 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSignal Recovery from Time and Frequency Samples
Mar 17, 2026We analyze signal recovery when samples are taken concomitantly from a signal and its Fourier transform. This two-sided sampling framework extends classical one-sided reconstruction and is particularly useful when measurements in either domain alone are insufficient because of sensing, storage, or bandwidth constraints. We formulate the resulting recovery problem in finite-dimensional spaces and reproducing kernel Hilbert spaces, and illustrate the infinite-dimensional setting in a Fourier-symmetric Sobolev space. Numerical experiments with sinc- and Hermite-based schemes indicate that, under a fixed sampling budget, two-sided sampling often yields better conditioned systems than one-sided approaches. A simplified spectrum-monitoring example further demonstrates improved reconstruction when limited time samples are supplemented with frequency-domain information.
Automatic Prompt Optimization for Dataset-Level Feature Discovery
Jan 20, 2026Feature extraction from unstructured text is a critical step in many downstream classification pipelines, yet current approaches largely rely on hand-crafted prompts or fixed feature schemas. We formulate feature discovery as a dataset-level prompt optimization problem: given a labelled text corpus, the goal is to induce a global set of interpretable and discriminative feature definitions whose realizations optimize a downstream supervised learning objective. To this end, we propose a multi-agent prompt optimization framework in which language-model agents jointly propose feature definitions, extract feature values, and evaluate feature quality using dataset-level performance and interpretability feedback. Instruction prompts are iteratively refined based on this structured feedback, enabling optimization over prompts that induce shared feature sets rather than per-example predictions. This formulation departs from prior prompt optimization methods that rely on per-sample supervision and provides a principled mechanism for automatic feature discovery from unstructured text.
Deep Hedging Under Non-Convexity: Limitations and a Case for AlphaZero
Oct 02, 2025



This paper examines replication portfolio construction in incomplete markets - a key problem in financial engineering with applications in pricing, hedging, balance sheet management, and energy storage planning. We model this as a two-player game between an investor and the market, where the investor makes strategic bets on future states while the market reveals outcomes. Inspired by the success of Monte Carlo Tree Search in stochastic games, we introduce an AlphaZero-based system and compare its performance to deep hedging - a widely used industry method based on gradient descent. Through theoretical analysis and experiments, we show that deep hedging struggles in environments where the $Q$-function is not subject to convexity constraints - such as those involving non-convex transaction costs, capital constraints, or regulatory limitations - converging to local optima. We construct specific market environments to highlight these limitations and demonstrate that AlphaZero consistently finds near-optimal replication strategies. On the theoretical side, we establish a connection between deep hedging and convex optimization, suggesting that its effectiveness is contingent on convexity assumptions. Our experiments further suggest that AlphaZero is more sample-efficient - an important advantage in data-scarce, overfitting-prone derivative markets.
Enhancing Aerial Combat Tactics through Hierarchical Multi-Agent Reinforcement Learning
May 13, 2025



This work presents a Hierarchical Multi-Agent Reinforcement Learning framework for analyzing simulated air combat scenarios involving heterogeneous agents. The objective is to identify effective Courses of Action that lead to mission success within preset simulations, thereby enabling the exploration of real-world defense scenarios at low cost and in a safe-to-fail setting. Applying deep Reinforcement Learning in this context poses specific challenges, such as complex flight dynamics, the exponential size of the state and action spaces in multi-agent systems, and the capability to integrate real-time control of individual units with look-ahead planning. To address these challenges, the decision-making process is split into two levels of abstraction: low-level policies control individual units, while a high-level commander policy issues macro commands aligned with the overall mission targets. This hierarchical structure facilitates the training process by exploiting policy symmetries of individual agents and by separating control from command tasks. The low-level policies are trained for individual combat control in a curriculum of increasing complexity. The high-level commander is then trained on mission targets given pre-trained control policies. The empirical validation confirms the advantages of the proposed framework.
