 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Split Mamba: Effective State Space Modelling for Image Restoration
Mar 10, 2026Image restoration requires simultaneously preserving fine-grained local structures and maintaining long-range spatial coherence. While convolutional networks struggle with limited receptive fields, and Transformers incur quadratic complexity for global attention, recent State Space Models (SSMs), such as Mamba, provide an appealing linear-time alternative for long-range dependency modelling. However, naively extending Mamba to 2D images exposes two intrinsic shortcomings. First, flattening 2D feature maps into 1D sequences disrupts spatial topology, leading to locality distortion that hampers precise structural recovery. Second, the stability-driven recurrent dynamics of SSMs induce long-range decay, progressively attenuating information across distant spatial positions and weakening global consistency. Together, these effects limit the effectiveness of state-space modelling in high-fidelity restoration. We propose Progressive Split-Mamba (PS-Mamba), a topology-aware hierarchical state-space framework designed to reconcile locality preservation with efficient global propagation. Instead of sequentially flattening entire feature maps, PS-Mamba performs geometry-consistent partitioning, maintaining neighbourhood integrity prior to state-space processing. A progressive split hierarchy (halves, quadrants, octants) enables structured multi-scale modelling while retaining linear complexity. To counteract long-range decay, we introduce symmetric cross-scale shortcut pathways that directly transmit low-frequency global context across hierarchical levels, stabilising information flow over large spatial extents. Extensive experiments on super-resolution, denoising, and JPEG artifact reduction show consistent improvements over recent Mamba-based and attention-based models with a clear margin.
Collaborative Zone-Adaptive Zero-Day Intrusion Detection for IoBT
Feb 18, 2026The Internet of Battlefield Things (IoBT) relies on heterogeneous, bandwidth-constrained, and intermittently connected tactical networks that face rapidly evolving cyber threats. In this setting, intrusion detection cannot depend on continuous central collection of raw traffic due to disrupted links, latency, operational security limits, and non-IID traffic across zones. We present Zone-Adaptive Intrusion Detection (ZAID), a collaborative detection and model-improvement framework for unseen attack types, where "zero-day" refers to previously unobserved attack families and behaviours (not vulnerability disclosure timing). ZAID combines a universal convolutional model for generalisable traffic representations, an autoencoder-based reconstruction signal as an auxiliary anomaly score, and lightweight adapter modules for parameter-efficient zone adaptation. To support cross-zone generalisation under constrained connectivity, ZAID uses federated aggregation and pseudo-labelling to leverage locally observed, weakly labelled behaviours. We evaluate ZAID on ToN_IoT using a zero-day protocol that excludes MITM, DDoS, and DoS from supervised training and introduces them during zone-level deployment and adaptation. ZAID achieves up to 83.16% accuracy on unseen attack traffic and transfers to UNSW-NB15 under the same procedure, with a best accuracy of 71.64%. These results indicate that parameter-efficient, zone-personalised collaboration can improve the detection of previously unseen attacks in contested IoBT environments.
Temporal Analysis of NetFlow Datasets for Network Intrusion Detection Systems
Mar 06, 2025This paper investigates the temporal analysis of NetFlow datasets for machine learning (ML)-based network intrusion detection systems (NIDS). Although many previous studies have highlighted the critical role of temporal features, such as inter-packet arrival time and flow length/duration, in NIDS, the currently available NetFlow datasets for NIDS lack these temporal features. This study addresses this gap by creating and making publicly available a set of NetFlow datasets that incorporate these temporal features [1]. With these temporal features, we provide a comprehensive temporal analysis of NetFlow datasets by examining the distribution of various features over time and presenting time-series representations of NetFlow features. This temporal analysis has not been previously provided in the existing literature. We also borrowed an idea from signal processing, time frequency analysis, and tested it to see how different the time frequency signal presentations (TFSPs) are for various attacks. The results indicate that many attacks have unique patterns, which could help ML models to identify them more easily.
