 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Textual Context: Structural Graph Encoding with Adaptive Space Alignment to alleviate the hallucination of LLMs
Sep 26, 2025



Currently, the main approach for Large Language Models (LLMs) to tackle the hallucination issue is incorporating Knowledge Graphs(KGs).However, LLMs typically treat KGs as plain text, extracting only semantic information and limiting their use of the crucial structural aspects of KGs. Another challenge is the gap between the embedding spaces of KGs encoders and LLMs text embeddings, which hinders the effective integration of structured knowledge. To overcome these obstacles, we put forward the SSKG-LLM, an innovative model architecture that is designed to efficiently integrate both the Structural and Semantic information of KGs into the reasoning processes of LLMs. SSKG-LLM incorporates the Knowledge Graph Retrieval (KGR) module and the Knowledge Graph Encoding (KGE) module to preserve semantics while utilizing structure. Then, the Knowledge Graph Adaptation (KGA) module is incorporated to enable LLMs to understand KGs embeddings. We conduct extensive experiments and provide a detailed analysis to explore how incorporating the structural information of KGs can enhance the factual reasoning abilities of LLMs. Our code are available at https://github.com/yfangZhang/SSKG-LLM.
FISHING Net: Future Inference of Semantic Heatmaps In Grids
Jun 17, 2020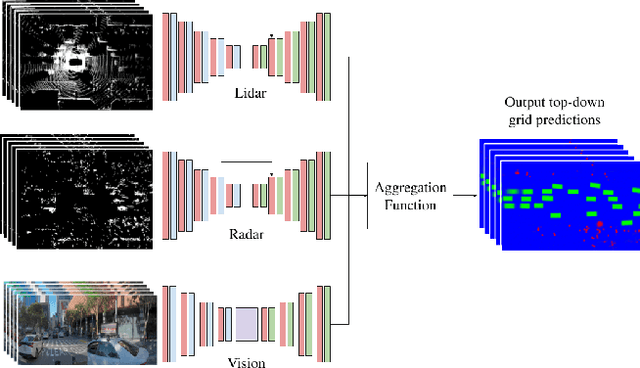
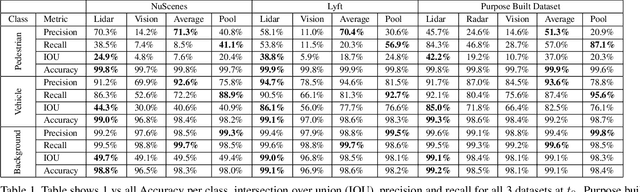

For autonomous robots to navigate a complex environment, it is crucial to understand the surrounding scene both geometrically and semantically. Modern autonomous robots employ multiple sets of sensors, including lidars, radars, and cameras. Managing the different reference frames and characteristics of the sensors, and merging their observations into a single representation complicates perception. Choosing a single unified representation for all sensors simplifies the task of perception and fusion. In this work, we present an end-to-end pipeline that performs semantic segmentation and short term prediction using a top-down representation. Our approach consists of an ensemble of neural networks which take in sensor data from different sensor modalities and transform them into a single common top-down semantic grid representation. We find this representation favorable as it is agnostic to sensor-specific reference frames and captures both the semantic and geometric information for the surrounding scene. Because the modalities share a single output representation, they can be easily aggregated to produce a fused output. In this work we predict short-term semantic grids but the framework can be extended to other tasks. This approach offers a simple, extensible, end-to-end approach for multi-modal perception and prediction.