On the Convergence and Stability of Upside-Down Reinforcement Learning, Goal-Conditioned Supervised Learning, and Online Decision Transformers
Feb 08, 2025This article provides a rigorous analysis of convergence and stability of Episodic Upside-Down Reinforcement Learning, Goal-Conditioned Supervised Learning and Online Decision Transformers. These algorithms performed competitively across various benchmarks, from games to robotic tasks, but their theoretical understanding is limited to specific environmental conditions. This work initiates a theoretical foundation for algorithms that build on the broad paradigm of approaching reinforcement learning through supervised learning or sequence modeling. At the core of this investigation lies the analysis of conditions on the underlying environment, under which the algorithms can identify optimal solutions. We also assess whether emerging solutions remain stable in situations where the environment is subject to tiny levels of noise. Specifically, we study the continuity and asymptotic convergence of command-conditioned policies, values and the goal-reaching objective depending on the transition kernel of the underlying Markov Decision Process. We demonstrate that near-optimal behavior is achieved if the transition kernel is located in a sufficiently small neighborhood of a deterministic kernel. The mentioned quantities are continuous (with respect to a specific topology) at deterministic kernels, both asymptotically and after a finite number of learning cycles. The developed methods allow us to present the first explicit estimates on the convergence and stability of policies and values in terms of the underlying transition kernels. On the theoretical side we introduce a number of new concepts to reinforcement learning, like working in segment spaces, studying continuity in quotient topologies and the application of the fixed-point theory of dynamical systems. The theoretical study is accompanied by a detailed investigation of example environments and numerical experiments.
Hierarchical Multi-Agent Reinforcement Learning for Air Combat Maneuvering
Sep 20, 2023The application of artificial intelligence to simulate air-to-air combat scenarios is attracting increasing attention. To date the high-dimensional state and action spaces, the high complexity of situation information (such as imperfect and filtered information, stochasticity, incomplete knowledge about mission targets) and the nonlinear flight dynamics pose significant challenges for accurate air combat decision-making. These challenges are exacerbated when multiple heterogeneous agents are involved. We propose a hierarchical multi-agent reinforcement learning framework for air-to-air combat with multiple heterogeneous agents. In our framework, the decision-making process is divided into two stages of abstraction, where heterogeneous low-level policies control the action of individual units, and a high-level commander policy issues macro commands given the overall mission targets. Low-level policies are trained for accurate unit combat control. Their training is organized in a learning curriculum with increasingly complex training scenarios and league-based self-play. The commander policy is trained on mission targets given pre-trained low-level policies. The empirical validation advocates the advantages of our design choices.
Hedging of Financial Derivative Contracts via Monte Carlo Tree Search
Mar 03, 2021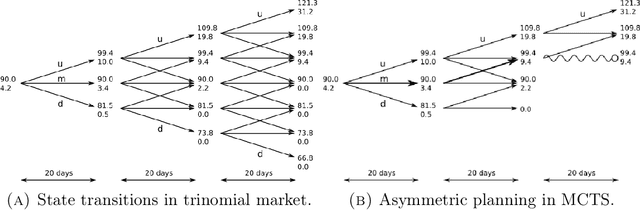
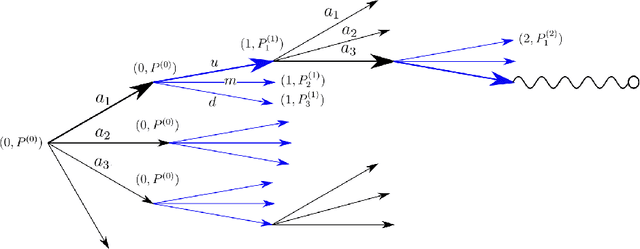
The construction of approximate replication strategies for derivative contracts in incomplete markets is a key problem of financial engineering. Recently Reinforcement Learning algorithms for pricing and hedging under realistic market conditions have attracted significant interest. While financial research mostly focused on variations of $Q$-learning, in Artificial Intelligence Monte Carlo Tree Search is the recognized state-of-the-art method for various planning problems, such as the games of Hex, Chess, Go,... This article introduces Monte Carlo Tree Search as a method to solve the stochastic optimal control problem underlying the pricing and hedging of financial derivatives. As compared to $Q$-learning it combines reinforcement learning with tree search techniques. As a consequence Monte Carlo Tree Search has higher sample efficiency, is less prone to over-fitting to specific market models and generally learns stronger policies faster. In our experiments we find that Monte Carlo Tree Search, being the world-champion in games like Chess and Go, is easily capable of directly maximizing the utility of investor's terminal wealth without an intermediate mathematical theory.
