 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Continual Learning for Multilingual Machine Translation via Vocabulary Substitution
Mar 11, 2021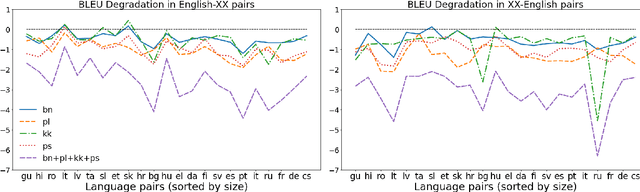
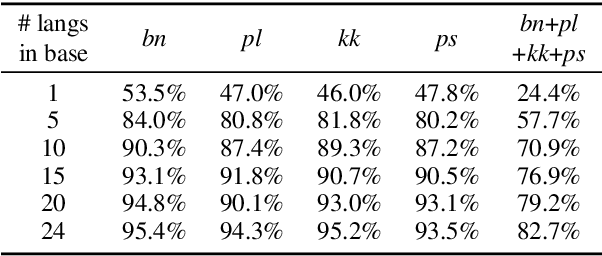
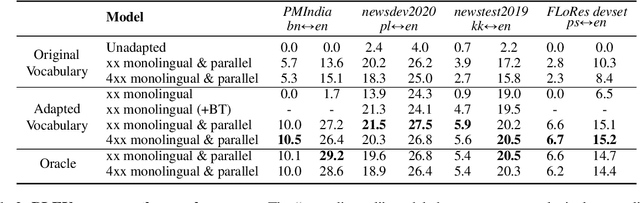
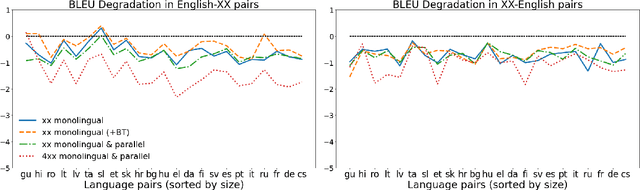
We propose a straightforward vocabulary adaptation scheme to extend the language capacity of multilingual machine translation models, paving the way towards efficient continual learning for multilingual machine translation. Our approach is suitable for large-scale datasets, applies to distant languages with unseen scripts, incurs only minor degradation on the translation performance for the original language pairs and provides competitive performance even in the case where we only possess monolingual data for the new languages.
mT5: A massively multilingual pre-trained text-to-text transformer
Oct 23, 2020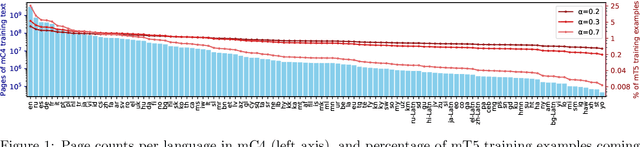

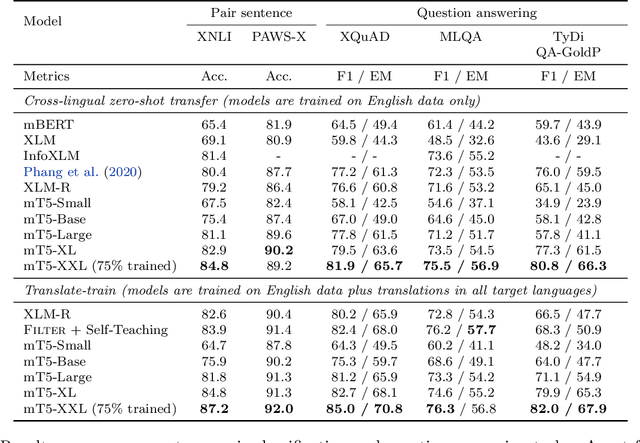
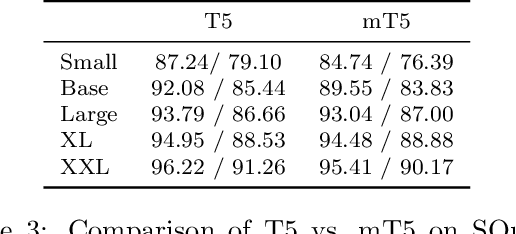
The recent "Text-to-Text Transfer Transformer" (T5) leveraged a unified text-to-text format and scale to attain state-of-the-art results on a wide variety of English-language NLP tasks. In this paper, we introduce mT5, a multilingual variant of T5 that was pre-trained on a new Common Crawl-based dataset covering 101 languages. We describe the design and modified training of mT5 and demonstrate its state-of-the-art performance on many multilingual benchmarks. All of the code and model checkpoints used in this work are publicly available.
