 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Large ASR Encoders with Differential Privacy
Sep 21, 2024



Self-supervised learning (SSL) methods for large speech models have proven to be highly effective at ASR. With the interest in public deployment of large pre-trained models, there is a rising concern for unintended memorization and leakage of sensitive data points from the training data. In this paper, we apply differentially private (DP) pre-training to a SOTA Conformer-based encoder, and study its performance on a downstream ASR task assuming the fine-tuning data is public. This paper is the first to apply DP to SSL for ASR, investigating the DP noise tolerance of the BEST-RQ pre-training method. Notably, we introduce a novel variant of model pruning called gradient-based layer freezing that provides strong improvements in privacy-utility-compute trade-offs. Our approach yields a LibriSpeech test-clean/other WER (%) of 3.78/ 8.41 with ($10$, 1e^-9)-DP for extrapolation towards low dataset scales, and 2.81/ 5.89 with (10, 7.9e^-11)-DP for extrapolation towards high scales.
Efficiently Train ASR Models that Memorize Less and Perform Better with Per-core Clipping
Jun 04, 2024Gradient clipping plays a vital role in training large-scale automatic speech recognition (ASR) models. It is typically applied to minibatch gradients to prevent gradient explosion, and to the individual sample gradients to mitigate unintended memorization. This work systematically investigates the impact of a specific granularity of gradient clipping, namely per-core clip-ping (PCC), across training a wide range of ASR models. We empirically demonstrate that PCC can effectively mitigate unintended memorization in ASR models. Surprisingly, we find that PCC positively influences ASR performance metrics, leading to improved convergence rates and reduced word error rates. To avoid tuning the additional hyperparameter introduced by PCC, we further propose a novel variant, adaptive per-core clipping (APCC), for streamlined optimization. Our findings highlight the multifaceted benefits of PCC as a strategy for robust, privacy-forward ASR model training.
Noise Masking Attacks and Defenses for Pretrained Speech Models
Apr 02, 2024Speech models are often trained on sensitive data in order to improve model performance, leading to potential privacy leakage. Our work considers noise masking attacks, introduced by Amid et al. 2022, which attack automatic speech recognition (ASR) models by requesting a transcript of an utterance which is partially replaced with noise. They show that when a record has been seen at training time, the model will transcribe the noisy record with its memorized sensitive transcript. In our work, we extend these attacks beyond ASR models, to attack pretrained speech encoders. Our method fine-tunes the encoder to produce an ASR model, and then performs noise masking on this model, which we find recovers private information from the pretraining data, despite the model never having seen transcripts at pretraining time! We show how to improve the precision of these attacks and investigate a number of countermeasures to our attacks.
Unintended Memorization in Large ASR Models, and How to Mitigate It
Oct 18, 2023



It is well-known that neural networks can unintentionally memorize their training examples, causing privacy concerns. However, auditing memorization in large non-auto-regressive automatic speech recognition (ASR) models has been challenging due to the high compute cost of existing methods such as hardness calibration. In this work, we design a simple auditing method to measure memorization in large ASR models without the extra compute overhead. Concretely, we speed up randomly-generated utterances to create a mapping between vocal and text information that is difficult to learn from typical training examples. Hence, accurate predictions only for sped-up training examples can serve as clear evidence for memorization, and the corresponding accuracy can be used to measure memorization. Using the proposed method, we showcase memorization in the state-of-the-art ASR models. To mitigate memorization, we tried gradient clipping during training to bound the influence of any individual example on the final model. We empirically show that clipping each example's gradient can mitigate memorization for sped-up training examples with up to 16 repetitions in the training set. Furthermore, we show that in large-scale distributed training, clipping the average gradient on each compute core maintains neutral model quality and compute cost while providing strong privacy protection.
Why Is Public Pretraining Necessary for Private Model Training?
