 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNovel Algorithms for Smoothly Differentiable and Efficiently Vectorizable Contact Manifold Construction
Apr 19, 2026Generating intelligent robot behavior in contact-rich settings is a research problem where zeroth-order methods currently prevail. Developing methods that make use of first/second order information about the dynamics holds great promise in terms of increasing the solution speed and computational efficiency. The main bottleneck in this research direction is the difficulty in obtaining useful gradients and Hessians, due to pathologies in all three steps of a common simulation pipeline: i) collision detection, ii) contact dynamics, iii) time integration. This abstract proposes a method that can address the collision detection part of the puzzle in a manner that is smoothly differentiable and massively vectorizable. This is achieved via two contributions: i) a highly expressive class of analytical SDF primitives that can efficiently represent complex 3D surfaces, ii) a novel contact manifold generation routine that makes use of this geometry representation.
SoftJAX & SoftTorch: Empowering Automatic Differentiation Libraries with Informative Gradients
Mar 09, 2026Automatic differentiation (AD) frameworks such as JAX and PyTorch have enabled gradient-based optimization for a wide range of scientific fields. Yet, many "hard" primitives in these libraries such as thresholding, Boolean logic, discrete indexing, and sorting operations yield zero or undefined gradients that are not useful for optimization. While numerous "soft" relaxations have been proposed that provide informative gradients, the respective implementations are fragmented across projects, making them difficult to combine and compare. This work introduces SoftJAX and SoftTorch, open-source, feature-complete libraries for soft differentiable programming. These libraries provide a variety of soft functions as drop-in replacements for their hard JAX and PyTorch counterparts. This includes (i) elementwise operators such as clip or abs, (ii) utility methods for manipulating Booleans and indices via fuzzy logic, (iii) axiswise operators such as sort or rank -- based on optimal transport or permutahedron projections, and (iv) offer full support for straight-through gradient estimation. Overall, SoftJAX and SoftTorch make the toolbox of soft relaxations easily accessible to differentiable programming, as demonstrated through benchmarking and a practical case study. Code is available at github.com/a-paulus/softjax and github.com/a-paulus/softtorch.
Smoothly Differentiable and Efficiently Vectorizable Contact Manifold Generation
Feb 23, 2026Simulating rigid-body dynamics with contact in a fast, massively vectorizable, and smoothly differentiable manner is highly desirable in robotics. An important bottleneck faced by existing differentiable simulation frameworks is contact manifold generation: representing the volume of intersection between two colliding geometries via a discrete set of properly distributed contact points. A major factor contributing to this bottleneck is that the related routines of commonly used robotics simulators were not designed with vectorization and differentiability as a primary concern, and thus rely on logic and control flow that hinder these goals. We instead propose a framework designed from the ground up with these goals in mind, by trying to strike a middle ground between: i) convex primitive based approaches used by common robotics simulators (efficient but not differentiable), and ii) mollified vertex-face and edge-edge unsigned distance-based approaches used by barrier methods (differentiable but inefficient). Concretely, we propose: i) a representative set of smooth analytical signed distance primitives to implement vertex-face collisions, and ii) a novel differentiable edge-edge collision routine that can provide signed distances and signed contact normals. The proposed framework is evaluated via a set of didactic experiments and benchmarked against the collision detection routine of the well-established Mujoco XLA framework, where we observe a significant speedup. Supplementary videos can be found at https://github.com/bekeronur/contax, where a reference implementation in JAX will also be made available at the conclusion of the review process.
