 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Large-Scale Multilingual Study of Visual Constraints on Linguistic Selection of Descriptions
Feb 09, 2023We present a large, multilingual study into how vision constrains linguistic choice, covering four languages and five linguistic properties, such as verb transitivity or use of numerals. We propose a novel method that leverages existing corpora of images with captions written by native speakers, and apply it to nine corpora, comprising 600k images and 3M captions. We study the relation between visual input and linguistic choices by training classifiers to predict the probability of expressing a property from raw images, and find evidence supporting the claim that linguistic properties are constrained by visual context across languages. We complement this investigation with a corpus study, taking the test case of numerals. Specifically, we use existing annotations (number or type of objects) to investigate the effect of different visual conditions on the use of numeral expressions in captions, and show that similar patterns emerge across languages. Our methods and findings both confirm and extend existing research in the cognitive literature. We additionally discuss possible applications for language generation.
Parallel Context Windows Improve In-Context Learning of Large Language Models
Dec 21, 2022



For applications that require processing large amounts of text at inference time, Large Language Models (LLMs) are handicapped by their limited context windows, which are typically 2048 tokens. In-context learning, an emergent phenomenon in LLMs in sizes above a certain parameter threshold, constitutes one significant example because it can only leverage training examples that fit into the context window. Existing efforts to address the context window limitation involve training specialized architectures, which tend to be smaller than the sizes in which in-context learning manifests due to the memory footprint of processing long texts. We present Parallel Context Windows (PCW), a method that alleviates the context window restriction for any off-the-shelf LLM without further training. The key to the approach is to carve a long context into chunks (``windows'') that fit within the architecture, restrict the attention mechanism to apply only within each window, and re-use the positional embeddings among the windows. We test the PCW approach on in-context learning with models that range in size between 750 million and 178 billion parameters, and show substantial improvements for tasks with diverse input and output spaces. Our results motivate further investigation of Parallel Context Windows as a method for applying off-the-shelf LLMs in other settings that require long text sequences.
Cognitive Simplification Operations Improve Text Simplification
Nov 16, 2022Text Simplification (TS) is the task of converting a text into a form that is easier to read while maintaining the meaning of the original text. A sub-task of TS is Cognitive Simplification (CS), converting text to a form that is readily understood by people with cognitive disabilities without rendering it childish or simplistic. This sub-task has yet to be explored with neural methods in NLP, and resources for it are scarcely available. In this paper, we present a method for incorporating knowledge from the cognitive accessibility domain into a TS model, by introducing an inductive bias regarding what simplification operations to use. We show that by adding this inductive bias to a TS-trained model, it is able to adapt better to CS without ever seeing CS data, and outperform a baseline model on a traditional TS benchmark. In addition, we provide a novel test dataset for CS, and analyze the differences between CS corpora and existing TS corpora, in terms of how simplification operations are applied.
DisentQA: Disentangling Parametric and Contextual Knowledge with Counterfactual Question Answering
Nov 10, 2022Question answering models commonly have access to two sources of "knowledge" during inference time: (1) parametric knowledge - the factual knowledge encoded in the model weights, and (2) contextual knowledge - external knowledge (e.g., a Wikipedia passage) given to the model to generate a grounded answer. Having these two sources of knowledge entangled together is a core issue for generative QA models as it is unclear whether the answer stems from the given non-parametric knowledge or not. This unclarity has implications on issues of trust, interpretability and factuality. In this work, we propose a new paradigm in which QA models are trained to disentangle the two sources of knowledge. Using counterfactual data augmentation, we introduce a model that predicts two answers for a given question: one based on given contextual knowledge and one based on parametric knowledge. Our experiments on the Natural Questions dataset show that this approach improves the performance of QA models by making them more robust to knowledge conflicts between the two knowledge sources, while generating useful disentangled answers.
