 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle-shot ToF sensing with sub-mm precision using conventional CMOS sensors
Dec 02, 2022We present a novel single-shot interferometric ToF camera targeted for precise 3D measurements of dynamic objects. The camera concept is based on Synthetic Wavelength Interferometry, a technique that allows retrieval of depth maps of objects with optically rough surfaces at submillimeter depth precision. In contrast to conventional ToF cameras, our device uses only off-the-shelf CCD/CMOS detectors and works at their native chip resolution (as of today, theoretically up to 20 Mp and beyond). Moreover, we can obtain a full 3D model of the object in single-shot, meaning that no temporal sequence of exposures or temporal illumination modulation (such as amplitude or frequency modulation) is necessary, which makes our camera robust against object motion. In this paper, we introduce the novel camera concept and show first measurements that demonstrate the capabilities of our system. We present 3D measurements of small (cm-sized) objects with > 2 Mp point cloud resolution (the resolution of our used detector) and up to sub-mm depth precision. We also report a "single-shot 3D video" acquisition and a first single-shot "Non-Line-of-Sight" measurement. Our technique has great potential for high-precision applications with dynamic object movement, e.g., in AR/VR, industrial inspection, medical imaging, and imaging through scattering media like fog or human tissue.
Event-Driven Tactile Learning with Various Location Spiking Neurons
Oct 11, 2022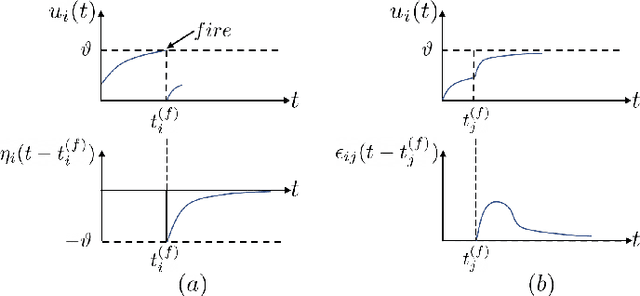
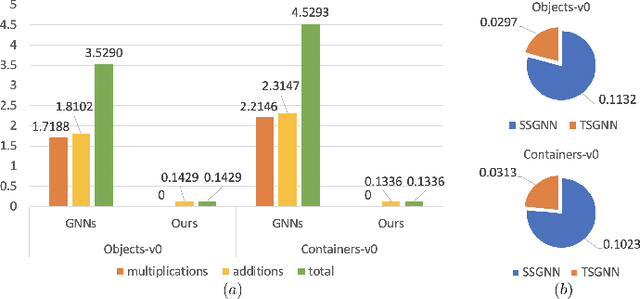
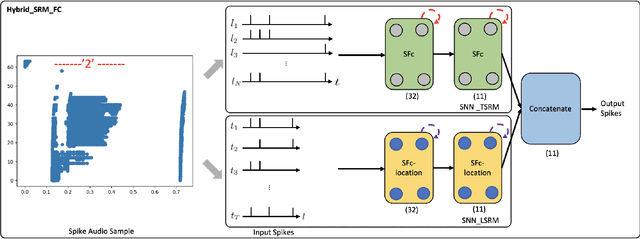
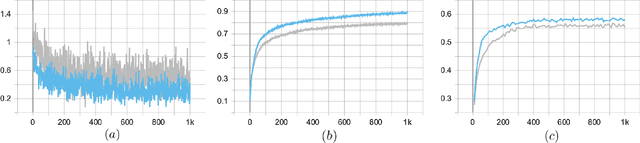
Tactile sensing is essential for a variety of daily tasks. New advances in event-driven tactile sensors and Spiking Neural Networks (SNNs) spur the research in related fields. However, SNN-enabled event-driven tactile learning is still in its infancy due to the limited representation abilities of existing spiking neurons and high spatio-temporal complexity in the data. In this paper, to improve the representation capability of existing spiking neurons, we propose a novel neuron model called "location spiking neuron", which enables us to extract features of event-based data in a novel way. Specifically, based on the classical Time Spike Response Model (TSRM), we develop the Location Spike Response Model (LSRM). In addition, based on the most commonly-used Time Leaky Integrate-and-Fire (TLIF) model, we develop the Location Leaky Integrate-and-Fire (LLIF) model. By exploiting the novel location spiking neurons, we propose several models to capture the complex spatio-temporal dependencies in the event-driven tactile data. Extensive experiments demonstrate the significant improvements of our models over other works on event-driven tactile learning and show the superior energy efficiency of our models and location spiking neurons, which may unlock their potential on neuromorphic hardware.