A Cyber Threat Intelligence Sharing Scheme based on Federated Learning for Network Intrusion Detection
Nov 04, 2021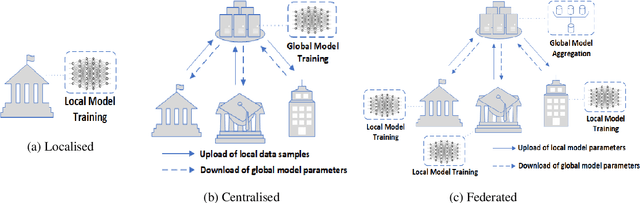

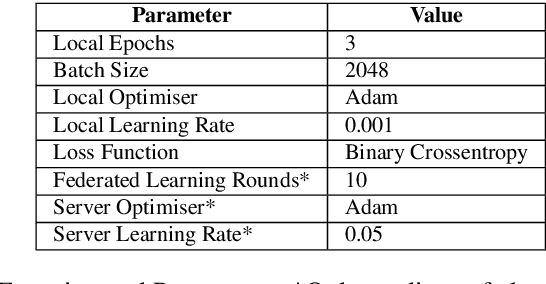
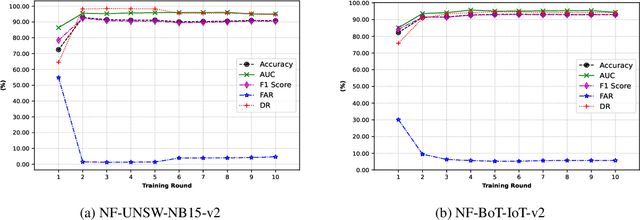
The uses of Machine Learning (ML) in detection of network attacks have been effective when designed and evaluated in a single organisation. However, it has been very challenging to design an ML-based detection system by utilising heterogeneous network data samples originating from several sources. This is mainly due to privacy concerns and the lack of a universal format of datasets. In this paper, we propose a collaborative federated learning scheme to address these issues. The proposed framework allows multiple organisations to join forces in the design, training, and evaluation of a robust ML-based network intrusion detection system. The threat intelligence scheme utilises two critical aspects for its application; the availability of network data traffic in a common format to allow for the extraction of meaningful patterns across data sources. Secondly, the adoption of a federated learning mechanism to avoid the necessity of sharing sensitive users' information between organisations. As a result, each organisation benefits from other organisations cyber threat intelligence while maintaining the privacy of its data internally. The model is trained locally and only the updated weights are shared with the remaining participants in the federated averaging process. The framework has been designed and evaluated in this paper by using two key datasets in a NetFlow format known as NF-UNSW-NB15-v2 and NF-BoT-IoT-v2. Two other common scenarios are considered in the evaluation process; a centralised training method where the local data samples are shared with other organisations and a localised training method where no threat intelligence is shared. The results demonstrate the efficiency and effectiveness of the proposed framework by designing a universal ML model effectively classifying benign and intrusive traffic originating from multiple organisations without the need for local data exchange.