Topical Segmentation of Spoken Narratives: A Test Case on Holocaust Survivor Testimonies
Oct 25, 2022


The task of topical segmentation is well studied, but previous work has mostly addressed it in the context of structured, well-defined segments, such as segmentation into paragraphs, chapters, or segmenting text that originated from multiple sources. We tackle the task of segmenting running (spoken) narratives, which poses hitherto unaddressed challenges. As a test case, we address Holocaust survivor testimonies, given in English. Other than the importance of studying these testimonies for Holocaust research, we argue that they provide an interesting test case for topical segmentation, due to their unstructured surface level, relative abundance (tens of thousands of such testimonies were collected), and the relatively confined domain that they cover. We hypothesize that boundary points between segments correspond to low mutual information between the sentences proceeding and following the boundary. Based on this hypothesis, we explore a range of algorithmic approaches to the task, building on previous work on segmentation that uses generative Bayesian modeling and state-of-the-art neural machinery. Compared to manually annotated references, we find that the developed approaches show considerable improvements over previous work.
Reinforcement Learning with Large Action Spaces for Neural Machine Translation
Oct 06, 2022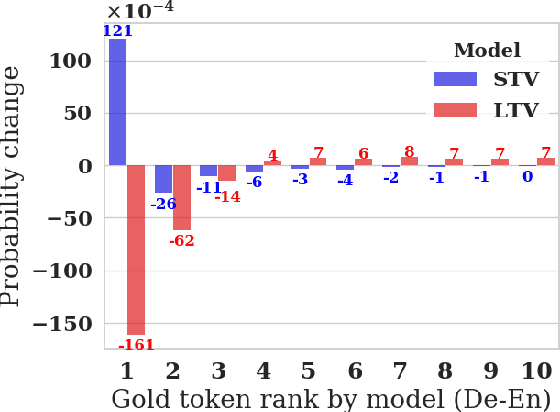
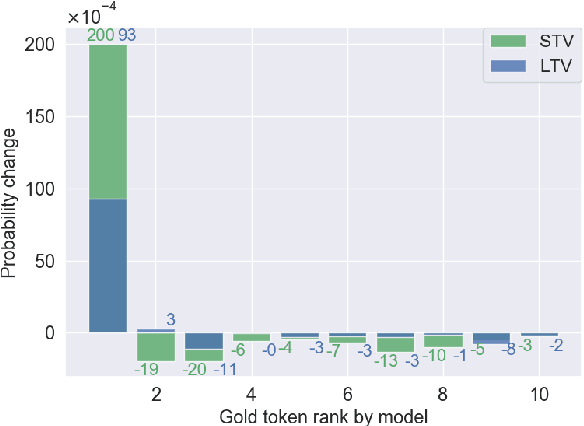
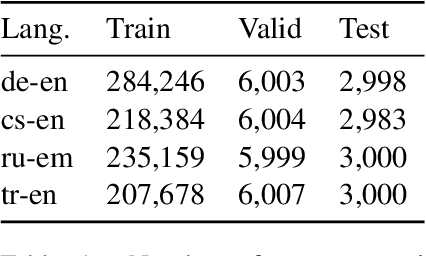
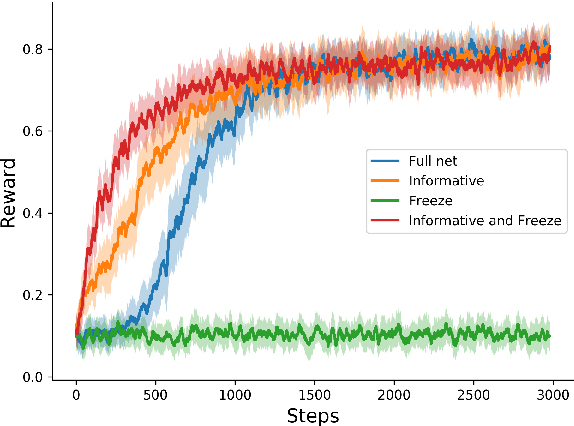
Applying Reinforcement learning (RL) following maximum likelihood estimation (MLE) pre-training is a versatile method for enhancing neural machine translation (NMT) performance. However, recent work has argued that the gains produced by RL for NMT are mostly due to promoting tokens that have already received a fairly high probability in pre-training. We hypothesize that the large action space is a main obstacle to RL's effectiveness in MT, and conduct two sets of experiments that lend support to our hypothesis. First, we find that reducing the size of the vocabulary improves RL's effectiveness. Second, we find that effectively reducing the dimension of the action space without changing the vocabulary also yields notable improvement as evaluated by BLEU, semantic similarity, and human evaluation. Indeed, by initializing the network's final fully connected layer (that maps the network's internal dimension to the vocabulary dimension), with a layer that generalizes over similar actions, we obtain a substantial improvement in RL performance: 1.5 BLEU points on average.