Denoising Fast X-Ray Fluorescence Raster Scans of Paintings
Jun 03, 2022

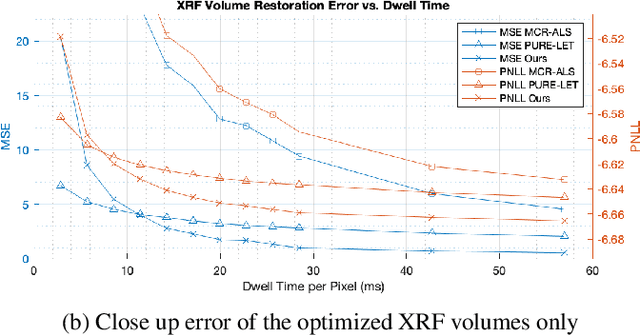
Macro x-ray fluorescence (XRF) imaging of cultural heritage objects, while a popular non-invasive technique for providing elemental distribution maps, is a slow acquisition process in acquiring high signal-to-noise ratio XRF volumes. Typically on the order of tenths of a second per pixel, a raster scanning probe counts the number of photons at different energies emitted by the object under x-ray illumination. In an effort to reduce the scan times without sacrificing elemental map and XRF volume quality, we propose using dictionary learning with a Poisson noise model as well as a color image-based prior to restore noisy, rapidly acquired XRF data.
Investigating the Potential of Auxiliary-Classifier GANs for Image Classification in Low Data Regimes
Jan 22, 2022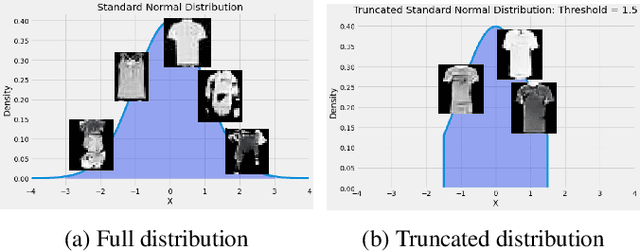
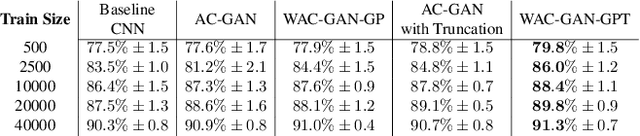
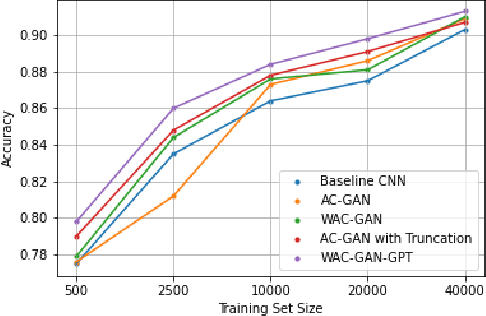
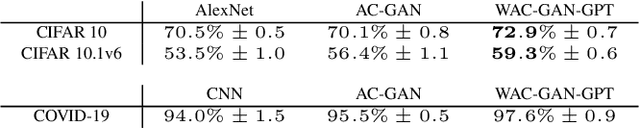
Generative Adversarial Networks (GANs) have shown promise in augmenting datasets and boosting convolutional neural networks' (CNN) performance on image classification tasks. But they introduce more hyperparameters to tune as well as the need for additional time and computational power to train supplementary to the CNN. In this work, we examine the potential for Auxiliary-Classifier GANs (AC-GANs) as a 'one-stop-shop' architecture for image classification, particularly in low data regimes. Additionally, we explore modifications to the typical AC-GAN framework, changing the generator's latent space sampling scheme and employing a Wasserstein loss with gradient penalty to stabilize the simultaneous training of image synthesis and classification. Through experiments on images of varying resolutions and complexity, we demonstrate that AC-GANs show promise in image classification, achieving competitive performance with standard CNNs. These methods can be employed as an 'all-in-one' framework with particular utility in the absence of large amounts of training data.