A Smooth Analytical Formulation of Collision Detection and Rigid Body Dynamics With Contact
Mar 14, 2025Generating intelligent robot behavior in contact-rich settings is a research problem where zeroth-order methods currently prevail. A major contributor to the success of such methods is their robustness in the face of non-smooth and discontinuous optimization landscapes that are characteristic of contact interactions, yet zeroth-order methods remain computationally inefficient. It is therefore desirable to develop methods for perception, planning and control in contact-rich settings that can achieve further efficiency by making use of first and second order information (i.e., gradients and Hessians). To facilitate this, we present a joint formulation of collision detection and contact modelling which, compared to existing differentiable simulation approaches, provides the following benefits: i) it results in forward and inverse dynamics that are entirely analytical (i.e. do not require solving optimization or root-finding problems with iterative methods) and smooth (i.e. twice differentiable), ii) it supports arbitrary collision geometries without needing a convex decomposition, and iii) its runtime is independent of the number of contacts. Through simulation experiments, we demonstrate the validity of the proposed formulation as a "physics for inference" that can facilitate future development of efficient methods to generate intelligent contact-rich behavior.
A Probabilistic Relaxation of the Two-Stage Object Pose Estimation Paradigm
Jun 01, 2023
Existing object pose estimation methods commonly require a one-to-one point matching step that forces them to be separated into two consecutive stages: visual correspondence detection (e.g., by matching feature descriptors as part of a perception front-end) followed by geometric alignment (e.g., by optimizing a robust estimation objective for pointcloud registration or perspective-n-point). Instead, we propose a matching-free probabilistic formulation with two main benefits: i) it enables unified and concurrent optimization of both visual correspondence and geometric alignment, and ii) it can represent different plausible modes of the entire distribution of likely poses. This in turn allows for a more graceful treatment of geometric perception scenarios where establishing one-to-one matches between points is conceptually ill-defined, such as textureless, symmetrical and/or occluded objects and scenes where the correct pose is uncertain or there are multiple equally valid solutions.
PALMER: Perception-Action Loop with Memory for Long-Horizon Planning
Dec 08, 2022



To achieve autonomy in a priori unknown real-world scenarios, agents should be able to: i) act from high-dimensional sensory observations (e.g., images), ii) learn from past experience to adapt and improve, and iii) be capable of long horizon planning. Classical planning algorithms (e.g. PRM, RRT) are proficient at handling long-horizon planning. Deep learning based methods in turn can provide the necessary representations to address the others, by modeling statistical contingencies between observations. In this direction, we introduce a general-purpose planning algorithm called PALMER that combines classical sampling-based planning algorithms with learning-based perceptual representations. For training these perceptual representations, we combine Q-learning with contrastive representation learning to create a latent space where the distance between the embeddings of two states captures how easily an optimal policy can traverse between them. For planning with these perceptual representations, we re-purpose classical sampling-based planning algorithms to retrieve previously observed trajectory segments from a replay buffer and restitch them into approximately optimal paths that connect any given pair of start and goal states. This creates a tight feedback loop between representation learning, memory, reinforcement learning, and sampling-based planning. The end result is an experiential framework for long-horizon planning that is significantly more robust and sample efficient compared to existing methods.
Simple Control Baselines for Evaluating Transfer Learning
Feb 07, 2022



Transfer learning has witnessed remarkable progress in recent years, for example, with the introduction of augmentation-based contrastive self-supervised learning methods. While a number of large-scale empirical studies on the transfer performance of such models have been conducted, there is not yet an agreed-upon set of control baselines, evaluation practices, and metrics to report, which often hinders a nuanced and calibrated understanding of the real efficacy of the methods. We share an evaluation standard that aims to quantify and communicate transfer learning performance in an informative and accessible setup. This is done by baking a number of simple yet critical control baselines in the evaluation method, particularly the blind-guess (quantifying the dataset bias), scratch-model (quantifying the architectural contribution), and maximal-supervision (quantifying the upper-bound). To demonstrate how the evaluation standard can be employed, we provide an example empirical study investigating a few basic questions about self-supervised learning. For example, using this standard, the study shows the effectiveness of existing self-supervised pre-training methods is skewed towards image classification tasks versus dense pixel-wise predictions. In general, we encourage using/reporting the suggested control baselines in evaluating transfer learning in order to gain a more meaningful and informative understanding.