An exact kernel framework for spatio-temporal dynamics
Nov 13, 2020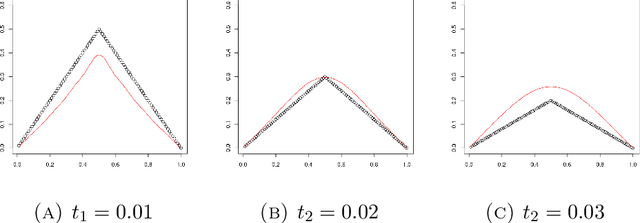
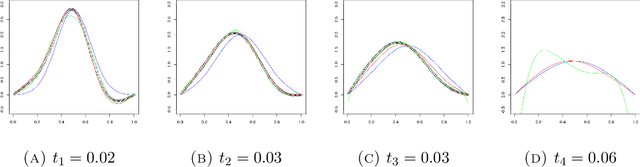
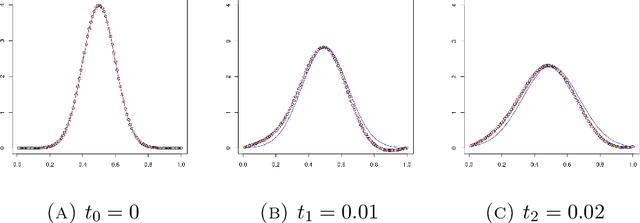
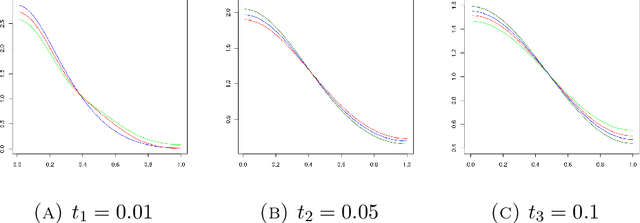
A kernel-based framework for spatio-temporal data analysis is introduced that applies in situations when the underlying system dynamics are governed by a dynamic equation. The key ingredient is a representer theorem that involves time-dependent kernels. Such kernels occur commonly in the expansion of solutions of partial differential equations. The representer theorem is applied to find among all solutions of a dynamic equation the one that minimizes the error with given spatio-temporal samples. This is motivated by the fact that very often a differential equation is given a priori (e.g.~by the laws of physics) and a practitioner seeks the best solution that is compatible with her noisy measurements. Our guiding example is the Fokker-Planck equation, which describes the evolution of density in stochastic diffusion processes. A regression and density estimation framework is introduced for spatio-temporal modeling under Fokker-Planck dynamics with initial and boundary conditions.