Feature Extraction for Machine Learning-based Intrusion Detection in IoT Networks
Aug 28, 2021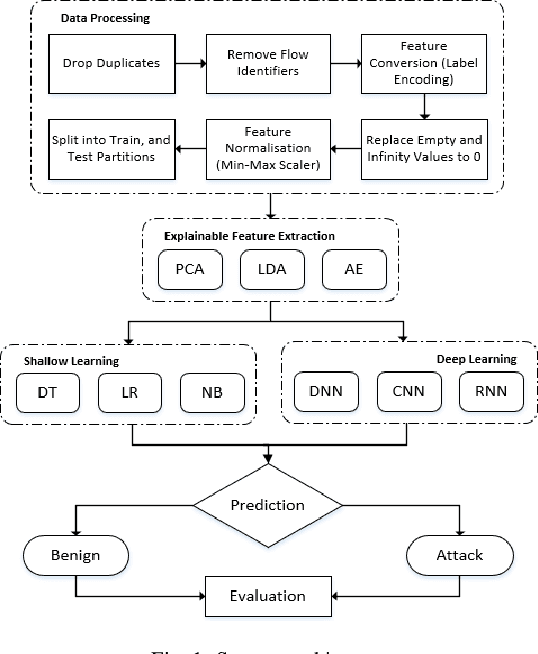
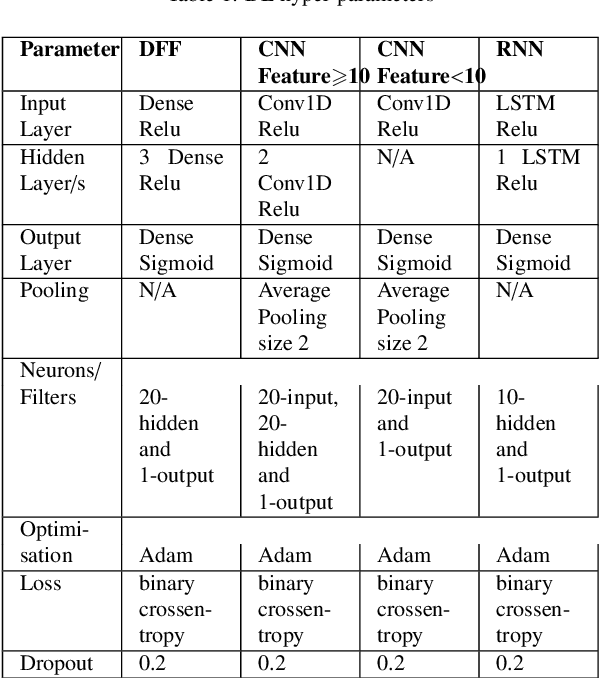
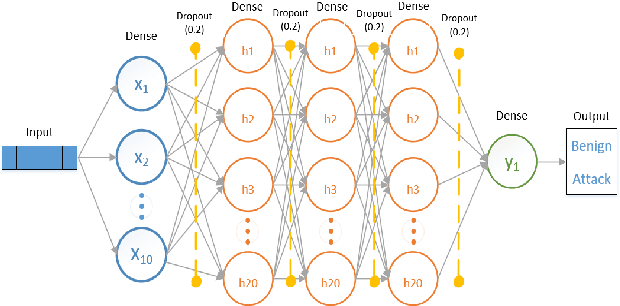
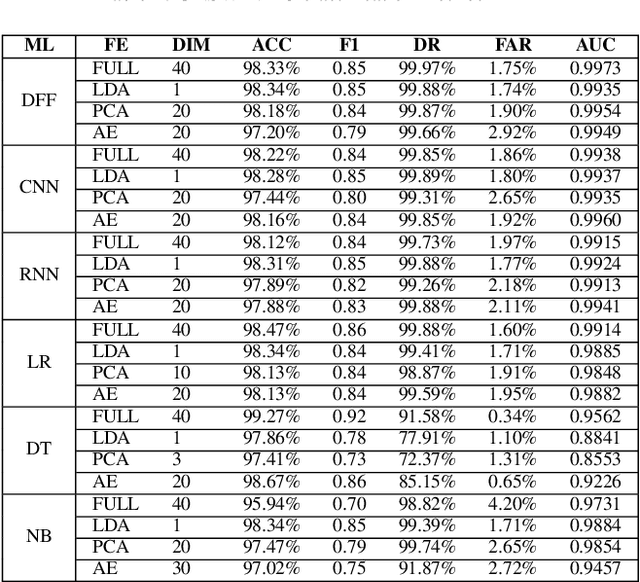
The tremendous numbers of network security breaches that have occurred in IoT networks have demonstrated the unreliability of current Network Intrusion Detection Systems (NIDSs). Consequently, network interruptions and loss of sensitive data have occurred which led to an active research area for improving NIDS technologies. During an analysis of related works, it was observed that most researchers aimed to obtain better classification results by using a set of untried combinations of Feature Reduction (FR) and Machine Learning (ML) techniques on NIDS datasets. However, these datasets are different in feature sets, attack types, and network design. Therefore, this paper aims to discover whether these techniques can be generalised across various datasets. Six ML models are utilised: a Deep Feed Forward, Convolutional Neural Network, Recurrent Neural Network, Decision Tree, Logistic Regression, and Naive Bayes. The detection accuracy of three Feature Extraction (FE) algorithms; Principal Component Analysis (PCA), Auto-encoder (AE), and Linear Discriminant Analysis (LDA) is evaluated using three benchmark datasets; UNSW-NB15, ToN-IoT and CSE-CIC-IDS2018. Although PCA and AE algorithms have been widely used, determining their optimal number of extracted dimensions has been overlooked. The results obtained indicate that there is no clear FE method or ML model that can achieve the best scores for all datasets. The optimal number