 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Power Analyses: Empirical Evaluation and Application to Cognitive Neuroimaging
Oct 11, 2022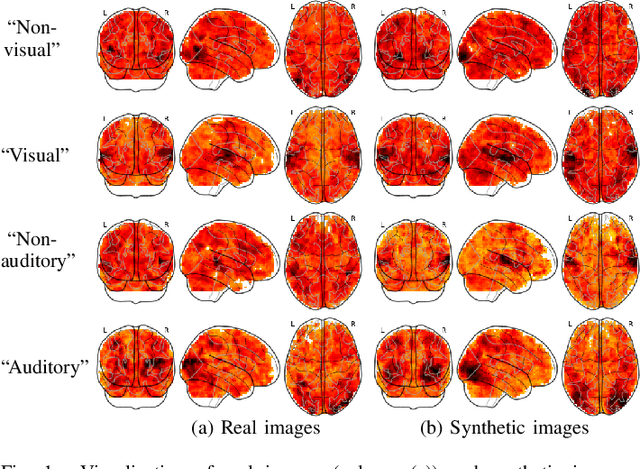
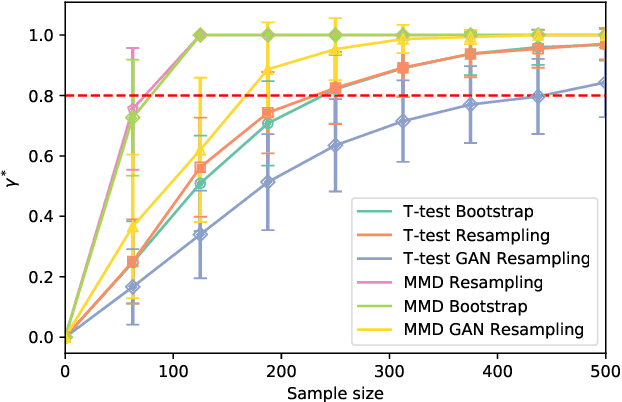
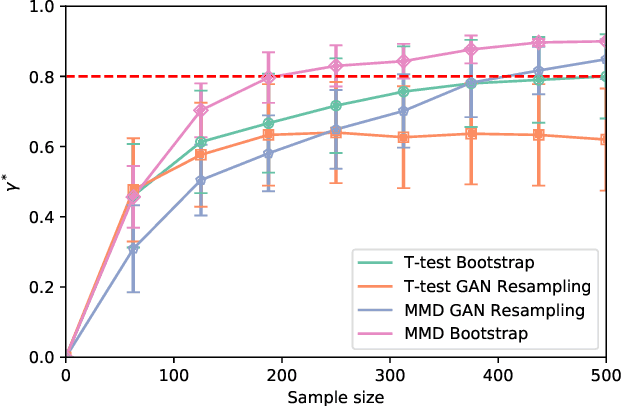
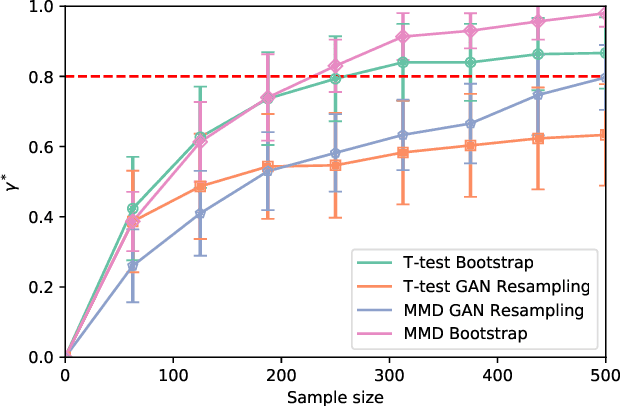
In the experimental sciences, statistical power analyses are often used before data collection to determine the required sample size. However, traditional power analyses can be costly when data are difficult or expensive to collect. We propose synthetic power analyses; a framework for estimating statistical power at various sample sizes, and empirically explore the performance of synthetic power analysis for sample size selection in cognitive neuroscience experiments. To this end, brain imaging data is synthesized using an implicit generative model conditioned on observed cognitive processes. Further, we propose a simple procedure to modify the statistical tests which result in conservative statistics. Our empirical results suggest that synthetic power analysis could be a low-cost alternative to pilot data collection when the proposed experiments share cognitive processes with previously conducted experiments.
