 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNN-grams: Unifying neural network and n-gram language models for Speech Recognition
Jun 23, 2016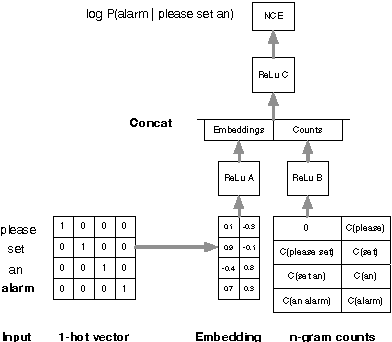

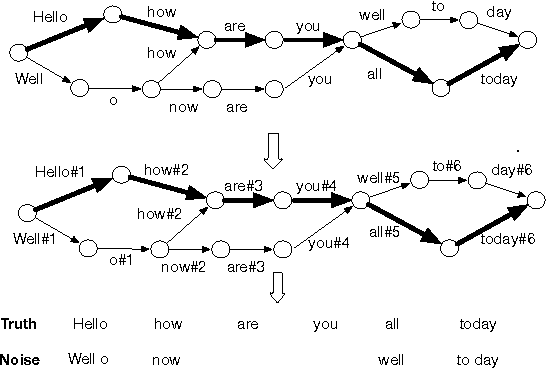

We present NN-grams, a novel, hybrid language model integrating n-grams and neural networks (NN) for speech recognition. The model takes as input both word histories as well as n-gram counts. Thus, it combines the memorization capacity and scalability of an n-gram model with the generalization ability of neural networks. We report experiments where the model is trained on 26B words. NN-grams are efficient at run-time since they do not include an output soft-max layer. The model is trained using noise contrastive estimation (NCE), an approach that transforms the estimation problem of neural networks into one of binary classification between data samples and noise samples. We present results with noise samples derived from either an n-gram distribution or from speech recognition lattices. NN-grams outperforms an n-gram model on an Italian speech recognition dictation task.
Exploring the Limits of Language Modeling
Feb 11, 2016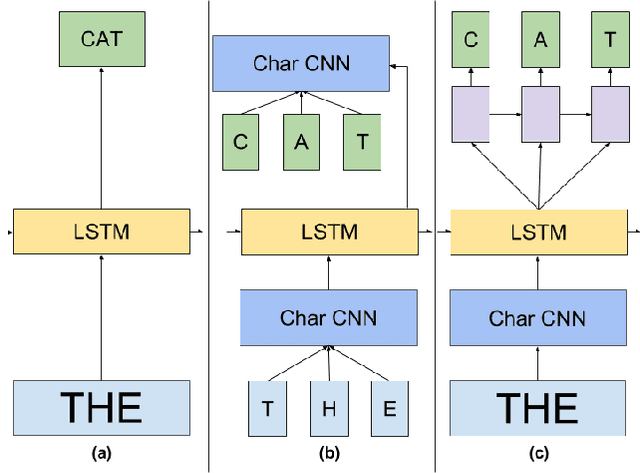
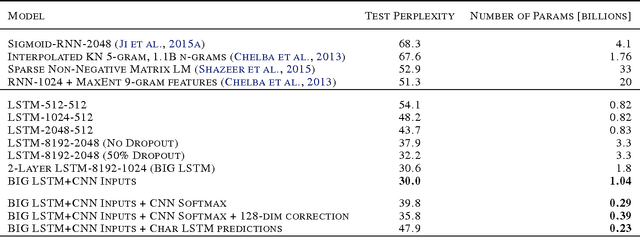
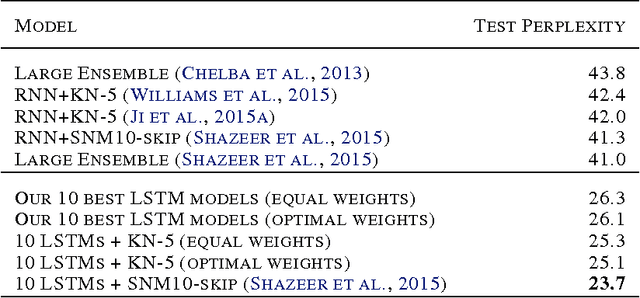
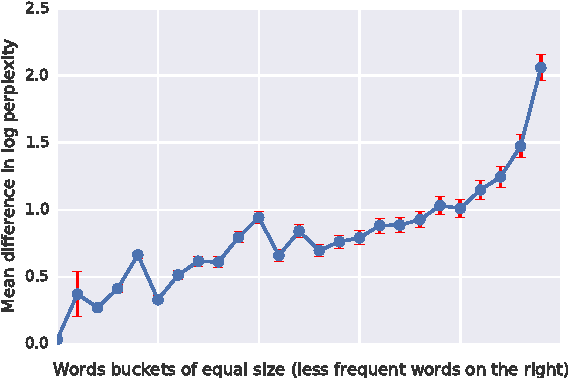
In this work we explore recent advances in Recurrent Neural Networks for large scale Language Modeling, a task central to language understanding. We extend current models to deal with two key challenges present in this task: corpora and vocabulary sizes, and complex, long term structure of language. We perform an exhaustive study on techniques such as character Convolutional Neural Networks or Long-Short Term Memory, on the One Billion Word Benchmark. Our best single model significantly improves state-of-the-art perplexity from 51.3 down to 30.0 (whilst reducing the number of parameters by a factor of 20), while an ensemble of models sets a new record by improving perplexity from 41.0 down to 23.7. We also release these models for the NLP and ML community to study and improve upon.
Swivel: Improving Embeddings by Noticing What's Missing
Feb 06, 2016