Feb 19, 2023In the privacy-utility tradeoff of a model trained on benchmark language and vision tasks, remarkable improvements have been widely reported with the use of pretraining on publicly available data. This is in part due to the benefits of transfer learning, which is the standard motivation for pretraining in non-private settings. However, the stark contrast in the improvement achieved through pretraining under privacy compared to non-private settings suggests that there may be a deeper, distinct cause driving these gains. To explain this phenomenon, we hypothesize that the non-convex loss landscape of a model training necessitates an optimization algorithm to go through two phases. In the first, the algorithm needs to select a good "basin" in the loss landscape. In the second, the algorithm solves an easy optimization within that basin. The former is a harder problem to solve with private data, while the latter is harder to solve with public data due to a distribution shift or data scarcity. Guided by this intuition, we provide theoretical constructions that provably demonstrate the separation between private training with and without public pretraining. Further, systematic experiments on CIFAR10 and LibriSpeech provide supporting evidence for our hypothesis.
Recycling Scraps: Improving Private Learning by Leveraging Intermediate Checkpoints
Oct 04, 2022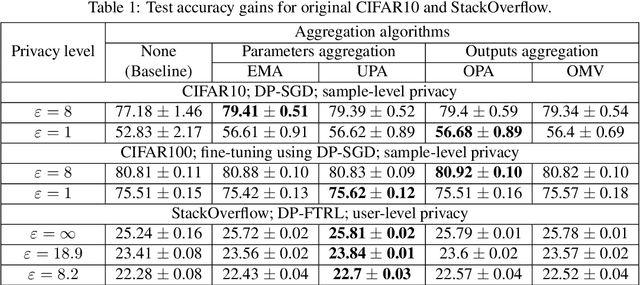
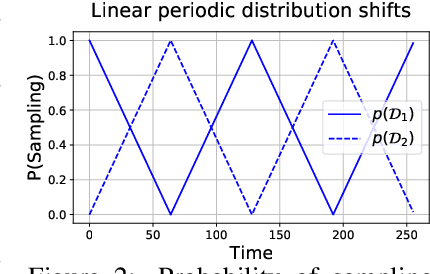
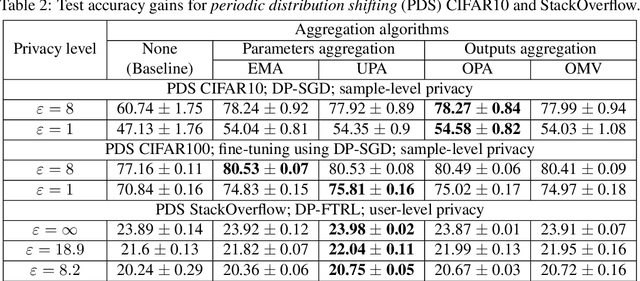
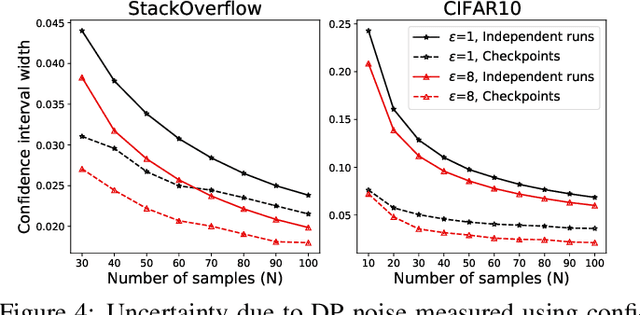
All state-of-the-art (SOTA) differentially private machine learning (DP ML) methods are iterative in nature, and their privacy analyses allow publicly releasing the intermediate training checkpoints. However, DP ML benchmarks, and even practical deployments, typically use only the final training checkpoint to make predictions. In this work, for the first time, we comprehensively explore various methods that aggregate intermediate checkpoints to improve the utility of DP training. Empirically, we demonstrate that checkpoint aggregations provide significant gains in the prediction accuracy over the existing SOTA for CIFAR10 and StackOverflow datasets, and that these gains get magnified in settings with periodically varying training data distributions. For instance, we improve SOTA StackOverflow accuracies to 22.7% (+0.43% absolute) for $\epsilon=8.2$, and 23.84% (+0.43%) for $\epsilon=18.9$. Theoretically, we show that uniform tail averaging of checkpoints improves the empirical risk minimization bound compared to the last checkpoint of DP-SGD. Lastly, we initiate an exploration into estimating the uncertainty that DP noise adds in the predictions of DP ML models. We prove that, under standard assumptions on the loss function, the sample variance from last few checkpoints provides a good approximation of the variance of the final model of a DP run. Empirically, we show that the last few checkpoints can provide a reasonable lower bound for the variance of a converged DP model.