A Reduction to Binary Approach for Debiasing Multiclass Datasets
May 31, 2022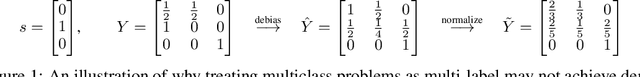
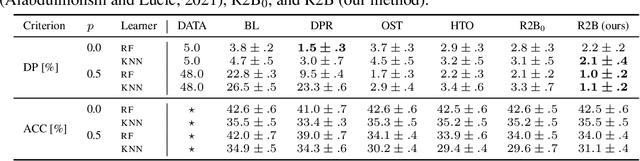
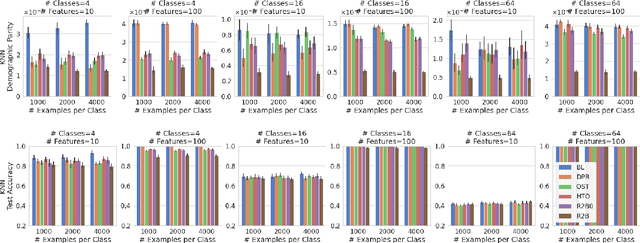

We propose a novel reduction-to-binary (R2B) approach that enforces demographic parity for multiclass classification with non-binary sensitive attributes via a reduction to a sequence of binary debiasing tasks. We prove that R2B satisfies optimality and bias guarantees and demonstrate empirically that it can lead to an improvement over two baselines: (1) treating multiclass problems as multi-label by debiasing labels independently and (2) transforming the features instead of the labels. Surprisingly, we also demonstrate that independent label debiasing yields competitive results in most (but not all) settings. We validate these conclusions on synthetic and real-world datasets from social science, computer vision, and healthcare.
Adversarially Robust Models may not Transfer Better: Sufficient Conditions for Domain Transferability from the View of Regularization
Feb 03, 2022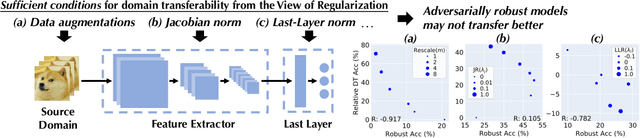
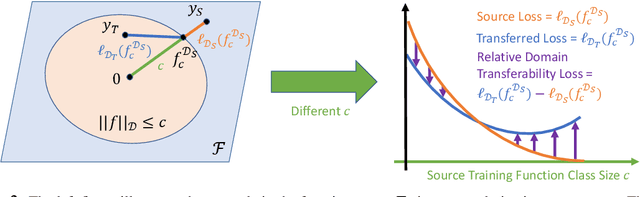
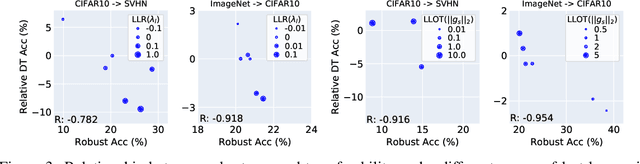
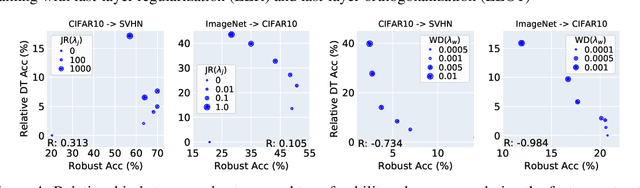
Machine learning (ML) robustness and domain generalization are fundamentally correlated: they essentially concern data distribution shifts under adversarial and natural settings, respectively. On one hand, recent studies show that more robust (adversarially trained) models are more generalizable. On the other hand, there is a lack of theoretical understanding of their fundamental connections. In this paper, we explore the relationship between regularization and domain transferability considering different factors such as norm regularization and data augmentations (DA). We propose a general theoretical framework proving that factors involving the model function class regularization are sufficient conditions for relative domain transferability. Our analysis implies that "robustness" is neither necessary nor sufficient for transferability; rather, robustness induced by adversarial training is a by-product of such function class regularization. We then discuss popular DA protocols and show when they can be viewed as the function class regularization under certain conditions and therefore improve generalization. We conduct extensive experiments to verify our theoretical findings and show several counterexamples where robustness and generalization are negatively correlated on different datasets.