LiveView: Dynamic Target-Centered MPI for View Synthesis
Jul 11, 2021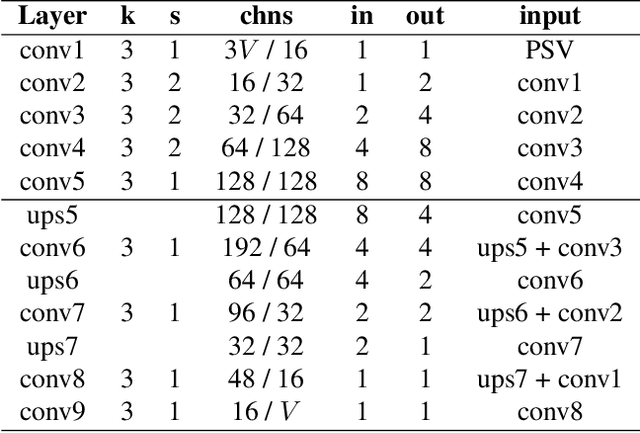
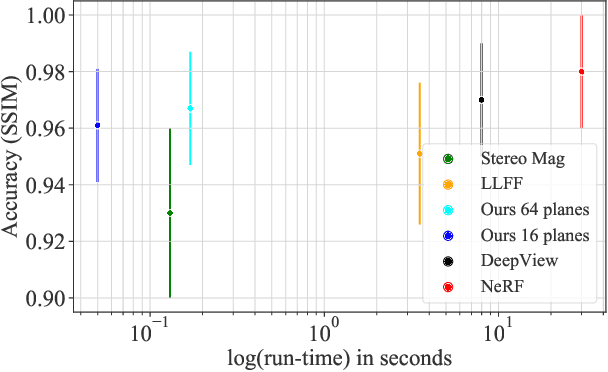
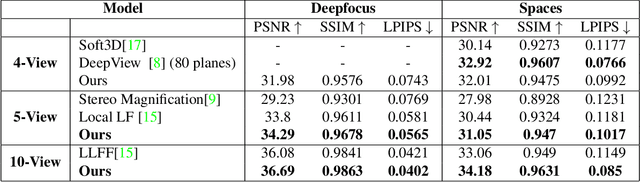
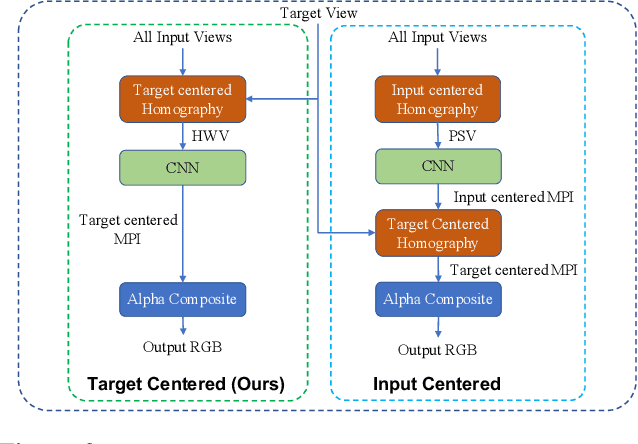
Existing Multi-Plane Image (MPI) based view-synthesis methods generate an MPI aligned with the input view using a fixed number of planes in one forward pass. These methods produce fast, high-quality rendering of novel views, but rely on slow and computationally expensive MPI generation methods unsuitable for real-time applications. In addition, most MPI techniques use fixed depth/disparity planes which cannot be modified once the training is complete, hence offering very little flexibility at run-time. We propose LiveView - a novel MPI generation and rendering technique that produces high-quality view synthesis in real-time. Our method can also offer the flexibility to select scene-dependent MPI planes (number of planes and spacing between them) at run-time. LiveView first warps input images to target view (target-centered) and then learns to generate a target view centered MPI, one depth plane at a time (dynamically). The method generates high-quality renderings, while also enabling fast MPI generation and novel view synthesis. As a result, LiveView enables real-time view synthesis applications where an MPI needs to be updated frequently based on a video stream of input views. We demonstrate that LiveView improves the quality of view synthesis while being 70 times faster at run-time compared to state-of-the-art MPI-based methods.