Multilingual Synthetic Question and Answer Generation for Cross-Lingual Reading Comprehension
Oct 22, 2020

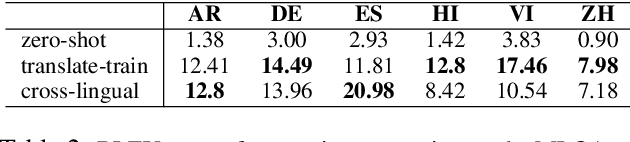

We propose a simple method to generate large amounts of multilingual question and answer pairs by a single generative model. These synthetic samples are then applied to augment the available gold multilingual ones to improve the performance of multilingual QA models on target languages. Our approach only requires existence of automatically translated samples from English to the target domain, thus removing the need for human annotations in the target languages. Experimental results show our proposed approach achieves significant gains in a number of multilingual datasets.
TextSETTR: Label-Free Text Style Extraction and Tunable Targeted Restyling
Oct 08, 2020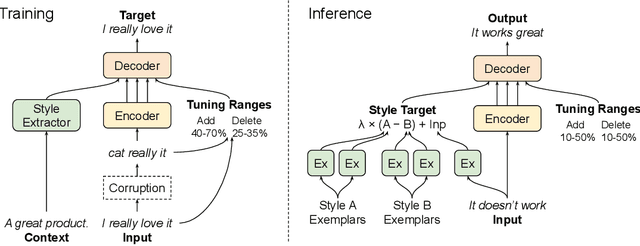
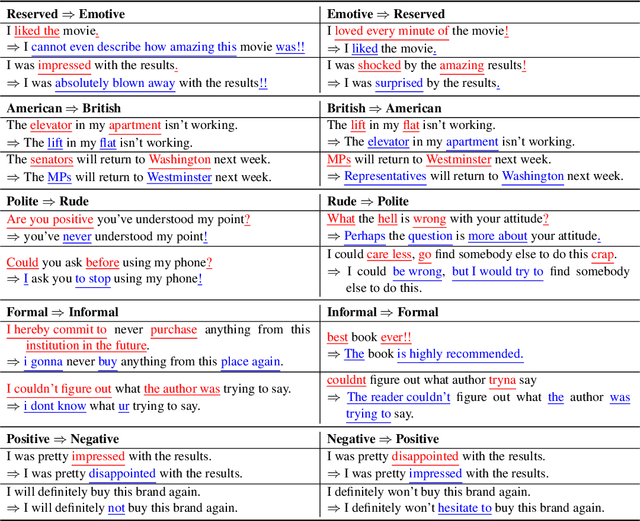
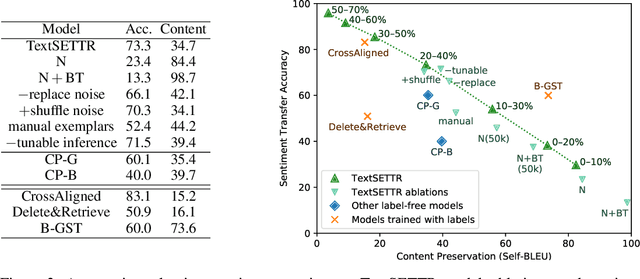

We present a novel approach to the problem of text style transfer. Unlike previous approaches that use parallel or non-parallel labeled data, our technique removes the need for labels entirely, relying instead on the implicit connection in style between adjacent sentences in unlabeled text. We show that T5 (Raffel et al., 2019), a strong pretrained text-to-text model, can be adapted to extract a style vector from arbitrary text and use this vector to condition the decoder to perform style transfer. As the resulting learned style vector space encodes many facets of textual style, we recast transfers as "targeted restyling" vector operations that adjust specific attributes of the input text while preserving others. When trained over unlabeled Amazon reviews data, our resulting TextSETTR model is competitive on sentiment transfer, even when given only four exemplars of each class. Furthermore, we demonstrate that a single model trained on unlabeled Common Crawl data is capable of transferring along multiple dimensions including dialect, emotiveness, formality, politeness, and sentiment.
