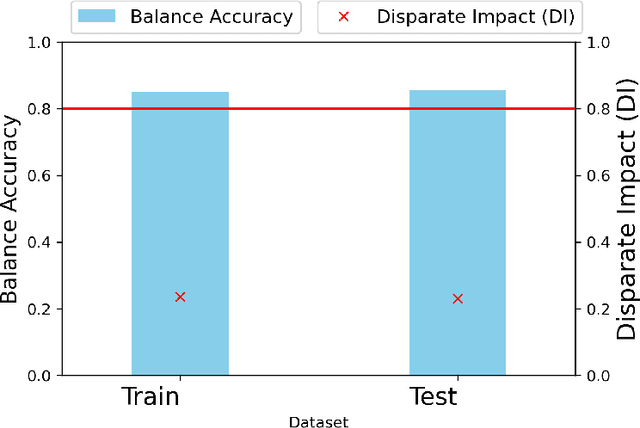
A significant impediment to progress in research on bias in machine learning (ML) is the availability of relevant datasets. This situation is unlikely to change much given the sensitivity of such data. For this reason, there is a role for synthetic data in this research. In this short paper, we present one such family of synthetic data sets. We provide an overview of the data, describe how the level of bias can be varied, and present a simple example of an experiment on the data.
Exploring the Efficacy of Automatically Generated Counterfactuals for Sentiment Analysis
Jun 30, 2021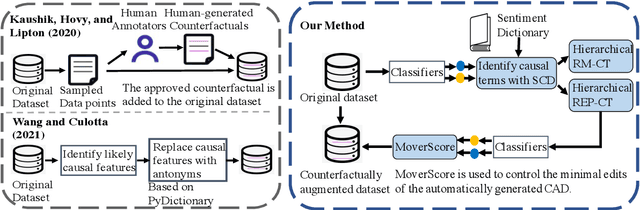

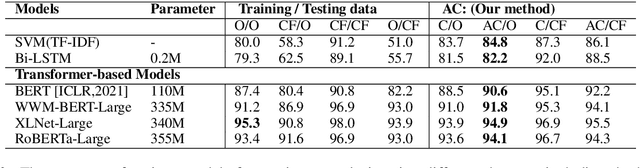

While state-of-the-art NLP models have been achieving the excellent performance of a wide range of tasks in recent years, important questions are being raised about their robustness and their underlying sensitivity to systematic biases that may exist in their training and test data. Such issues come to be manifest in performance problems when faced with out-of-distribution data in the field. One recent solution has been to use counterfactually augmented datasets in order to reduce any reliance on spurious patterns that may exist in the original data. Producing high-quality augmented data can be costly and time-consuming as it usually needs to involve human feedback and crowdsourcing efforts. In this work, we propose an alternative by describing and evaluating an approach to automatically generating counterfactual data for data augmentation and explanation. A comprehensive evaluation on several different datasets and using a variety of state-of-the-art benchmarks demonstrate how our approach can achieve significant improvements in model performance when compared to models training on the original data and even when compared to models trained with the benefit of human-generated augmented data.