Plot2Spectra: an Automatic Spectra Extraction Tool
Jul 06, 2021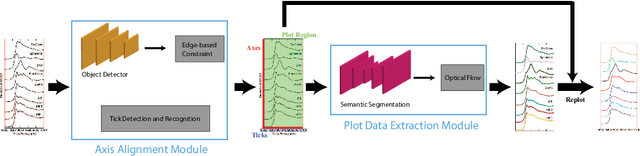
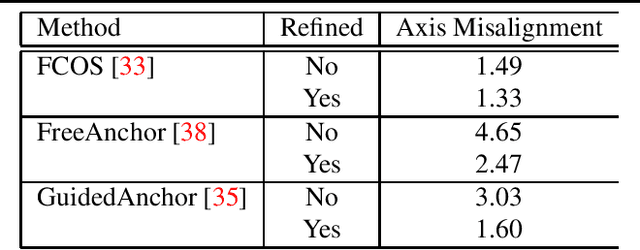
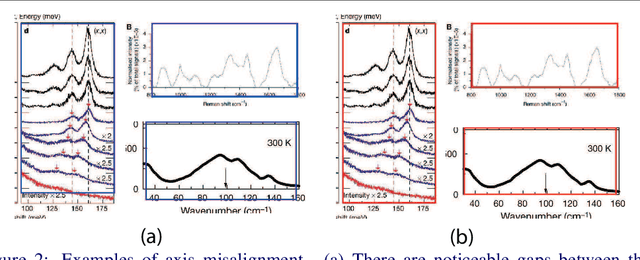
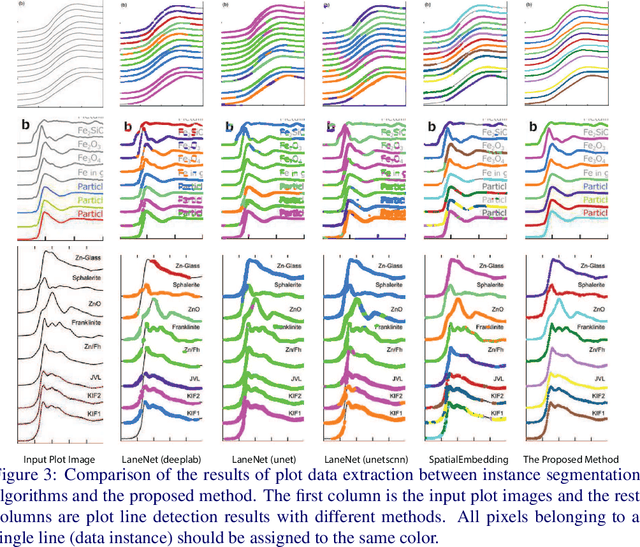
Different types of spectroscopies, such as X-ray absorption near edge structure (XANES) and Raman spectroscopy, play a very important role in analyzing the characteristics of different materials. In scientific literature, XANES/Raman data are usually plotted in line graphs which is a visually appropriate way to represent the information when the end-user is a human reader. However, such graphs are not conducive to direct programmatic analysis due to the lack of automatic tools. In this paper, we develop a plot digitizer, named Plot2Spectra, to extract data points from spectroscopy graph images in an automatic fashion, which makes it possible for large scale data acquisition and analysis. Specifically, the plot digitizer is a two-stage framework. In the first axis alignment stage, we adopt an anchor-free detector to detect the plot region and then refine the detected bounding boxes with an edge-based constraint to locate the position of two axes. We also apply scene text detector to extract and interpret all tick information below the x-axis. In the second plot data extraction stage, we first employ semantic segmentation to separate pixels belonging to plot lines from the background, and from there, incorporate optical flow constraints to the plot line pixels to assign them to the appropriate line (data instance) they encode. Extensive experiments are conducted to validate the effectiveness of the proposed plot digitizer, which shows that such a tool could help accelerate the discovery and machine learning of materials properties.
