 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuildMamba: A Visual State-Space Based Model for Multi-Task Building Segmentation and Height Estimation from Satellite Images
Mar 09, 2026Accurate building segmentation and height estimation from single-view RGB satellite imagery are fundamental for urban analytics, yet remain ill-posed due to structural variability and the high computational cost of global context modeling. While current approaches typically adapt monocular depth architectures, they often suffer from boundary bleeding and systematic underestimation of high-rise structures. To address these limitations, we propose BuildMamba, a unified multi-task framework designed to exploit the linear-time global modeling of visual state-space models. Motivated by the need for stronger structural coupling and computational efficiency, we introduce three modules: a Mamba Attention Module for dynamic spatial recalibration, a Spatial-Aware Mamba-FPN for multi-scale feature aggregation via gated state-space scans, and a Mask-Aware Height Refinement module using semantic priors to suppress height artifacts. Extensive experiments demonstrate that BuildMamba establishes a new performance upper bound across three benchmarks. Specifically, it achieves an IoU of 0.93 and RMSE of 1.77~m on DFC23 benchmark, surpassing state-of-the-art by 0.82~m in height estimation. Simulation results confirm the model's superior robustness and scalability for large-scale 3D urban reconstruction.
Imperceptible Adversarial Examples by Spatial Chroma-Shift
Sep 02, 2021
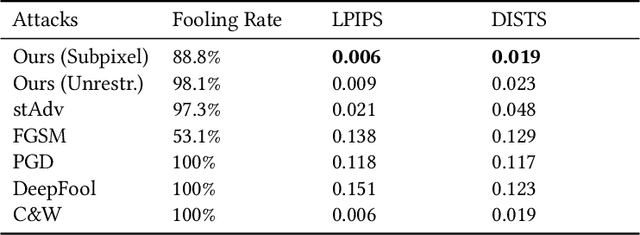

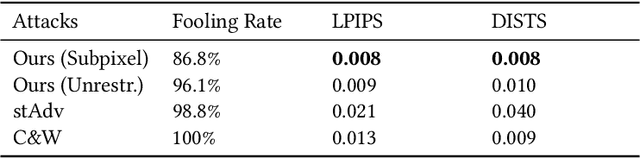
Deep Neural Networks have been shown to be vulnerable to various kinds of adversarial perturbations. In addition to widely studied additive noise based perturbations, adversarial examples can also be created by applying a per pixel spatial drift on input images. While spatial transformation based adversarial examples look more natural to human observers due to absence of additive noise, they still possess visible distortions caused by spatial transformations. Since the human vision is more sensitive to the distortions in the luminance compared to those in chrominance channels, which is one of the main ideas behind the lossy visual multimedia compression standards, we propose a spatial transformation based perturbation method to create adversarial examples by only modifying the color components of an input image. While having competitive fooling rates on CIFAR-10 and NIPS2017 Adversarial Learning Challenge datasets, examples created with the proposed method have better scores with regards to various perceptual quality metrics. Human visual perception studies validate that the examples are more natural looking and often indistinguishable from their original counterparts.