Using Pareto Simulated Annealing to Address Algorithmic Bias in Machine Learning
May 31, 2021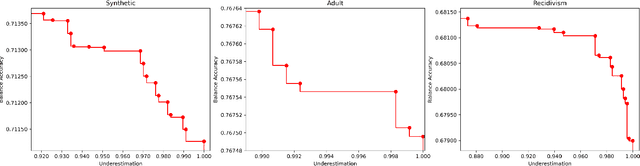

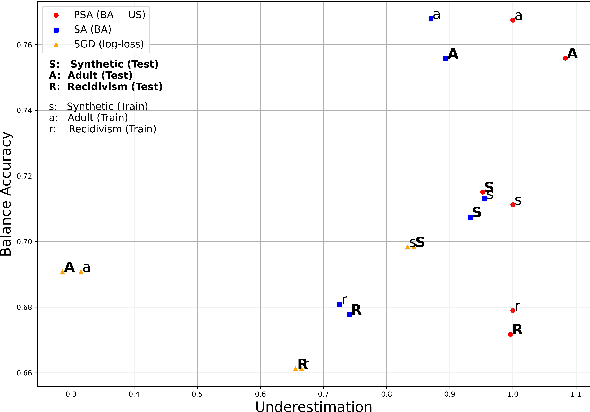
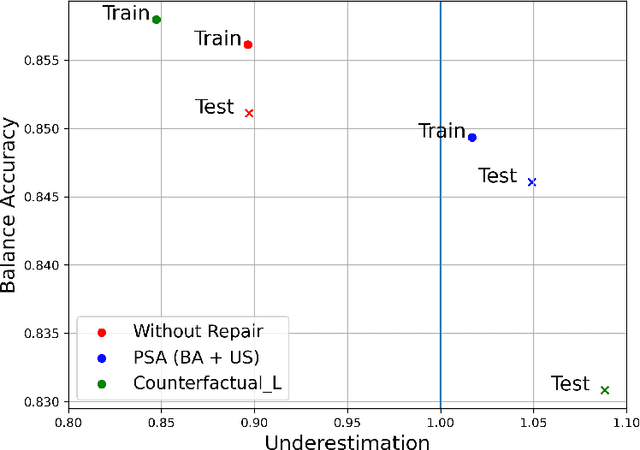
Algorithmic Bias can be due to bias in the training data or issues with the algorithm itself. These algorithmic issues typically relate to problems with model capacity and regularisation. This underestimation bias may arise because the model has been optimised for good generalisation accuracy without any explicit consideration of bias or fairness. In a sense, we should not be surprised that a model might be biased when it hasn't been "asked" not to be. In this paper, we consider including bias (underestimation) as an additional criterion in model training. We present a multi-objective optimisation strategy using Pareto Simulated Annealing that optimise for both balanced accuracy and underestimation. We demonstrate the effectiveness of this strategy on one synthetic and two real-world datasets.