of extracted dimensions has been identified for each dataset and LDA decreases the performance of the ML models on two datasets. The variance is used to analyse the extracted dimensions of LDA and PCA. Finally, this paper concludes that the choice of datasets significantly alters the performance of the applied techniques and we argue for the need for a universal (benchmark) feature set to facilitate further advancement and progress in this field of research.
Security and Privacy for Artificial Intelligence: Opportunities and Challenges
Feb 09, 2021
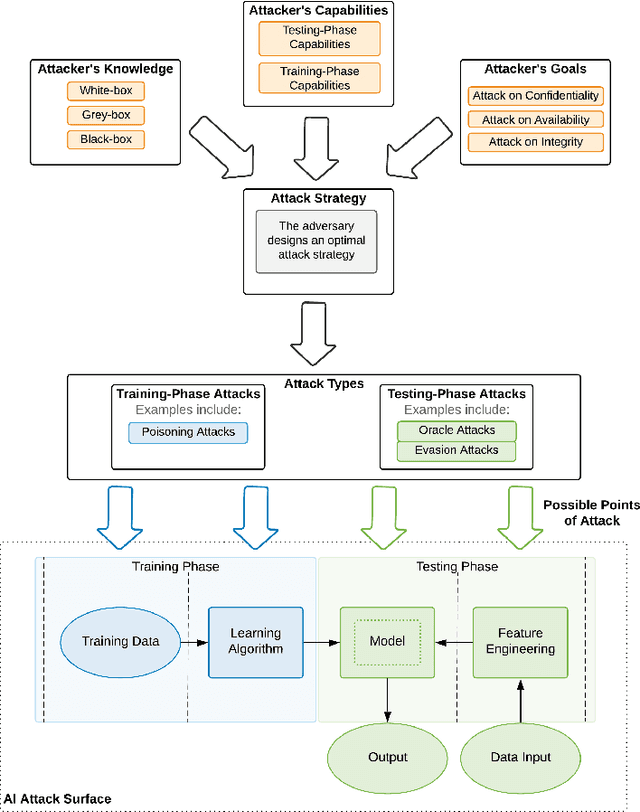
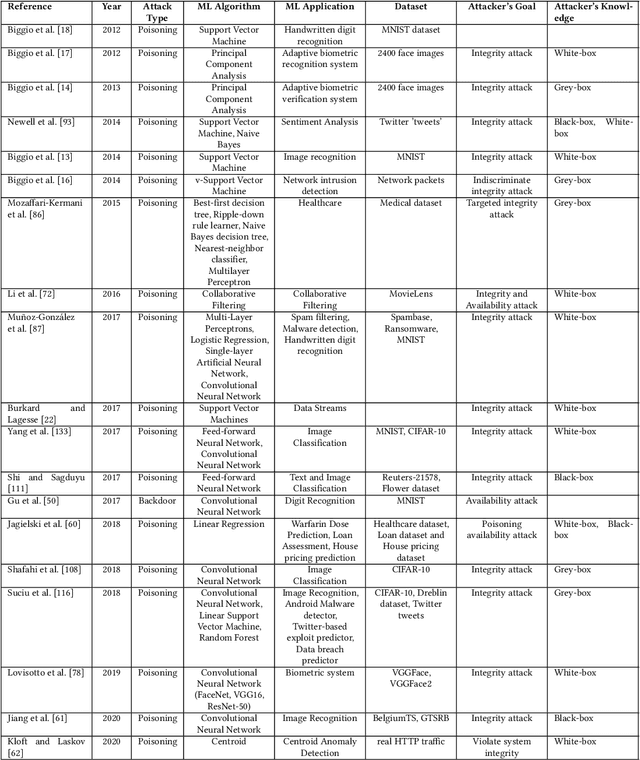
The increased adoption of Artificial Intelligence (AI) presents an opportunity to solve many socio-economic and environmental challenges; however, this cannot happen without securing AI-enabled technologies. In recent years, most AI models are vulnerable to advanced and sophisticated hacking techniques. This challenge has motivated concerted research efforts into adversarial AI, with the aim of developing robust machine and deep learning models that are resilient to different types of adversarial scenarios. In this paper, we present a holistic cyber security review that demonstrates adversarial attacks against AI applications, including aspects such as adversarial knowledge and capabilities, as well as existing methods for generating adversarial examples and existing cyber defence models. We explain mathematical AI models, especially new variants of reinforcement and federated learning, to demonstrate how attack vectors would exploit vulnerabilities of AI models. We also propose a systematic framework for demonstrating attack techniques against AI