We present Submatrix-wise Vector Embedding Learner (Swivel), a method for generating low-dimensional feature embeddings from a feature co-occurrence matrix. Swivel performs approximate factorization of the point-wise mutual information matrix via stochastic gradient descent. It uses a piecewise loss with special handling for unobserved co-occurrences, and thus makes use of all the information in the matrix. While this requires computation proportional to the size of the entire matrix, we make use of vectorized multiplication to process thousands of rows and columns at once to compute millions of predicted values. Furthermore, we partition the matrix into shards in order to parallelize the computation across many nodes. This approach results in more accurate embeddings than can be achieved with methods that consider only observed co-occurrences, and can scale to much larger corpora than can be handled with sampling methods.
End-to-End Text-Dependent Speaker Verification
Sep 27, 2015



In this paper we present a data-driven, integrated approach to speaker verification, which maps a test utterance and a few reference utterances directly to a single score for verification and jointly optimizes the system's components using the same evaluation protocol and metric as at test time. Such an approach will result in simple and efficient systems, requiring little domain-specific knowledge and making few model assumptions. We implement the idea by formulating the problem as a single neural network architecture, including the estimation of a speaker model on only a few utterances, and evaluate it on our internal "Ok Google" benchmark for text-dependent speaker verification. The proposed approach appears to be very effective for big data applications like ours that require highly accurate, easy-to-maintain systems with a small footprint.
Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks
Sep 23, 2015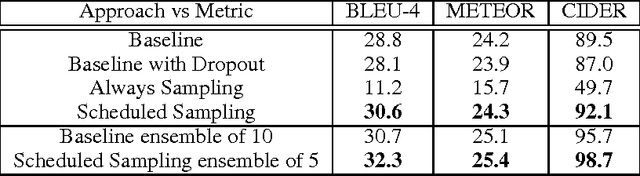
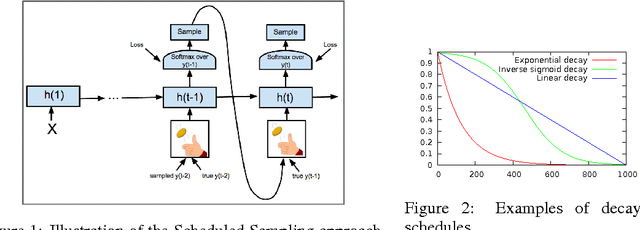

Recurrent Neural Networks can be trained to produce sequences of tokens given some input, as exemplified by recent results in machine translation and image captioning. The current approach to training them consists of maximizing the likelihood of each token in the sequence given the current (recurrent) state and the previous token. At inference, the unknown previous token is then replaced by a token generated by the model itself. This discrepancy between training and inference can yield errors that can accumulate quickly along the generated sequence. We propose a curriculum learning strategy to gently change the training process from a fully guided scheme using the true previous token, towards a less guided scheme which mostly uses the generated token instead. Experiments on several sequence prediction tasks show that this approach yields significant improvements. Moreover, it was used successfully in our winning entry to the MSCOCO image captioning challenge, 2015.
Skip-gram Language Modeling Using Sparse Non-negative Matrix Probability Estimation
Jun 26, 2015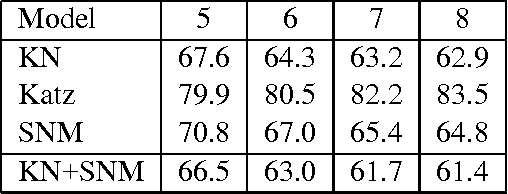

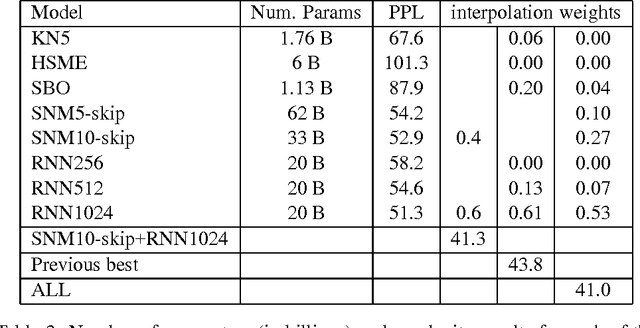

We present a novel family of language model (LM) estimation techniques named Sparse Non-negative Matrix (SNM) estimation. A first set of experiments empirically evaluating it on the One Billion Word Benchmark shows that SNM $n$-gram LMs perform almost as well as the well-established Kneser-Ney (KN) models. When using skip-gram features the models are able to match the state-of-the-art recurrent neural network (RNN) LMs; combining the two modeling techniques yields the best known result on the benchmark. The computational advantages of SNM over both maximum entropy and RNN LM estimation are probably its main strength, promising an approach that has the same flexibility in combining arbitrary features effectively and yet should scale to very large amounts of data as gracefully as $n$-gram LMs do.
Variational Program Inference
Jun 04, 2010We introduce a framework for representing a variety of interesting problems as inference over the execution of probabilistic model programs. We represent a "solution" to such a problem as a guide program which runs alongside the model program and influences the model program's random choices, leading the model program to sample from a different distribution than from its priors. Ideally the guide program influences the model program to sample from the posteriors given the evidence. We show how the KL- divergence between the true posterior distribution and the distribution induced by the guided model program can be efficiently estimated (up to an additive constant) by sampling multiple executions of the guided model program. In addition, we show how to use the guide program as a proposal distribution in importance sampling to statistically prove lower bounds on the probability of the evidence and on the probability of a hypothesis and the evidence. We can use the quotient of these two bounds as an estimate of the conditional probability of the hypothesis given the evidence. We thus turn the inference problem into a heuristic search for better guide programs.