Algorithmic Factors Influencing Bias in Machine Learning
Apr 28, 2021
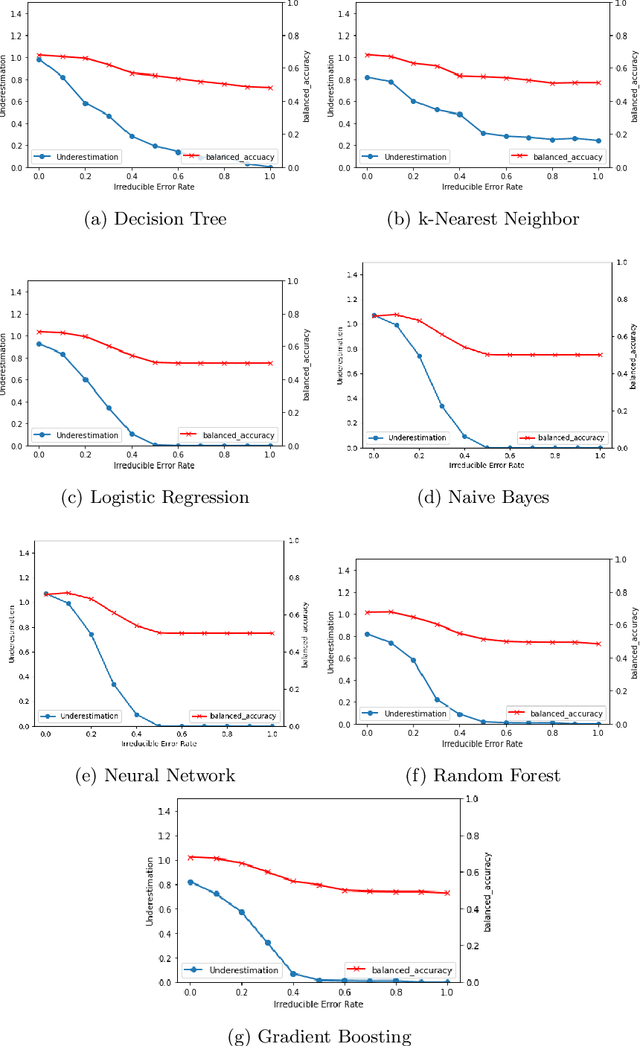
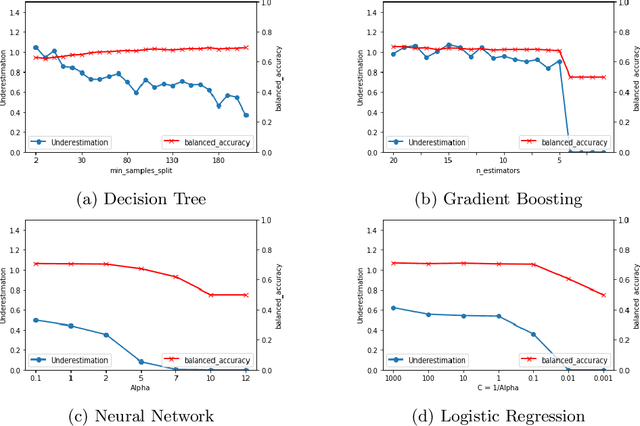
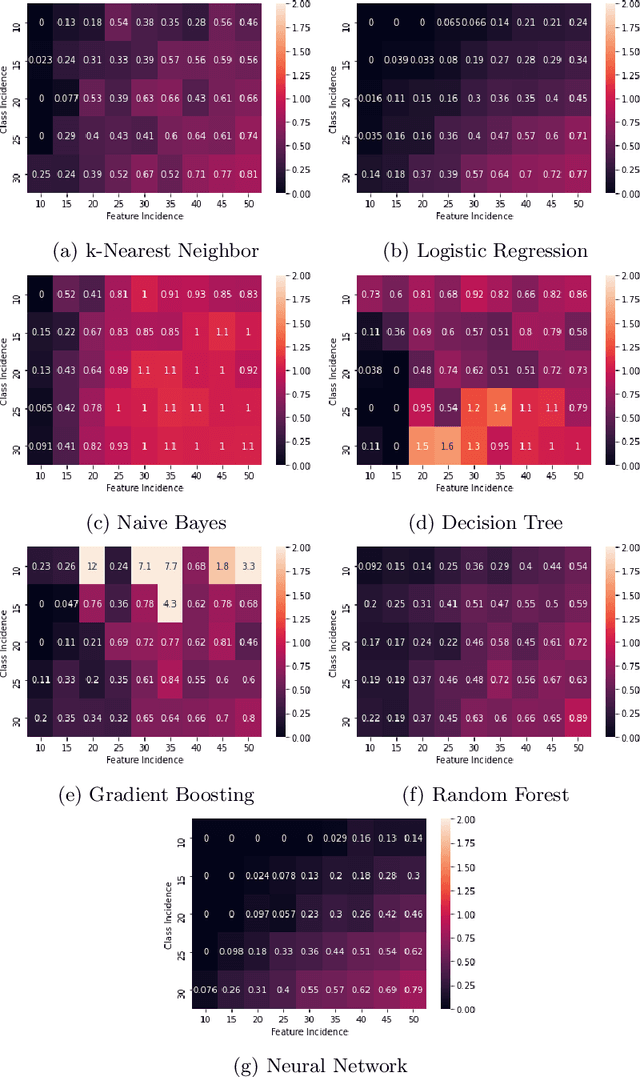
It is fair to say that many of the prominent examples of bias in Machine Learning (ML) arise from bias that is there in the training data. In fact, some would argue that supervised ML algorithms cannot be biased, they reflect the data on which they are trained. In this paper we demonstrate how ML algorithms can misrepresent the training data through underestimation. We show how irreducible error, regularization and feature and class imbalance can contribute to this underestimation. The paper concludes with a demonstration of how the careful management of synthetic counterfactuals can ameliorate the impact of this underestimation bias.