Measuring Forgetting of Memorized Training Examples
Jun 30, 2022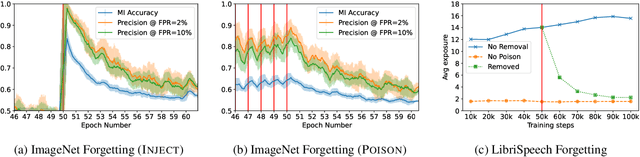
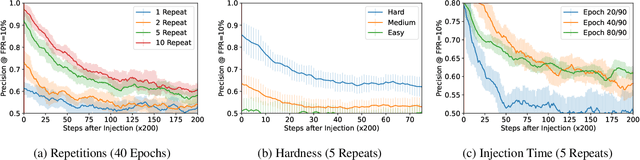
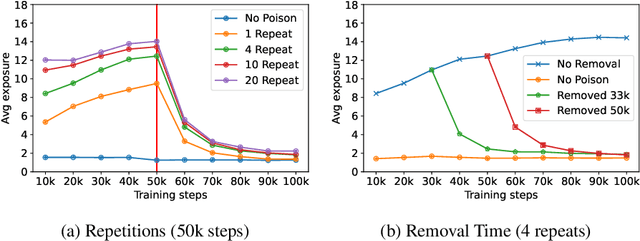
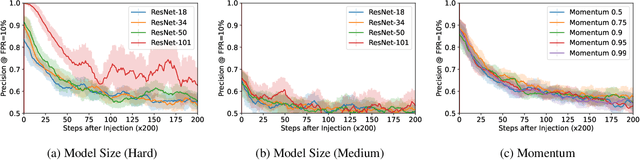
Machine learning models exhibit two seemingly contradictory phenomena: training data memorization and various forms of forgetting. In memorization, models overfit specific training examples and become susceptible to privacy attacks. In forgetting, examples which appeared early in training are forgotten by the end. In this work, we connect these phenomena. We propose a technique to measure to what extent models ``forget'' the specifics of training examples, becoming less susceptible to privacy attacks on examples they have not seen recently. We show that, while non-convexity can prevent forgetting from happening in the worst-case, standard image and speech models empirically do forget examples over time. We identify nondeterminism as a potential explanation, showing that deterministically trained models do not forget. Our results suggest that examples seen early when training with extremely large datasets -- for instance those examples used to pre-train a model -- may observe privacy benefits at the expense of examples seen later.