Maintaining fairness across distribution shift: do we have viable solutions for real-world applications?
Feb 02, 2022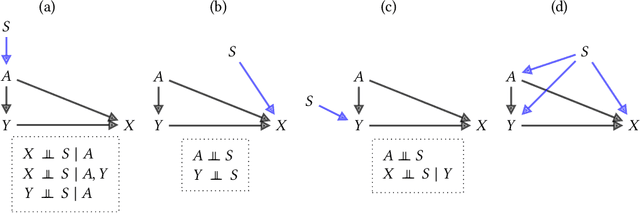
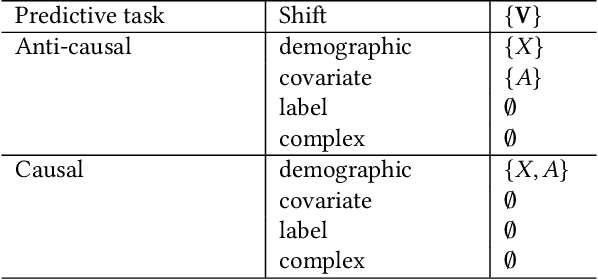
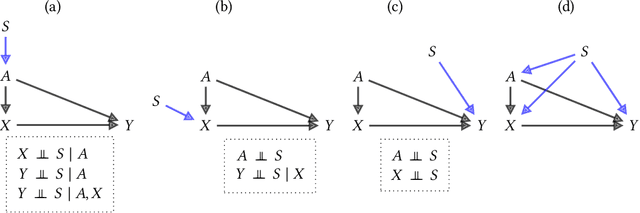
Fairness and robustness are often considered as orthogonal dimensions when evaluating machine learning models. However, recent work has revealed interactions between fairness and robustness, showing that fairness properties are not necessarily maintained under distribution shift. In healthcare settings, this can result in e.g. a model that performs fairly according to a selected metric in "hospital A" showing unfairness when deployed in "hospital B". While a nascent field has emerged to develop provable fair and robust models, it typically relies on strong assumptions about the shift, limiting its impact for real-world applications. In this work, we explore the settings in which recently proposed mitigation strategies are applicable by referring to a causal framing. Using examples of predictive models in dermatology and electronic health records, we show that real-world applications are complex and often invalidate the assumptions of such methods. Our work hence highlights technical, practical, and engineering gaps that prevent the development of robustly fair machine learning models for real-world applications. Finally, we discuss potential remedies at each step of the machine learning pipeline.