A Case-Study on the Impact of Dynamic Time Warping in Time Series Regression
Oct 11, 2020
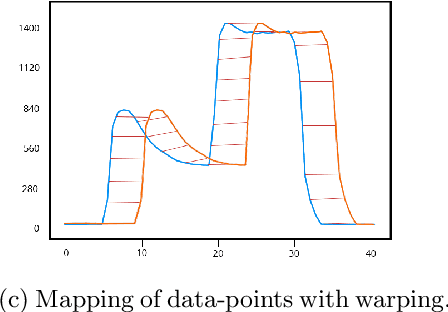
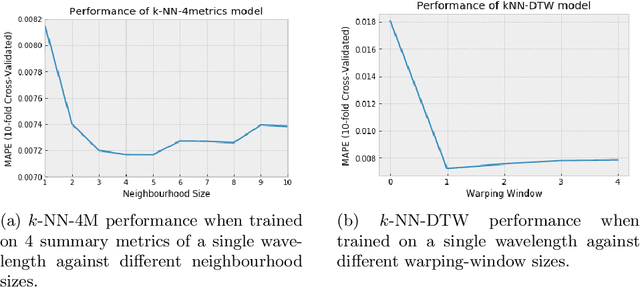
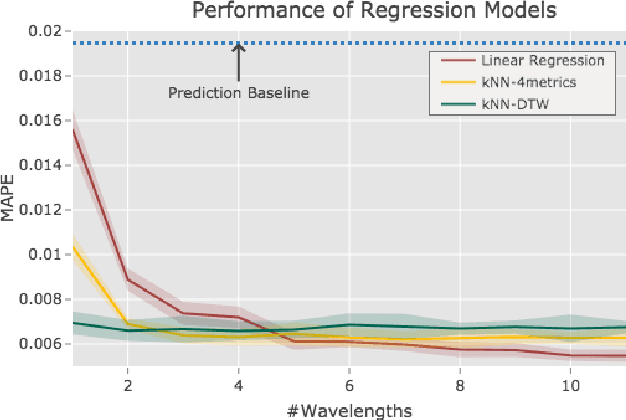
It is well understood that Dynamic Time Warping (DTW) is effective in revealing similarities between time series that do not align perfectly. In this paper, we illustrate this on spectroscopy time-series data. We show that DTW is effective in improving accuracy on a regression task when only a single wavelength is considered. When combined with k-Nearest Neighbour, DTW has the added advantage that it can reveal similarities and differences between samples at the level of the time-series. However, in the problem, we consider here data is available across a spectrum of wavelengths. If aggregate statistics (means, variances) are used across many wavelengths