Detecting Unintended Memorization in Language-Model-Fused ASR
Apr 20, 2022
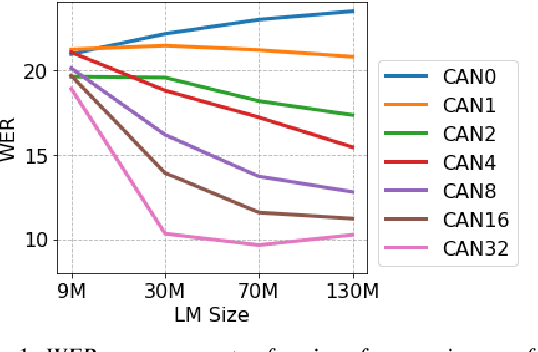
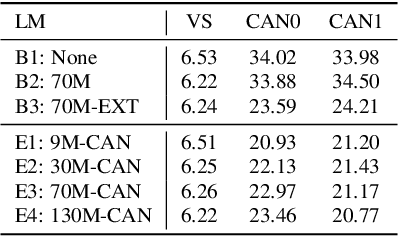
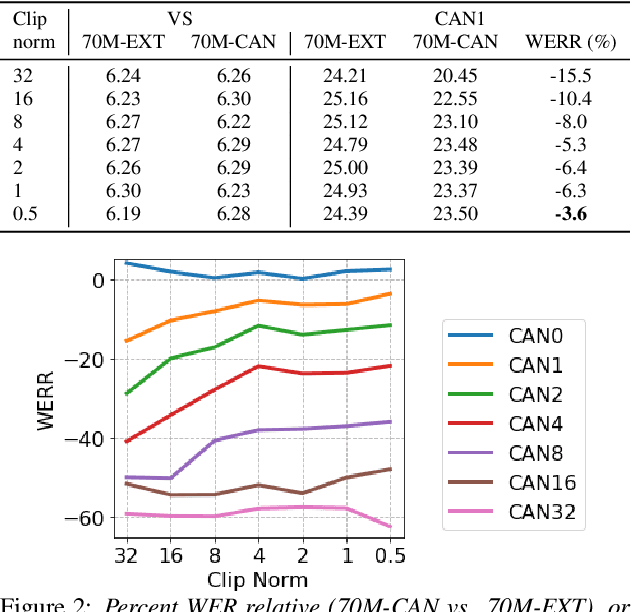
End-to-end (E2E) models are often being accompanied by language models (LMs) via shallow fusion for boosting their overall quality as well as recognition of rare words. At the same time, several prior works show that LMs are susceptible to unintentionally memorizing rare or unique sequences in the training data. In this work, we design a framework for detecting memorization of random textual sequences (which we call canaries) in the LM training data when one has only black-box (query) access to LM-fused speech recognizer, as opposed to direct access to the LM. On a production-grade Conformer RNN-T E2E model fused with a Transformer LM, we show that detecting memorization of singly-occurring canaries from the LM training data of 300M examples is possible. Motivated to protect privacy, we also show that such memorization gets significantly reduced by per-example gradient-clipped LM training without compromising overall quality.
Extracting Targeted Training Data from ASR Models, and How to Mitigate It
Apr 18, 2022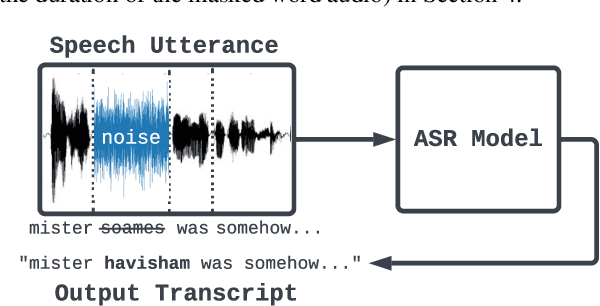
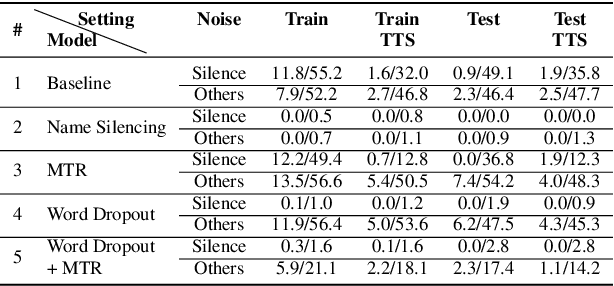
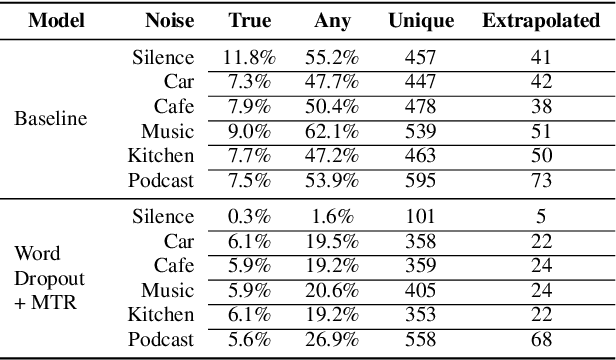
Recent work has designed methods to demonstrate that model updates in ASR training can leak potentially sensitive attributes of the utterances used in computing the updates. In this work, we design the first method to demonstrate information leakage about training data from trained ASR models. We design Noise Masking, a fill-in-the-blank style method for extracting targeted parts of training data from trained ASR models. We demonstrate the success of Noise Masking by using it in four settings for extracting names from the LibriSpeech dataset used for training a SOTA Conformer model. In particular, we show that we are able to extract the correct names from masked training utterances with 11.8% accuracy, while the model outputs some name from the train set 55.2% of the time. Further, we show that even in a setting that uses synthetic audio and partial transcripts from the test set, our method achieves 2.5% correct name accuracy (47.7% any name success rate). Lastly, we design Word Dropout, a data augmentation method that we show when used in training along with MTR, provides comparable utility as the baseline, along with significantly mitigating extraction via Noise Masking across the four evaluated settings.