PreQuEL: Quality Estimation of Machine Translation Outputs in Advance
May 18, 2022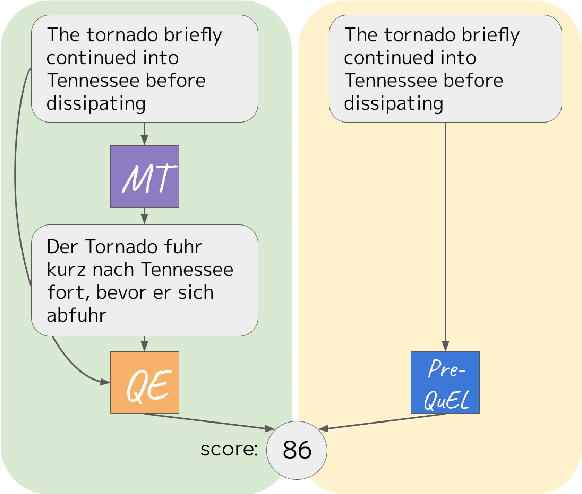
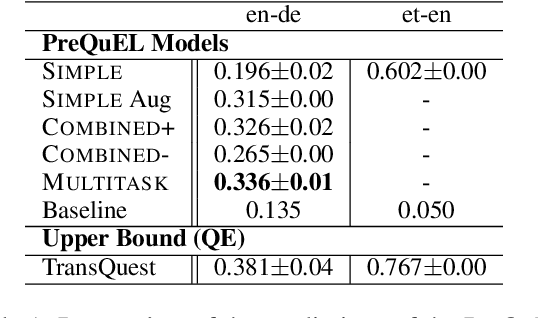
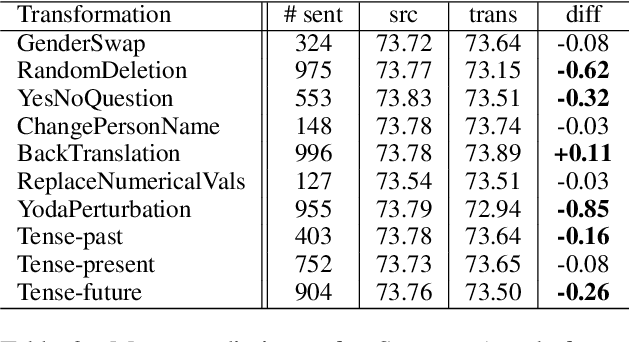
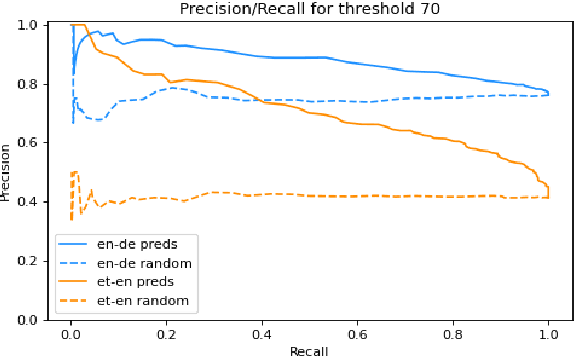
We present the task of PreQuEL, Pre-(Quality-Estimation) Learning. A PreQuEL system predicts how well a given sentence will be translated, without recourse to the actual translation, thus eschewing unnecessary resource allocation when translation quality is bound to be low. PreQuEL can be defined relative to a given MT system (e.g., some industry service) or generally relative to the state-of-the-art. From a theoretical perspective, PreQuEL places the focus on the source text, tracing properties, possibly linguistic features, that make a sentence harder to machine translate. We develop a baseline model for the task and analyze its performance. We also develop a data augmentation method (from parallel corpora), that improves results substantially. We show that this augmentation method can improve the performance of the Quality-Estimation task as well. We investigate the properties of the input text that our model is sensitive to, by testing it on challenge sets and different languages. We conclude that it is aware of syntactic and semantic distinctions, and correlates and even over-emphasizes the importance of standard NLP features.