the benefits of DTW are no longer apparent. We present this as another example of a situation where big data trumps sophisticated models in Machine Learning.
Indicators of Good Student Performance in Moodle Activity Data
Jan 12, 2016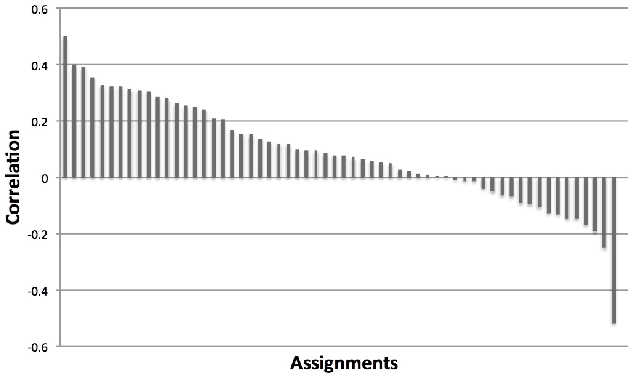
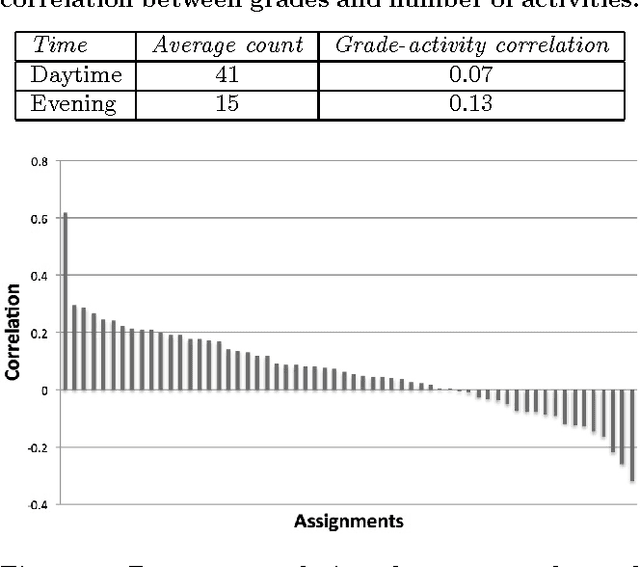
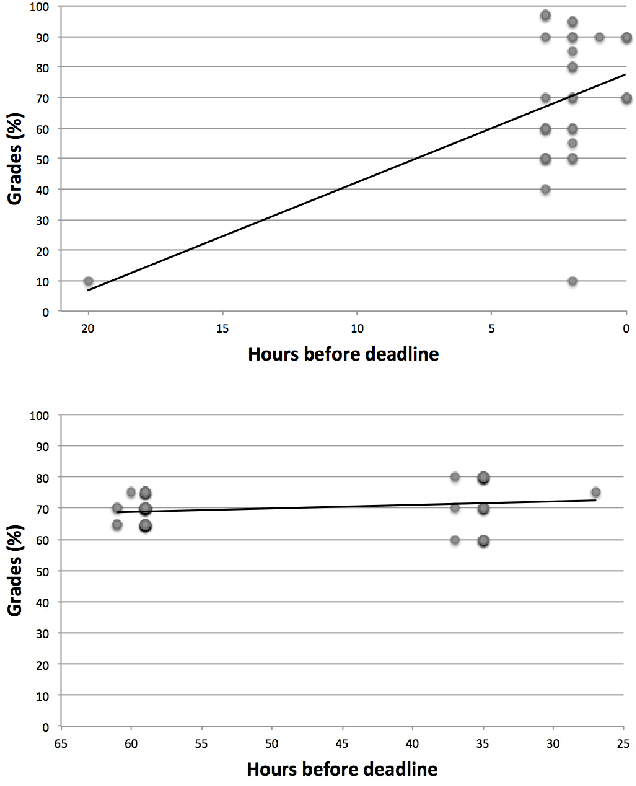
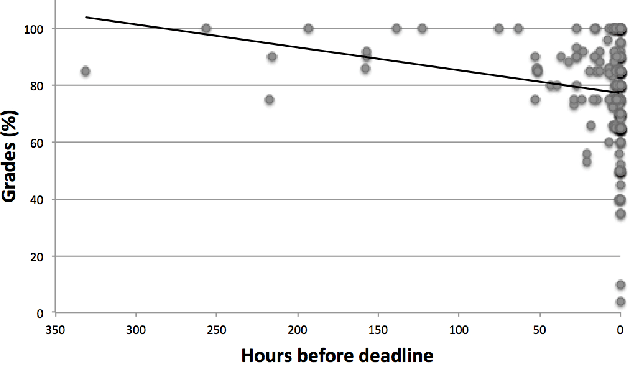
In this paper we conduct an analysis of Moodle activity data focused on identifying early predictors of good student performance. The analysis shows that three relevant hypotheses are largely supported by the data. These hypotheses are: early submission is a good sign, a high level of activity is predictive of good results and evening activity is even better than daytime activity. We highlight some pathological examples where high levels of activity correlates with bad results.