Scan Specific Artifact Reduction in K-space Neural Networks Synergize with Physics-based Reconstruction to Accelerate MRI
Apr 02, 2021
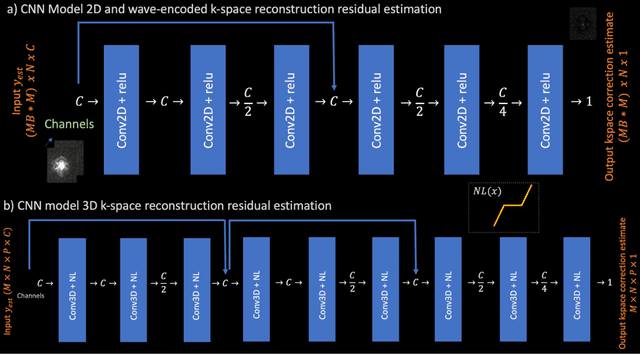
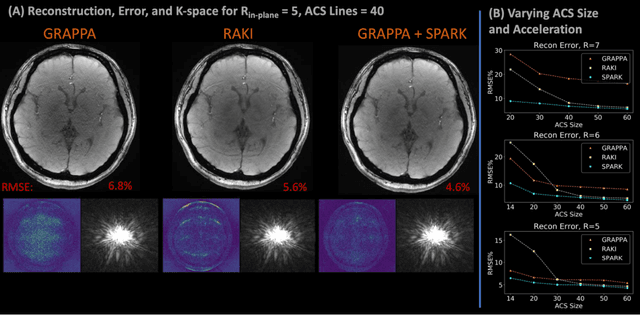
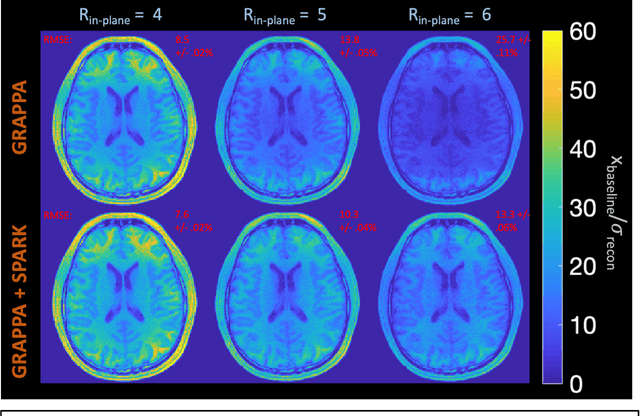
Purpose: To develop a scan-specific model that estimates and corrects k-space errors made when reconstructing accelerated Magnetic Resonance Imaging (MRI) data. Methods: Scan-Specific Artifact Reduction in k-space (SPARK) trains a convolutional neural network to estimate k-space errors made by an input reconstruction technique by back-propagating from the mean-squared-error loss between an auto-calibration signal (ACS) and the input technique's reconstructed ACS. First, SPARK is applied to GRAPPA and demonstrates improved robustness over other scan-specific models. Then, SPARK is shown to synergize with advanced reconstruction techniques by improving image quality when applied to 2D virtual coil (VC-) GRAPPA, 2D LORAKS, 3D GRAPPA without an integrated ACS region, and 2D/3D wave-encoded imaging. Results: SPARK yields 1.5 - 2x RMSE reduction when applied to GRAPPA and improves robustness to ACS size for various acceleration rates in comparison to other scan-specific techniques. When applied to advanced parallel imaging techniques such as 2D VC-GRAPPA and LORAKS, SPARK achieves up to 20% RMSE improvement. SPARK with 3D GRAPPA also improves RMSE performance and perceived image quality without a fully sampled ACS region. Finally, SPARK synergizes with non-cartesian, 2D and 3D wave-encoding imaging by reducing RMSE between 20 - 25% and providing qualitative improvements. Conclusion: SPARK synergizes with physics-based reconstruction techniques to improve accelerated MRI by training scan-specific models to estimate and correct reconstruction errors in k-space.