Joint Gaussian Graphical Model Estimation: A Survey
Oct 19, 2021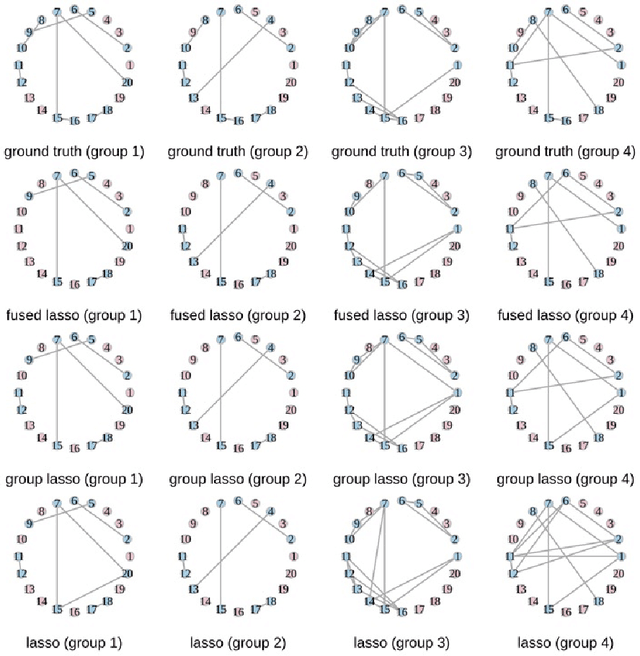
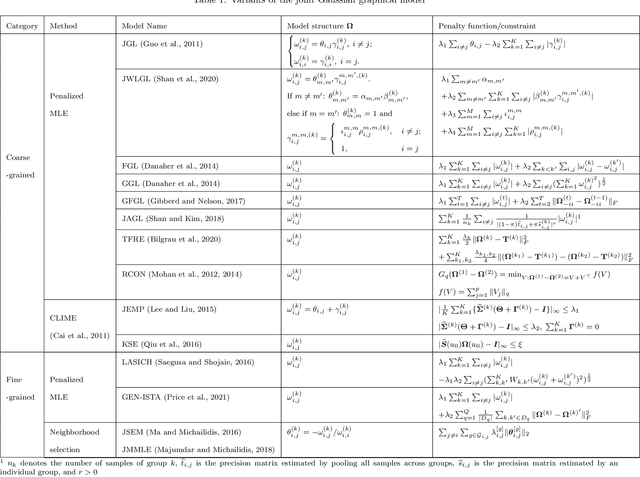
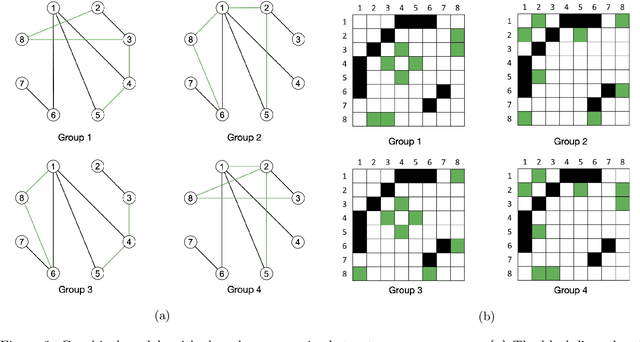

Graphs from complex systems often share a partial underlying structure across domains while retaining individual features. Thus, identifying common structures can shed light on the underlying signal, for instance, when applied to scientific discoveries or clinical diagnoses. Furthermore, growing evidence shows that the shared structure across domains boosts the estimation power of graphs, particularly for high-dimensional data. However, building a joint estimator to extract the common structure may be more complicated than it seems, most often due to data heterogeneity across sources. This manuscript surveys recent work on statistical inference of joint Gaussian graphical models, identifying model structures that fit various data generation processes. Simulations under different data generation processes are implemented with detailed discussions on the choice of models.
Secure Byzantine-Robust Distributed Learning via Clustering
Oct 06, 2021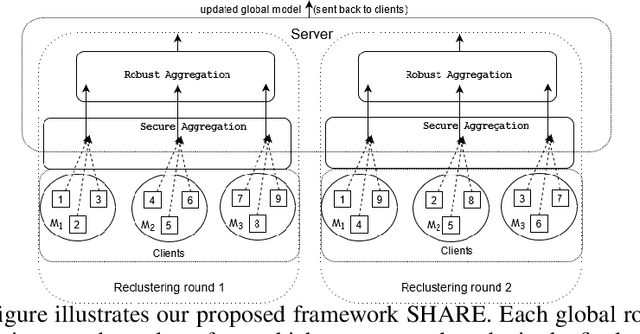
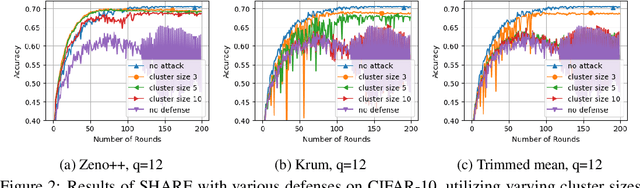
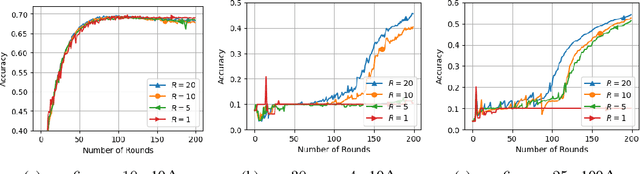
Federated learning systems that jointly preserve Byzantine robustness and privacy have remained an open problem. Robust aggregation, the standard defense for Byzantine attacks, generally requires server access to individual updates or nonlinear computation -- thus is incompatible with privacy-preserving methods such as secure aggregation via multiparty computation. To this end, we propose SHARE (Secure Hierarchical Robust Aggregation), a distributed learning framework designed to cryptographically preserve client update privacy and robustness to Byzantine adversaries simultaneously. The key idea is to incorporate secure averaging among randomly clustered clients before filtering malicious updates through robust aggregation. Experiments show that SHARE has similar robustness guarantees as existing techniques while enhancing privacy.