applications and reviewed several cyber defences that would protect AI applications against those attacks. We also highlight the importance of understanding the adversarial goals and their capabilities, especially the recent attacks against industry applications, to develop adaptive defences that assess to secure AI applications. Finally, we describe the main challenges and future research directions in the domain of security and privacy of AI technologies.
Mitigating the Impact of Adversarial Attacks in Very Deep Networks
Dec 08, 2020
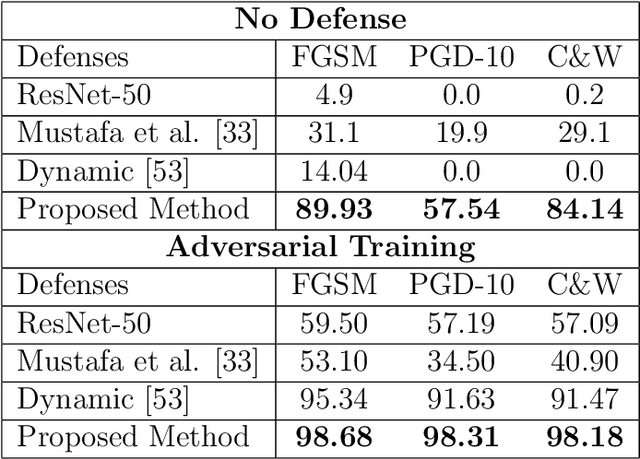
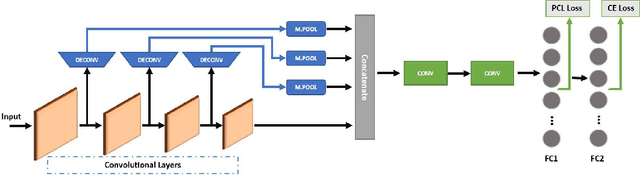
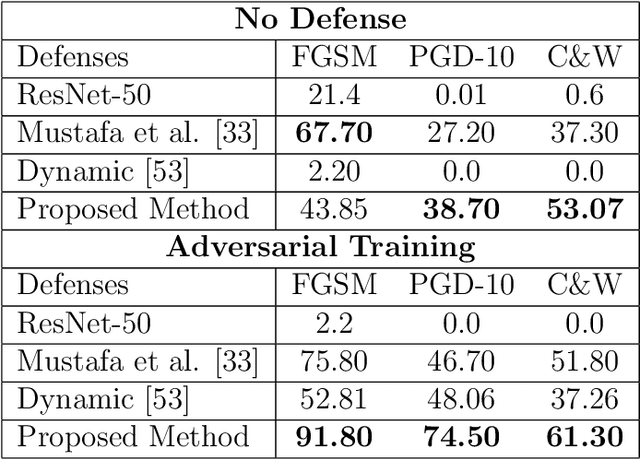
Deep Neural Network (DNN) models have vulnerabilities related to security concerns, with attackers usually employing complex hacking techniques to expose their structures. Data poisoning-enabled perturbation attacks are complex adversarial ones that inject false data into models. They negatively impact the learning process, with no benefit to deeper networks, as they degrade a model's accuracy and convergence rates. In this paper, we propose an attack-agnostic-based defense method for mitigating their influence. In it, a Defensive Feature Layer (DFL) is integrated with a well-known DNN architecture which assists in neutralizing the effects of illegitimate perturbation samples in the feature space. To boost the robustness and trustworthiness of this method for correctly classifying attacked input samples, we regularize the hidden space of a trained model with a discriminative loss function called Polarized Contrastive Loss (PCL). It improves discrimination among samples in different classes and maintains the resemblance of