Adaptive Representations for Tracking Breaking News on Twitter
Nov 28, 2014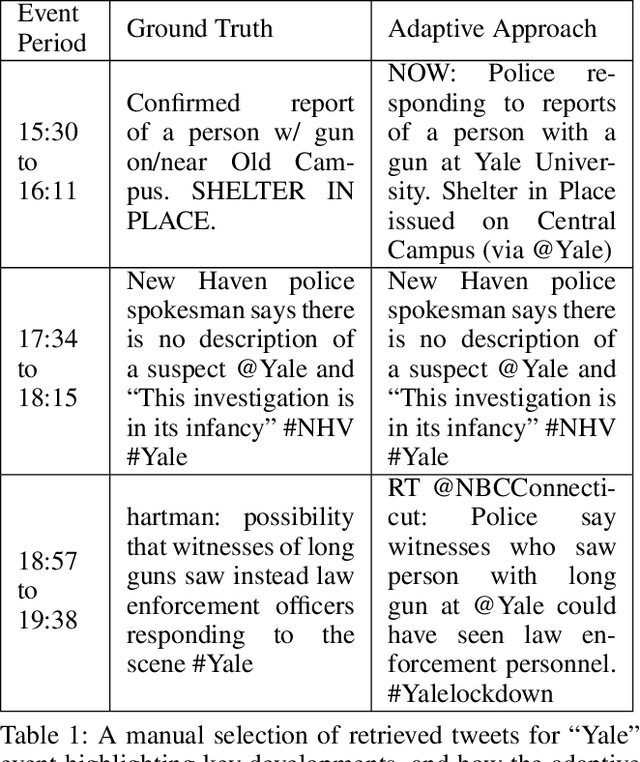
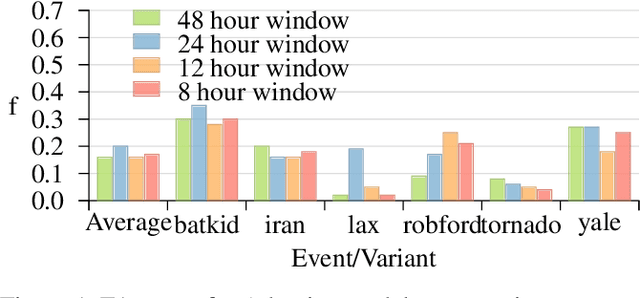
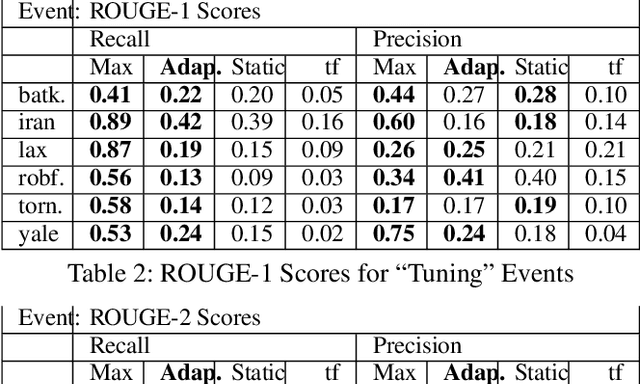
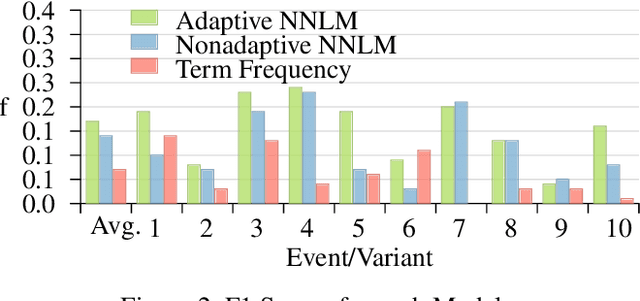
Twitter is often the most up-to-date source for finding and tracking breaking news stories. Therefore, there is considerable interest in developing filters for tweet streams in order to track and summarize stories. This is a non-trivial text analytics task as tweets are short, and standard retrieval methods often fail as stories evolve over time. In this paper we examine the effectiveness of adaptive mechanisms for tracking and summarizing breaking news stories. We evaluate the effectiveness of these mechanisms on a number of recent news events for which manually curated timelines are available. Assessments based on ROUGE metrics indicate that an adaptive approaches are best suited for tracking evolving stories on Twitter.