Public Data-Assisted Mirror Descent for Private Model Training
Dec 01, 2021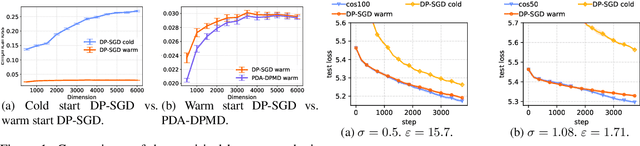
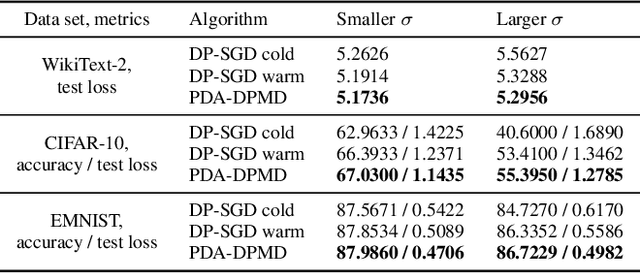

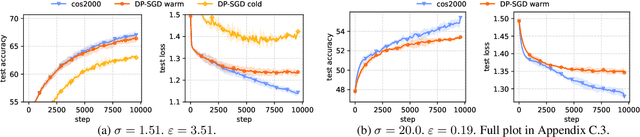
We revisit the problem of using public data to improve the privacy/utility trade-offs for differentially private (DP) model training. Here, public data refers to auxiliary data sets that have no privacy concerns. We consider public data that is from the same distribution as the private training data. For convex losses, we show that a variant of Mirror Descent provides population risk guarantees which are independent of the dimension of the model ($p$). Specifically, we apply Mirror Descent with the loss generated by the public data as the mirror map, and using DP gradients of the loss generated by the private (sensitive) data. To obtain dimension independence, we require $G_Q^2 \leq p$ public data samples, where $G_Q$ is a measure of the isotropy of the loss function. We further show that our algorithm has a natural ``noise stability'' property: If around the current iterate the public loss satisfies $\alpha_v$-strong convexity in a direction $v$, then using noisy gradients instead of the exact gradients shifts our next iterate in the direction $v$ by an amount proportional to $1/\alpha_v$ (in contrast with DP-SGD, where the shift is isotropic). Analogous results in prior works had to explicitly learn the geometry using the public data in the form of preconditioner matrices. Our method is also applicable to non-convex losses, as it does not rely on convexity assumptions to ensure DP guarantees. We demonstrate the empirical efficacy of our algorithm by showing privacy/utility trade-offs on linear regression, deep learning benchmark datasets (WikiText-2, CIFAR-10, and EMNIST), and in federated learning (StackOverflow). We show that our algorithm not only significantly improves over traditional DP-SGD and DP-FedAvg, which do not have access to public data, but also improves over DP-SGD and DP-FedAvg on models that have been pre-trained with the public data to begin with.