MultiReQA: A Cross-Domain Evaluation for Retrieval Question Answering Models
May 05, 2020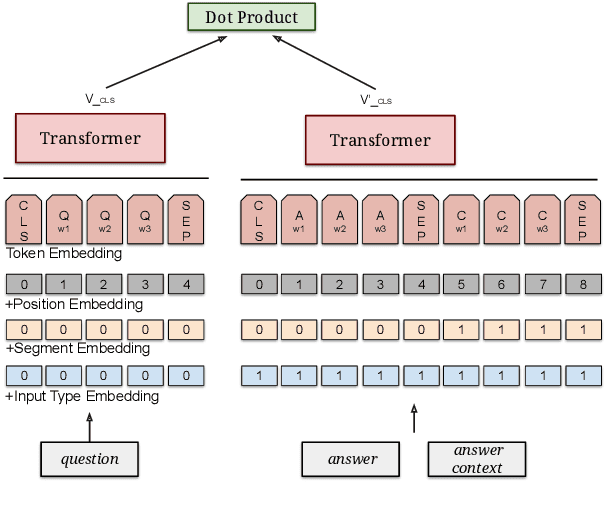

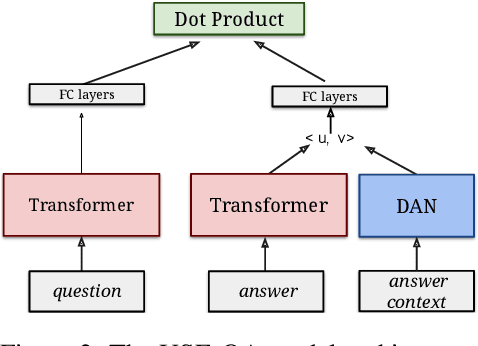
Retrieval question answering (ReQA) is the task of retrieving a sentence-level answer to a question from an open corpus (Ahmad et al.,2019).This paper presents MultiReQA, anew multi-domain ReQA evaluation suite com-posed of eight retrieval QA tasks drawn from publicly available QA datasets. We provide the first systematic retrieval based evaluation over these datasets using two supervised neural models, based on fine-tuning BERT andUSE-QA models respectively, as well as a surprisingly strong information retrieval baseline,BM25. Five of these tasks contain both train-ing and test data, while three contain test data only. Performance on the five tasks with train-ing data shows that while a general model covering all domains is achievable, the best performance is often obtained by training exclusively on in-domain data.
LAReQA: Language-agnostic answer retrieval from a multilingual pool
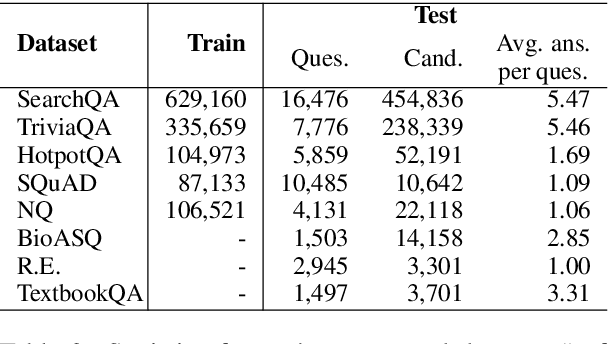
Apr 11, 2020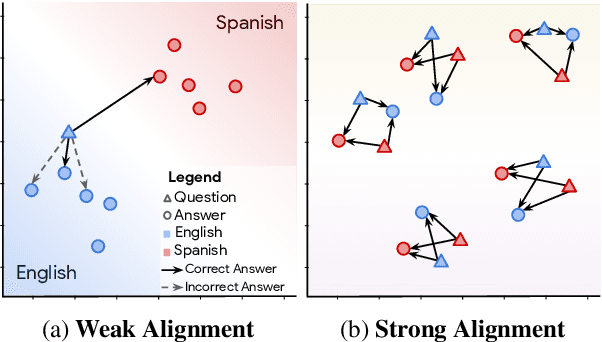
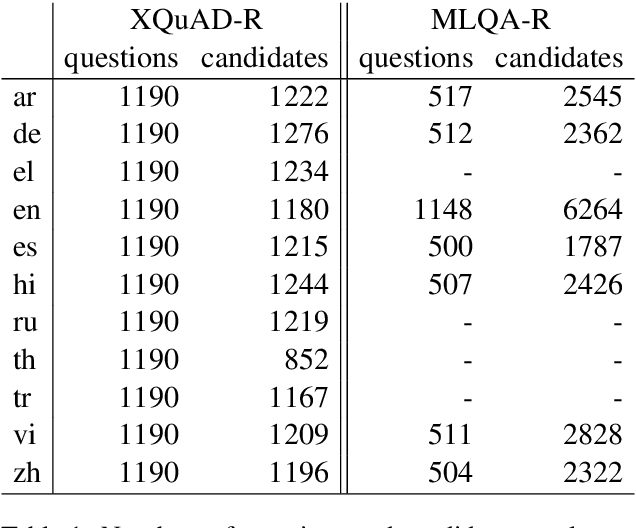
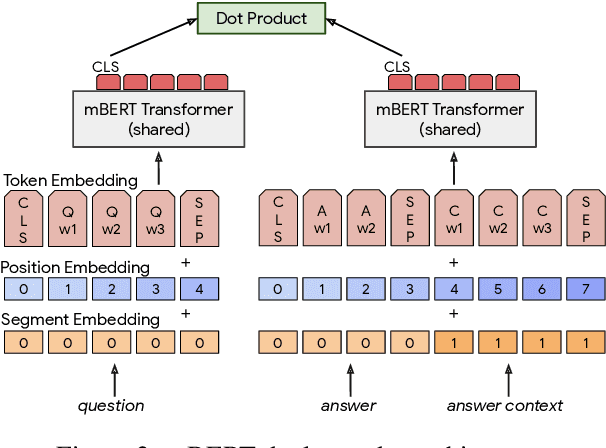
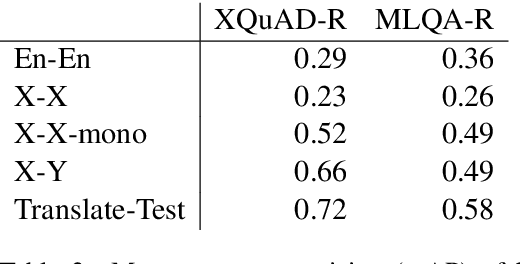
We present LAReQA, a challenging new benchmark for language-agnostic answer retrieval from a multilingual candidate pool. Unlike previous cross-lingual tasks, LAReQA tests for "strong" cross-lingual alignment, requiring semantically related cross-language pairs to be closer in representation space than unrelated same-language pairs. Building on multilingual BERT (mBERT), we study different strategies for achieving strong alignment. We find that augmenting training data via machine translation is effective, and improves significantly over using mBERT out-of-the-box. Interestingly, the embedding baseline that performs the best on LAReQA falls short of competing baselines on zero-shot variants of our task that only target "weak" alignment. This finding underscores our claim that languageagnostic retrieval is a substantively new kind of cross-lingual evaluation.