A Computational Acquisition Model for Multimodal Word Categorization
May 12, 2022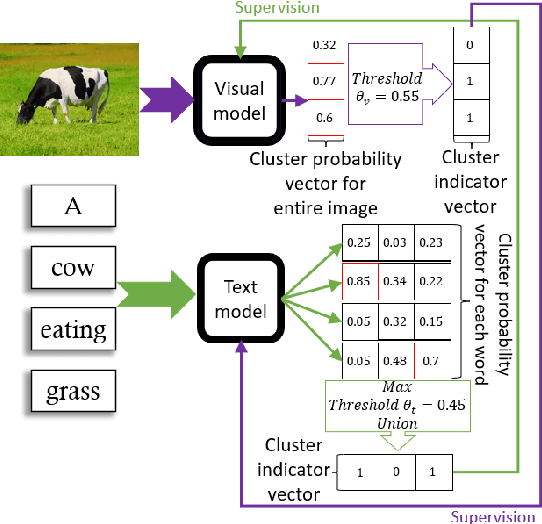

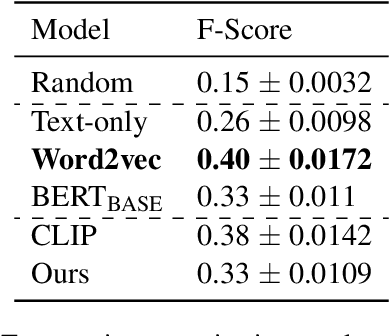
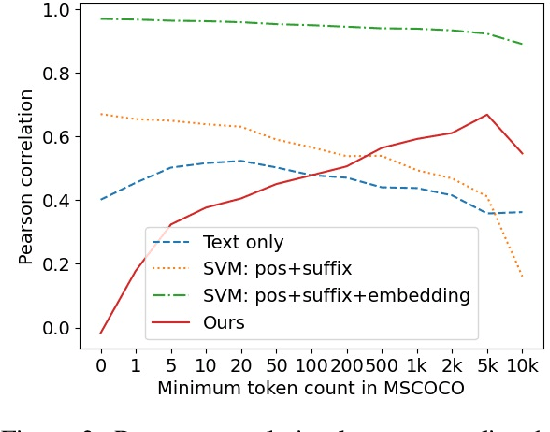
Recent advances in self-supervised modeling of text and images open new opportunities for computational models of child language acquisition, which is believed to rely heavily on cross-modal signals. However, prior studies have been limited by their reliance on vision models trained on large image datasets annotated with a pre-defined set of depicted object categories. This is (a) not faithful to the information children receive and (b) prohibits the evaluation of such models with respect to category learning tasks, due to the pre-imposed category structure. We address this gap, and present a cognitively-inspired, multimodal acquisition model, trained from image-caption pairs on naturalistic data using cross-modal self-supervision. We show that the model learns word categories and object recognition abilities, and presents trends reminiscent of those reported in the developmental literature. We make our code and trained models public for future reference and use.