Optimizing Black-box Metrics with Iterative Example Weighting
Feb 18, 2021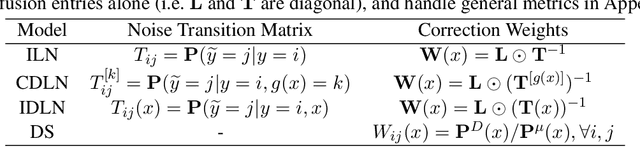
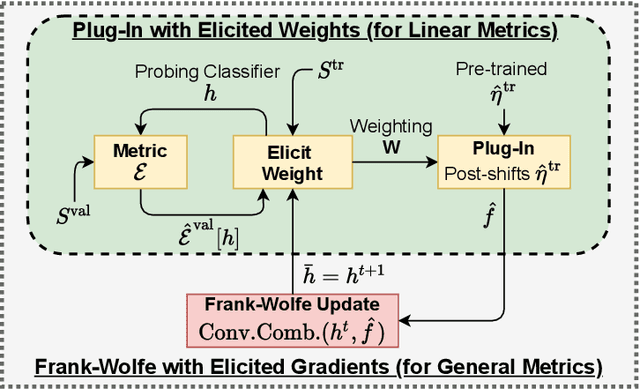
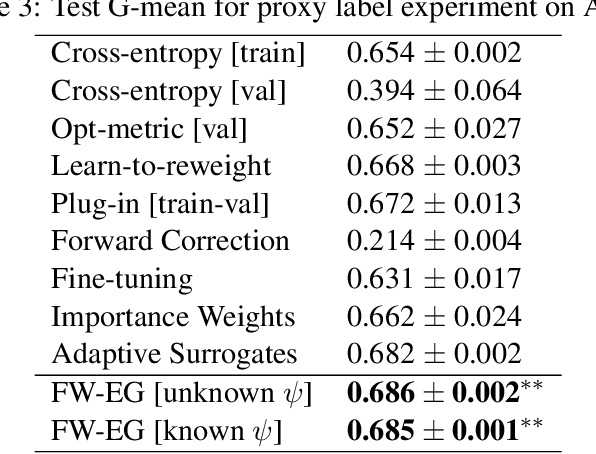
We consider learning to optimize a classification metric defined by a black-box function of the confusion matrix. Such black-box learning settings are ubiquitous, for example, when the learner only has query access to the metric of interest, or in noisy-label and domain adaptation applications where the learner must evaluate the metric via performance evaluation using a small validation sample. Our approach is to adaptively learn example weights on the training dataset such that the resulting weighted objective best approximates the metric on the validation sample. We show how to model and estimate the example weights and use them to iteratively post-shift a pre-trained class probability estimator to construct a classifier. We also analyze the resulting procedure's statistical properties. Experiments on various label noise, domain shift, and fair classification setups confirm that our proposal is better than the individual state-of-the-art baselines for each application.