Bridging the Gap for Tokenizer-Free Language Models
Aug 27, 2019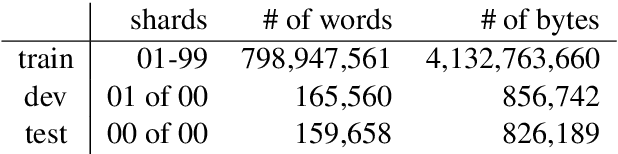
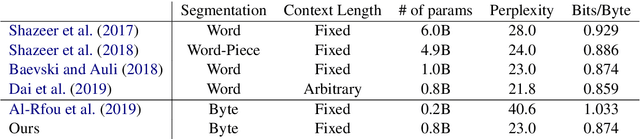
Purely character-based language models (LMs) have been lagging in quality on large scale datasets, and current state-of-the-art LMs rely on word tokenization. It has been assumed that injecting the prior knowledge of a tokenizer into the model is essential to achieving competitive results. In this paper, we show that contrary to this conventional wisdom, tokenizer-free LMs with sufficient capacity can achieve competitive performance on a large scale dataset. We train a vanilla transformer network with 40 self-attention layers on the One Billion Word (lm1b) benchmark and achieve a new state of the art for tokenizer-free LMs, pushing these models to be on par with their word-based counterparts.
ReQA: An Evaluation for End-to-End Answer Retrieval Models
Jul 10, 2019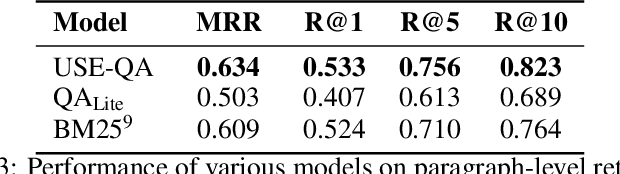
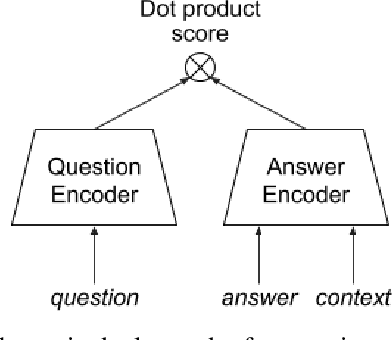
Popular QA benchmarks like SQuAD have driven progress on the task of identifying answer spans within a specific passage, with models now surpassing human performance. However, retrieving relevant answers from a huge corpus of documents is still a challenging problem, and places different requirements on the model architecture. There is growing interest in developing scalable answer retrieval models trained end-to-end, bypassing the typical document retrieval step. In this paper, we introduce Retrieval Question Answering (ReQA), a benchmark for evaluating large-scale sentence- and paragraph-level answer retrieval models. We establish baselines using both neural encoding models as well as classical information retrieval techniques. We release our evaluation code to encourage further work on this challenging task.