A Joint Intensity-Neuromorphic Event Imaging System for Resource Constrained Devices
May 29, 2021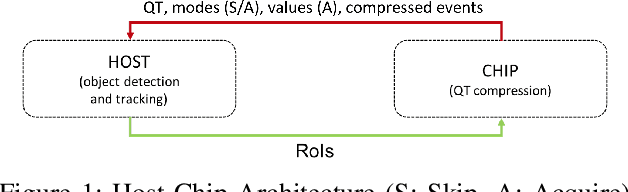
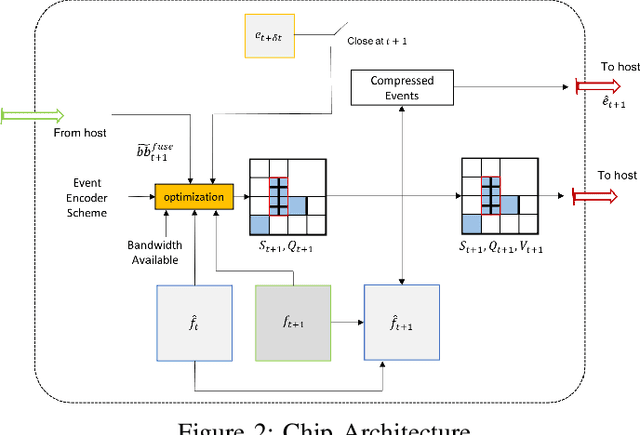
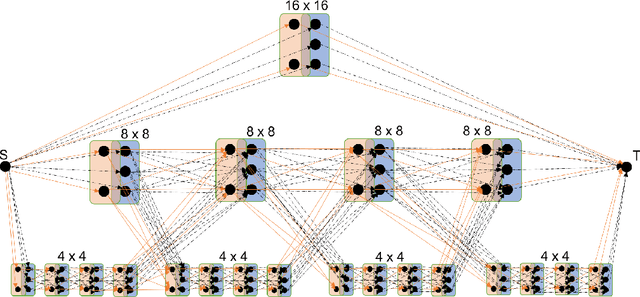
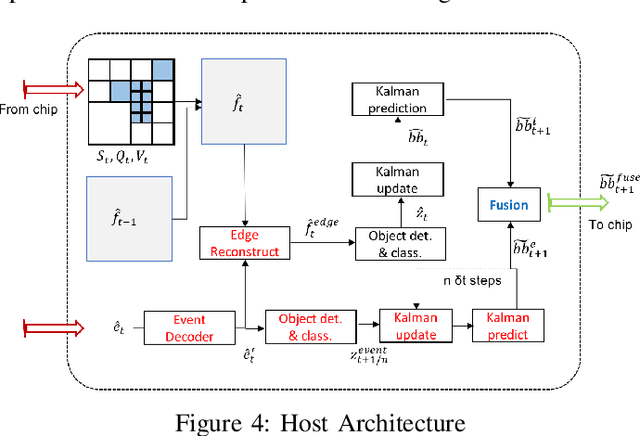
We present a novel adaptive multi-modal intensity-event algorithm to optimize an overall objective of object tracking under bit rate constraints for a host-chip architecture. The chip is a computationally resource constrained device acquiring high resolution intensity frames and events, while the host is capable of performing computationally expensive tasks. We develop a joint intensity-neuromorphic event rate-distortion compression framework with a quadtree (QT) based compression of intensity and events scheme. The data acquisition on the chip is driven by the presence of objects of interest in the scene as detected by an object detector. The most informative intensity and event data are communicated to the host under rate constraints, so that the best possible tracking performance is obtained. The detection and tracking of objects in the scene are done on the distorted data at the host. Intensity and events are jointly used in a fusion framework to enhance the quality of the distorted images, so as to improve the object detection and tracking performance. The performance assessment of the overall system is done in terms of the multiple object tracking accuracy (MOTA) score. Compared to using intensity modality only, there is an improvement in MOTA using both these modalities in different scenarios.