Some Grammatical Errors are Frequent, Others are Important
May 11, 2022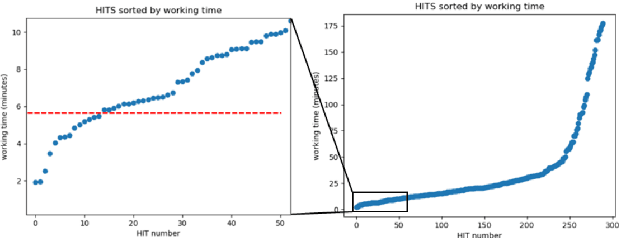
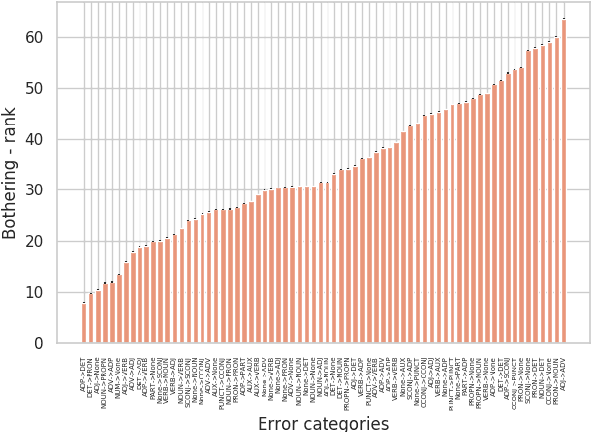
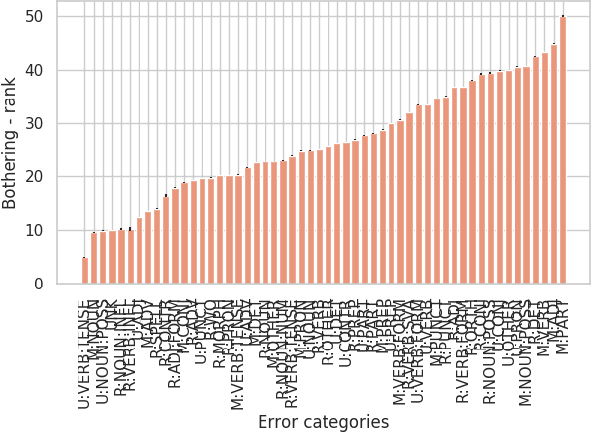
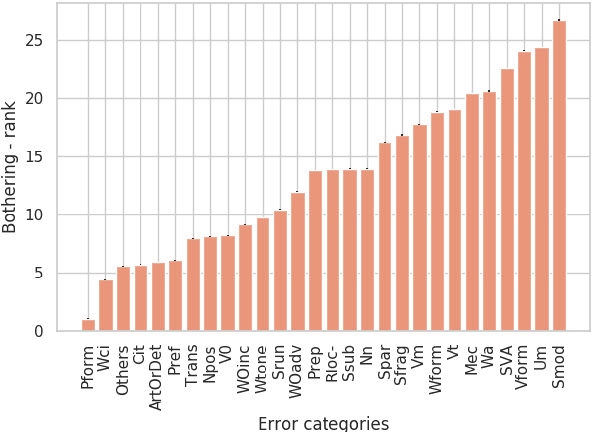
In Grammatical Error Correction, systems are evaluated by the number of errors they correct. However, no one has assessed whether all error types are equally important. We provide and apply a method to quantify the importance of different grammatical error types to humans. We show that some rare errors are considered disturbing while other common ones are not. This affects possible directions to improve both systems and their evaluation.
MRKL Systems: A modular, neuro-symbolic architecture that combines large language models, external knowledge sources and discrete reasoning
May 01, 2022
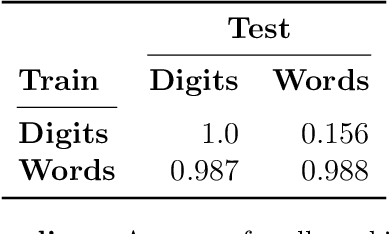

Huge language models (LMs) have ushered in a new era for AI, serving as a gateway to natural-language-based knowledge tasks. Although an essential element of modern AI, LMs are also inherently limited in a number of ways. We discuss these limitations and how they can be avoided by adopting a systems approach. Conceptualizing the challenge as one that involves knowledge and reasoning in addition to linguistic processing, we define a flexible architecture with multiple neural models, complemented by discrete knowledge and reasoning modules. We describe this neuro-symbolic architecture, dubbed the Modular Reasoning, Knowledge and Language (MRKL, pronounced "miracle") system, some of the technical challenges in implementing it, and Jurassic-X, AI21 Labs' MRKL system implementation.