Enjoy Your Editing: Controllable GANs for Image Editing via Latent Space Navigation
Feb 03, 2021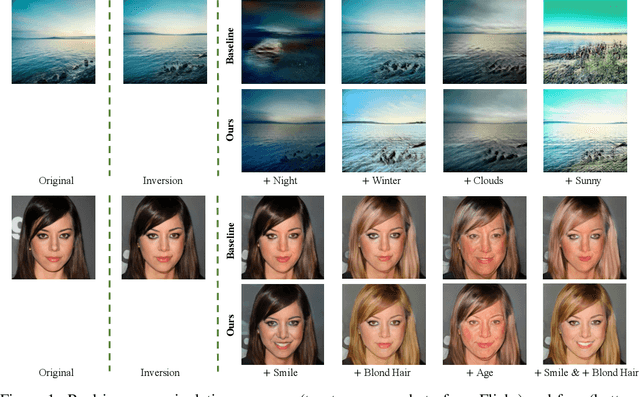
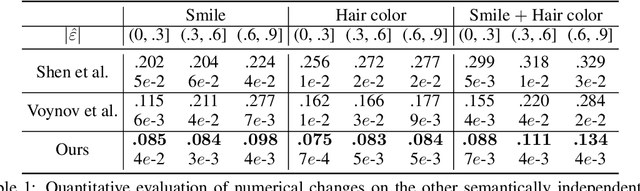
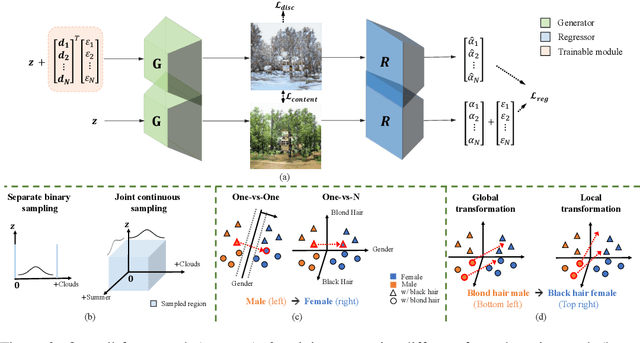
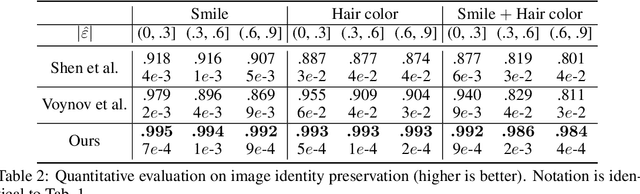
Controllable semantic image editing enables a user to change entire image attributes with few clicks, e.g., gradually making a summer scene look like it was taken in winter. Classic approaches for this task use a Generative Adversarial Net (GAN) to learn a latent space and suitable latent-space transformations. However, current approaches often suffer from attribute edits that are entangled, global image identity changes, and diminished photo-realism. To address these concerns, we learn multiple attribute transformations simultaneously, we integrate attribute regression into the training of transformation functions, apply a content loss and an adversarial loss that encourage the maintenance of image identity and photo-realism. We propose quantitative evaluation strategies for measuring controllable editing performance, unlike prior work which primarily focuses on qualitative evaluation. Our model permits better control for both single- and multiple-attribute editing, while also preserving image identity and realism during transformation. We provide empirical results for both real and synthetic images, highlighting that our model achieves state-of-the-art performance for targeted image manipulation.