Improving Acquisition Speed of X-Ray Ptychography through Spatial Undersampling and Regularization
May 20, 2021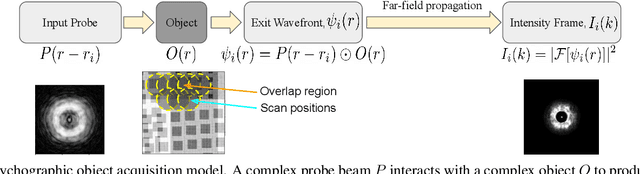
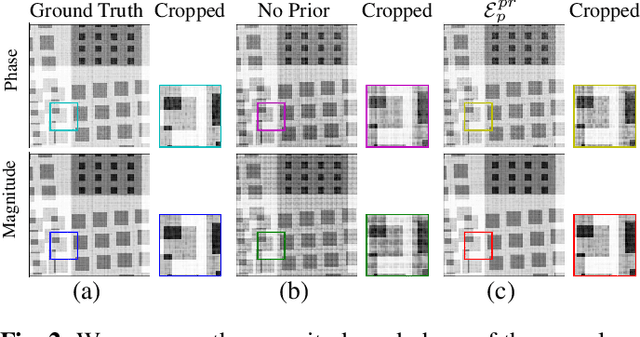

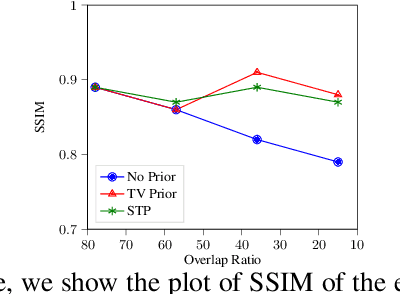
X-ray ptychography is one of the versatile techniques for nanometer resolution imaging. The magnitude of the diffraction patterns is recorded on a detector and the phase of the diffraction patterns is estimated using phase retrieval techniques. Most phase retrieval algorithms make the solution well-posed by relying on the constraints imposed by the overlapping region between neighboring diffraction pattern samples. As the overlap between neighboring diffraction patterns reduces, the problem becomes ill-posed and the object cannot be recovered. To avoid the ill-posedness, we investigate the effect of regularizing the phase retrieval algorithm with image priors for various overlap ratios between the neighboring diffraction patterns. We show that the object can be faithfully reconstructed at low overlap ratios by regularizing the phase retrieval algorithm with image priors such as Total-Variation and Structure Tensor Prior. We also show the effectiveness of our proposed algorithm on real data acquired from an IC chip with a coherent X-ray beam.
Removing Blocking Artifacts in Video Streams Using Event Cameras
May 12, 2021
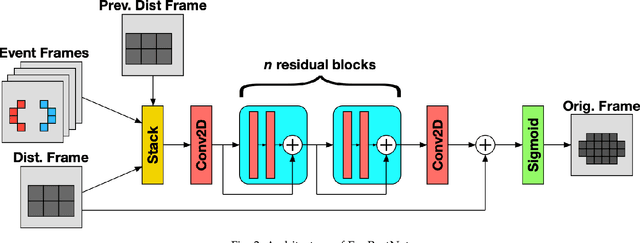
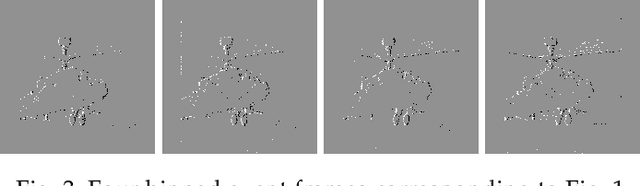

In this paper, we propose EveRestNet, a convolutional neural network designed to remove blocking artifacts in videostreams using events from neuromorphic sensors. We first degrade the video frame using a quadtree structure to produce the blocking artifacts to simulate transmitting a video under a heavily constrained bandwidth. Events from the neuromorphic sensor are also simulated, but are transmitted in full. Using the distorted frames and the event stream, EveRestNet is able to improve the image quality.