those in the same class. Also, we integrate a DFL and PCL in a compact model for defending against data poisoning attacks. This method is trained and tested using the CIFAR-10 and MNIST datasets with data poisoning-enabled perturbation attacks, with the experimental results revealing its excellent performance compared with those of recent peer techniques.
A Deep Marginal-Contrastive Defense against Adversarial Attacks on 1D Models
Dec 08, 2020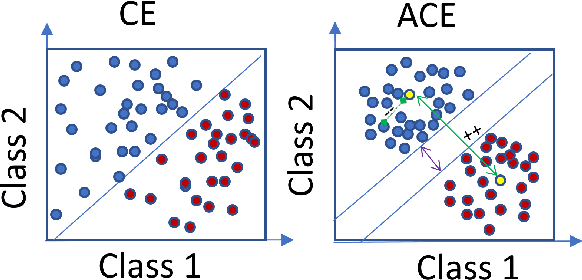
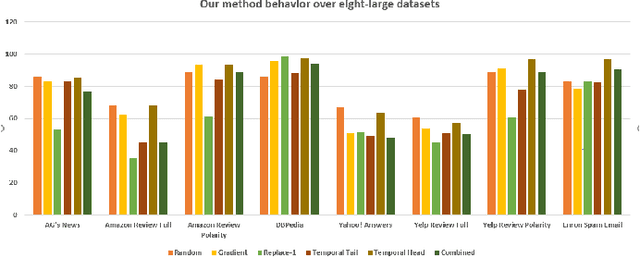
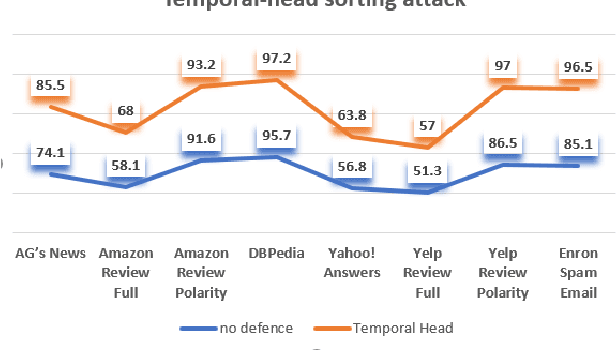
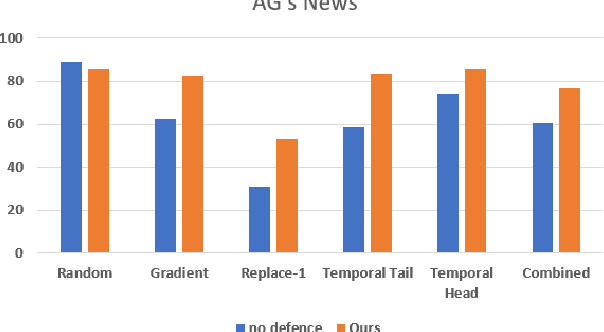
Deep learning algorithms have been recently targeted by attackers due to their vulnerability. Several research studies have been conducted to address this issue and build more robust deep learning models. Non-continuous deep models are still not robust against adversarial, where most of the recent studies have focused on developing attack techniques to evade the learning process of the models. One of the main reasons behind the vulnerability of such models is that a learning classifier is unable to slightly predict perturbed samples. To address this issue, we propose a novel objective/loss function, the so-called marginal contrastive, which enforces the features to lie under a specified margin to facilitate their prediction using deep convolutional networks (i.e., Char-CNN). Extensive experiments have been conducted on continuous cases (e.g., UNSW NB15 dataset) and discrete ones (i.e, eight-large-scale datasets [32]) to prove the effectiveness of the proposed method. The results revealed that the regularization of the learning process based on the proposed loss function can improve the performance of Char-CNN.