A Nonconvex Framework for Structured Dynamic Covariance Recovery
Nov 11, 2020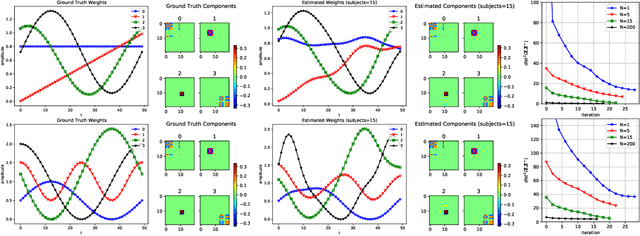
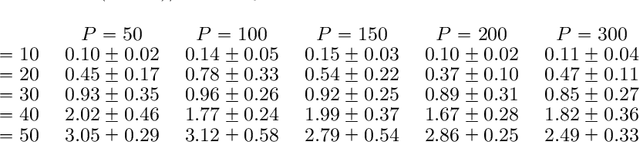
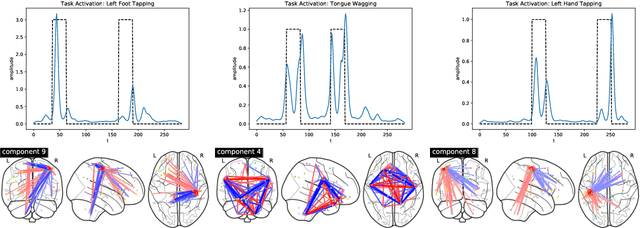
We propose a flexible yet interpretable model for high-dimensional data with time-varying second order statistics, motivated and applied to functional neuroimaging data. Motivated by the neuroscience literature, we factorize the covariances into sparse spatial and smooth temporal components. While this factorization results in both parsimony and domain interpretability, the resulting estimation problem is nonconvex. To this end, we design a two-stage optimization scheme with a carefully tailored spectral initialization, combined with iteratively refined alternating projected gradient descent. We prove a linear convergence rate up to a nontrivial statistical error for the proposed descent scheme and establish sample complexity guarantees for the estimator. We further quantify the statistical error for the multivariate Gaussian case. Empirical results using simulated and real brain imaging data illustrate that our approach outperforms existing baselines.
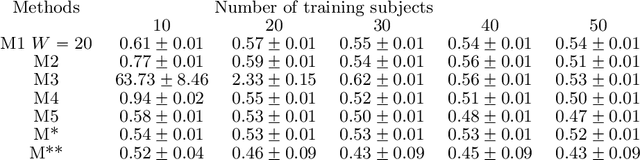
Quadratic Metric Elicitation with Application to Fairness
Nov 03, 2020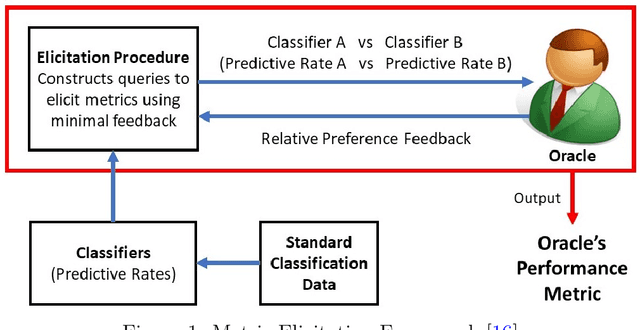
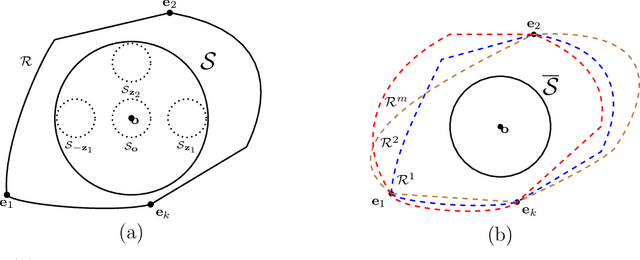
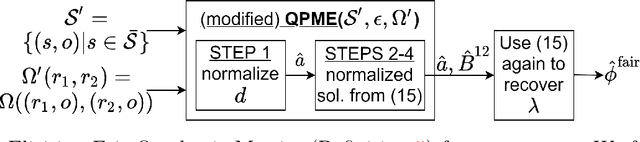
Metric elicitation is a recent framework for eliciting performance metrics that best reflect implicit user preferences. This framework enables a practitioner to adjust the performance metrics based on the application, context, and population at hand. However, available elicitation strategies have been limited to linear (or fractional-linear) functions of predictive rates. In this paper, we develop an approach to elicit from a wider range of complex multiclass metrics defined by quadratic functions of rates by exploiting their local linear structure. We apply this strategy to elicit quadratic metrics for group-based fairness, and also discuss how it can be generalized to higher-order polynomials. Our elicitation strategies require only relative preference feedback and are robust to both feedback and finite sample noise.