A Latent Space Analysis of Editor Lifecycles in Wikipedia
Jul 29, 2014
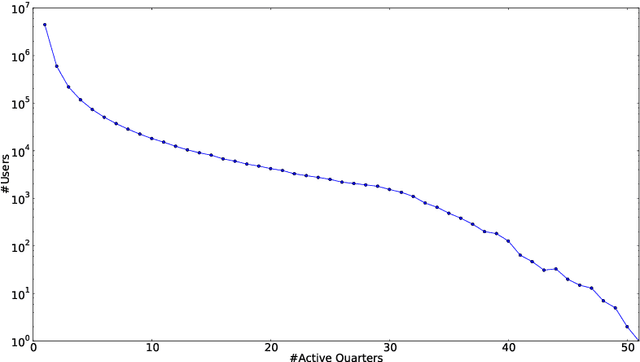
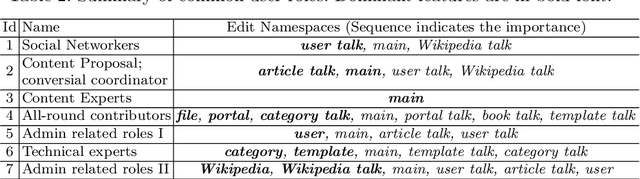
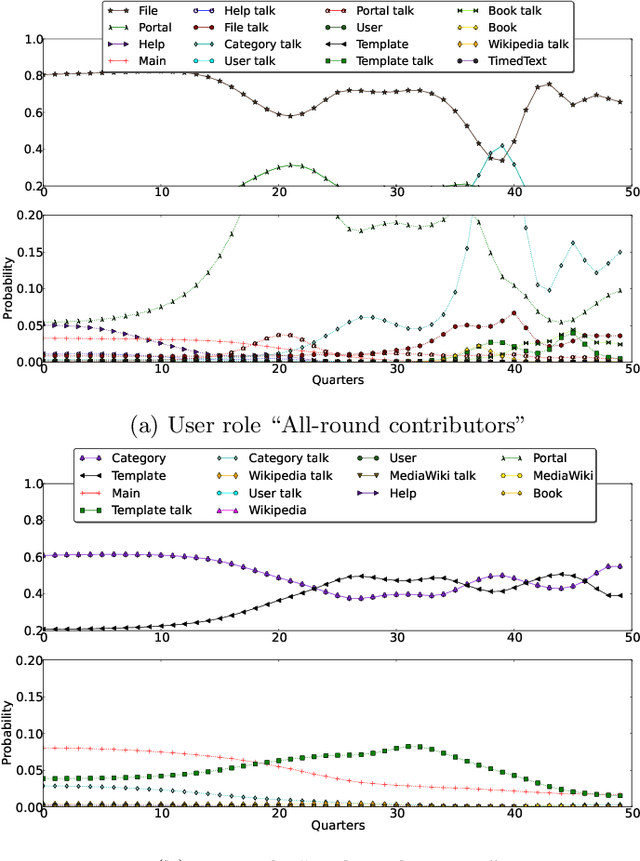
Collaborations such as Wikipedia are a key part of the value of the modern Internet. At the same time there is concern that these collaborations are threatened by high levels of member turnover. In this paper we borrow ideas from topic analysis to editor activity on Wikipedia over time into a latent space that offers an insight into the evolving patterns of editor behavior. This latent space representation reveals a number of different categories of editor (e.g. content experts, social networkers) and we show that it does provide a signal that predicts an editor's departure from the community. We also show that long term editors gradually diversify their participation by shifting edit preference from one or two namespaces to multiple namespaces and experience relatively soft evolution in their editor profiles, while short term editors generally distribute their contribution randomly among the namespaces and experience considerably fluctuated evolution in their editor profiles.