Densely Connected Residual Network for Attack Recognition
Aug 05, 2020



High false alarm rate and low detection rate are the major sticking points for unknown threat perception. To address the problems, in the paper, we present a densely connected residual network (Densely-ResNet) for attack recognition. Densely-ResNet is built with several basic residual units, where each of them consists of a series of Conv-GRU subnets by wide connections. Our evaluation shows that Densely-ResNet can accurately discover various unknown threats that appear in edge, fog and cloud layers and simultaneously maintain a much lower false alarm rate than existing algorithms.
Enhancing network forensics with particle swarm and deep learning: The particle deep framework
May 02, 2020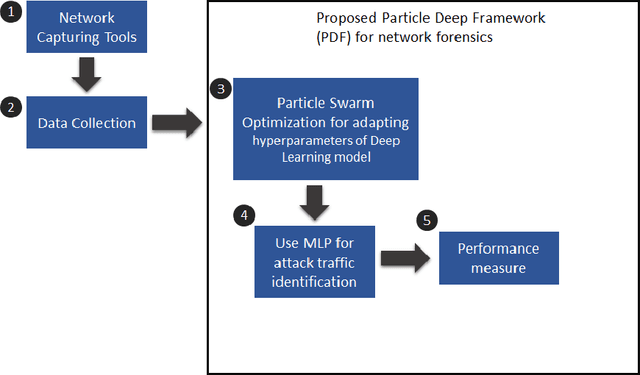

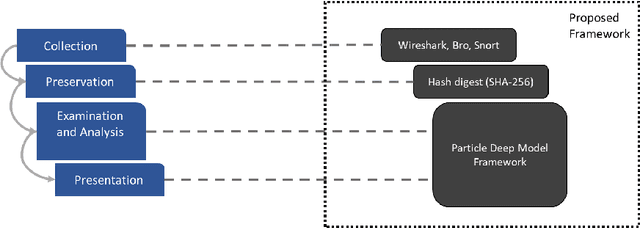

The popularity of IoT smart things is rising, due to the automation they provide and its effects on productivity. However, it has been proven that IoT devices are vulnerable to both well established and new IoT-specific attack vectors. In this paper, we propose the Particle Deep Framework, a new network forensic framework for IoT networks that utilised Particle Swarm Optimisation to tune the hyperparameters of a deep MLP model and improve its performance. The PDF is trained and validated using Bot-IoT dataset, a contemporary network-traffic dataset that combines normal IoT and non-IoT traffic, with well known botnet-related attacks. Through experimentation, we show that the performance of a deep MLP model is vastly improved, achieving an accuracy of 99.9% and false alarm rate of close to 0%.
* 2020/3