Hedging using reinforcement learning: Contextual $k$-Armed Bandit versus $Q$-learning
Jul 03, 2020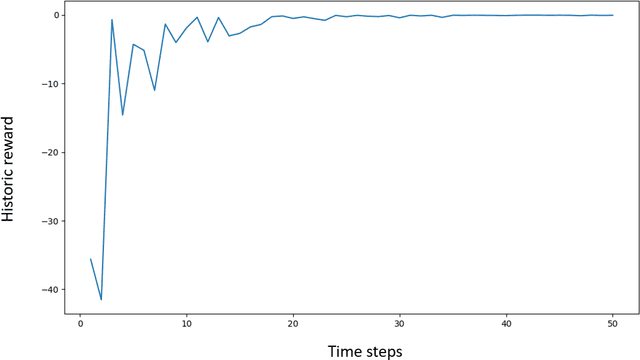
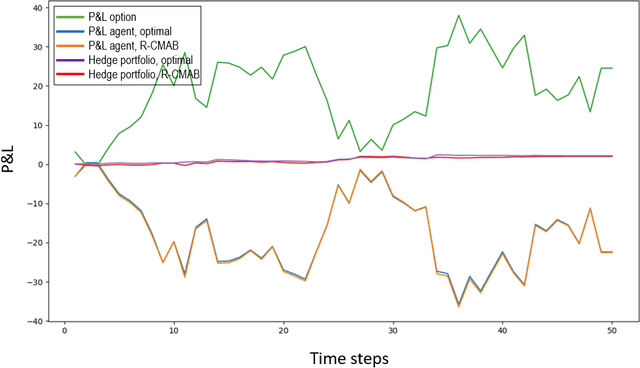
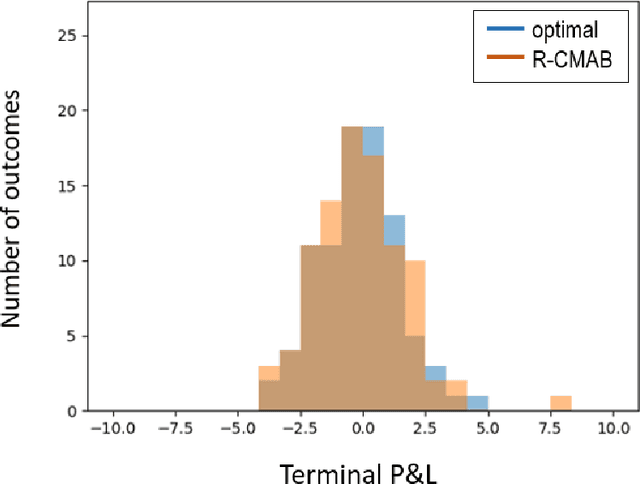
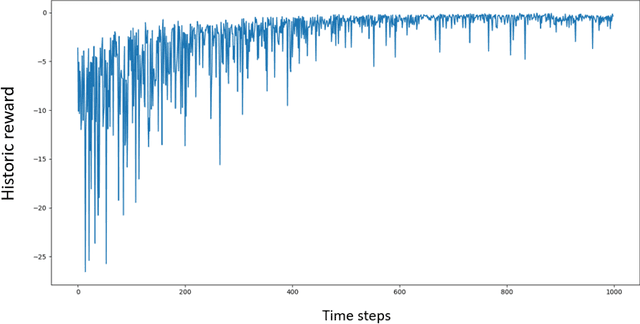
The construction of replication strategies for contingent claims in the presence of risk and market friction is a key problem of financial engineering. In real markets, continuous replication, such as in the model of Black, Scholes and Merton, is not only unrealistic but it is also undesirable due to high transaction costs. Over the last decades stochastic optimal-control methods have been developed to balance between effective replication and losses. More recently, with the rise of artificial intelligence, temporal-difference Reinforcement Learning, in particular variations of $Q$-learning in conjunction with Deep Neural Networks, have attracted significant interest. From a practical point of view, however, such methods are often relatively sample inefficient, hard to train and lack performance guarantees. This motivates the investigation of a stable benchmark algorithm for hedging. In this article, the hedging problem is viewed as an instance of a risk-averse contextual $k$-armed bandit problem, for which a large body of theoretical results and well-studied algorithms are available. We find that the $k$-armed bandit model naturally fits to the $P\&L$ formulation of hedging, providing for a more accurate and sample efficient approach than $Q$-learning and reducing to the Black-Scholes model in the absence of transaction costs and risks.