 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Memory SE(2) Invariant Attention
Jul 24, 2025Processing spatial data is a key component in many learning tasks for autonomous driving such as motion forecasting, multi-agent simulation, and planning. Prior works have demonstrated the value in using SE(2) invariant network architectures that consider only the relative poses between objects (e.g. other agents, scene features such as traffic lanes). However, these methods compute the relative poses for all pairs of objects explicitly, requiring quadratic memory. In this work, we propose a mechanism for SE(2) invariant scaled dot-product attention that requires linear memory relative to the number of objects in the scene. Our SE(2) invariant transformer architecture enjoys the same scaling properties that have benefited large language models in recent years. We demonstrate experimentally that our approach is practical to implement and improves performance compared to comparable non-invariant architectures.
Scenario Diffusion: Controllable Driving Scenario Generation With Diffusion
Nov 16, 2023



Automated creation of synthetic traffic scenarios is a key part of validating the safety of autonomous vehicles (AVs). In this paper, we propose Scenario Diffusion, a novel diffusion-based architecture for generating traffic scenarios that enables controllable scenario generation. We combine latent diffusion, object detection and trajectory regression to generate distributions of synthetic agent poses, orientations and trajectories simultaneously. To provide additional control over the generated scenario, this distribution is conditioned on a map and sets of tokens describing the desired scenario. We show that our approach has sufficient expressive capacity to model diverse traffic patterns and generalizes to different geographical regions.
FISHING Net: Future Inference of Semantic Heatmaps In Grids
Jun 17, 2020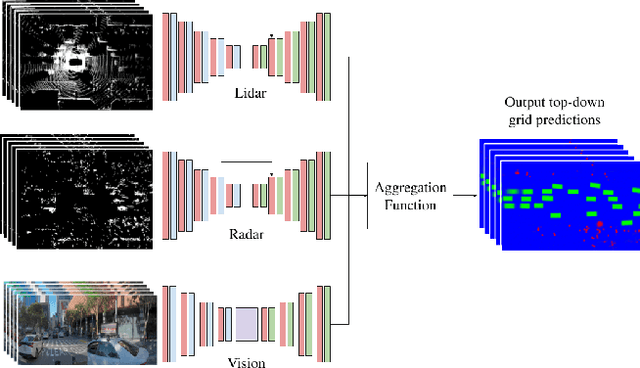
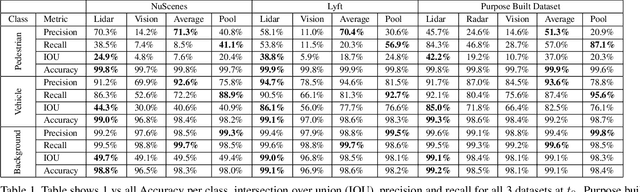

For autonomous robots to navigate a complex environment, it is crucial to understand the surrounding scene both geometrically and semantically. Modern autonomous robots employ multiple sets of sensors, including lidars, radars, and cameras. Managing the different reference frames and characteristics of the sensors, and merging their observations into a single representation complicates perception. Choosing a single unified representation for all sensors simplifies the task of perception and fusion. In this work, we present an end-to-end pipeline that performs semantic segmentation and short term prediction using a top-down representation. Our approach consists of an ensemble of neural networks which take in sensor data from different sensor modalities and transform them into a single common top-down semantic grid representation. We find this representation favorable as it is agnostic to sensor-specific reference frames and captures both the semantic and geometric information for the surrounding scene. Because the modalities share a single output representation, they can be easily aggregated to produce a fused output. In this work we predict short-term semantic grids but the framework can be extended to other tasks. This approach offers a simple, extensible, end-to-end approach for multi-modal perception and prediction.