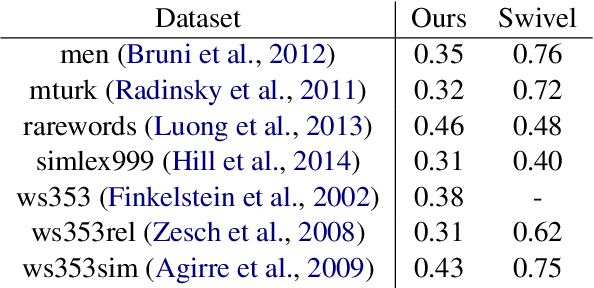
Multilingual Universal Sentence Encoder for Semantic Retrieval
Jul 09, 2019We introduce two pre-trained retrieval focused multilingual sentence encoding models, respectively based on the Transformer and CNN model architectures. The models embed text from 16 languages into a single semantic space using a multi-task trained dual-encoder that learns tied representations using translation based bridge tasks (Chidambaram al., 2018). The models provide performance that is competitive with the state-of-the-art on: semantic retrieval (SR), translation pair bitext retrieval (BR) and retrieval question answering (ReQA). On English transfer learning tasks, our sentence-level embeddings approach, and in some cases exceed, the performance of monolingual, English only, sentence embedding models. Our models are made available for download on TensorFlow Hub.
Character-Level Language Modeling with Deeper Self-Attention
Aug 09, 2018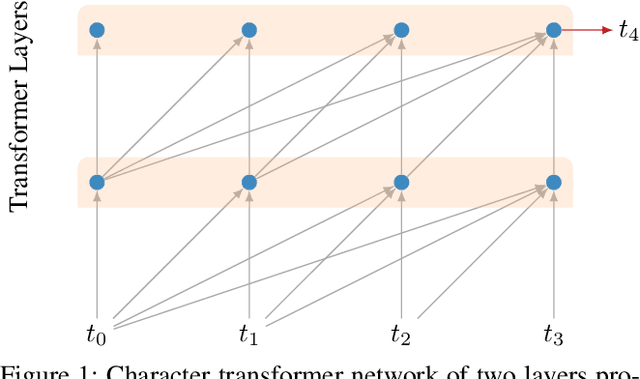
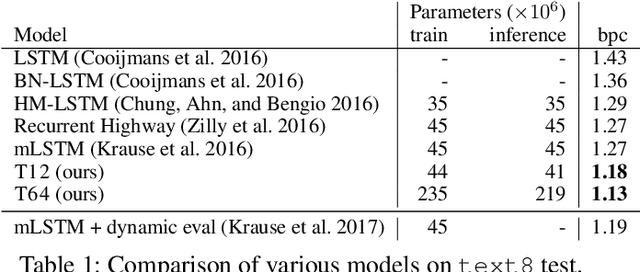
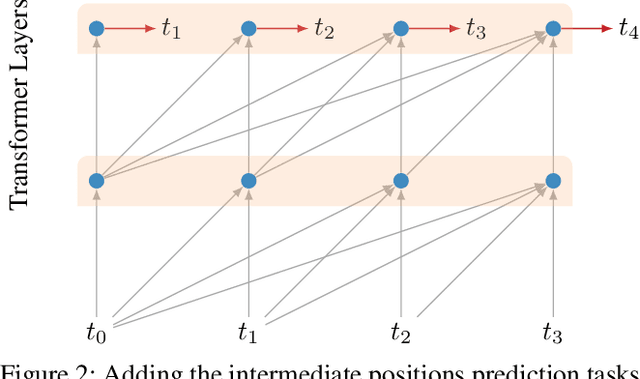
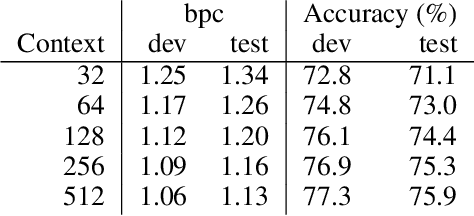
LSTMs and other RNN variants have shown strong performance on character-level language modeling. These models are typically trained using truncated backpropagation through time, and it is common to assume that their success stems from their ability to remember long-term contexts. In this paper, we show that a deep (64-layer) transformer model with fixed context outperforms RNN variants by a large margin, achieving state of the art on two popular benchmarks- 1.13 bits per character on text8 and 1.06 on enwik8. To get good results at this depth, we show that it is important to add auxiliary losses, both at intermediate network layers and intermediate sequence positions.