Adaptive Illumination based Depth Sensing using Deep Learning
Mar 23, 2021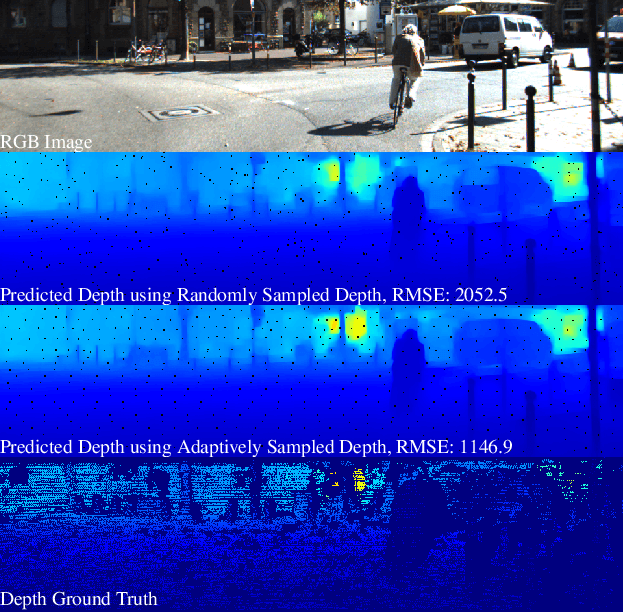
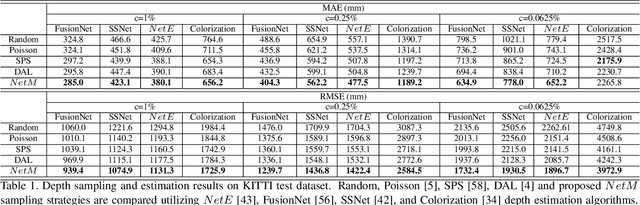
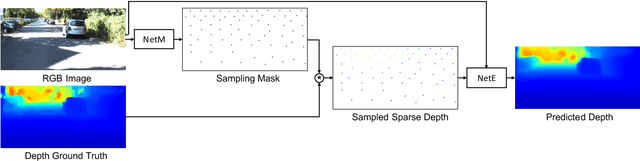
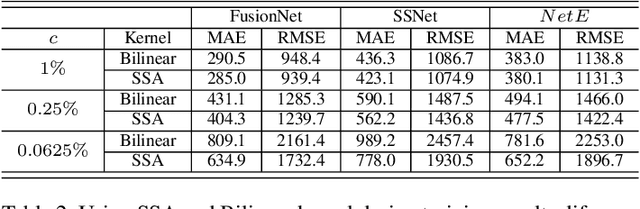
Dense depth map capture is challenging in existing active sparse illumination based depth acquisition techniques, such as LiDAR. Various techniques have been proposed to estimate a dense depth map based on fusion of the sparse depth map measurement with the RGB image. Recent advances in hardware enable adaptive depth measurements resulting in further improvement of the dense depth map estimation. In this paper, we study the topic of estimating dense depth from depth sampling. The adaptive sparse depth sampling network is jointly trained with a fusion network of an RGB image and sparse depth, to generate optimal adaptive sampling masks. We show that such adaptive sampling masks can generalize well to many RGB and sparse depth fusion algorithms under a variety of sampling rates (as low as $0.0625\%$). The proposed adaptive sampling method is fully differentiable and flexible to be trained end-to-end with upstream perception algorithms.